手把手教你用Sar诊断问题
如今各种高大上的监控工具早已经让人目不暇接了,但是熟悉基础的 Linux 监控命令依然是必要的,就好比 IDE 再好用,我们也得学会 vi 或者 emacs 才行。如果让我选一个必须学会的 Linux 监控命令的话,那么我想我一定会选 sar,没有之一。
监控命令 sar 隶属于 sysstat 包,监控的内容可以说是无所不包,常见的有:
- sar -q:查看 Load
- sar -u:查看 CPU
- sar -r:查看 Memory
- sar -b:查看 IO
除了这些常用的基础用法,还有一些更高级的用法:
- sar -n DEV -f /var/log/sa/sa01:查看本月 1 号的网卡流量情况
- sar -n SOCK -f /var/log/sa/sa01:查看本月 1 号的网络连接情况
缺省情况下,sar 会每 10mins 搜集一次数据,然后保存到「/var/log/sa」里,如果我们想查看历史数据,可以在执行 sar 时通过「-f」参数指定具体的日志文件。不过需要说明的是,每 10mins 一次的采样周期实在有点久,我强烈建议大家改成每 1min 采样一次:
shell> cat /etc/cron.d/sysstat # Run system activity accounting tool every 1 minute * * * * * root /usr/lib64/sa/sa1 1 1 # 0 * * * * root /usr/lib64/sa/sa1 600 6 & # Generate a daily summary of process accounting at 23:53 53 23 * * * root /usr/lib64/sa/sa2 -A
如果你对着文档挨个参数测试,那么很有可能会遇到错误提示:
Requested activities not available in file /var/log/sa/sa…
这是因为 sar 并没有把所有数据都归档保存,所以当你请求无效数据的时候,自然就报错了,好消息是我们可以通过 SADC_OPTIONS 来设置把那些数据归档:
shell> cat /etc/sysconfig/sysstat # sysstat-9.0.4 configuration file. # How long to keep log files (in days). # If value is greater than 28, then log files are kept in # multiple directories, one for each month. HISTORY=28 # Compress (using gzip or bzip2) sa and sar files older than (in days): COMPRESSAFTER=31 # Parameters for the system activity data collector (see sadc manual page) # which are used for the generation of log files. SADC_OPTIONS="-S XALL"
关于 SADC_OPTIONS 的介绍,请参考「man sadc」。本文设置为 XALL,也就是保存一切数据,除非你的硬盘可用空间少得可怜,否则我强烈建议你设置为 XALL。
坏消息是如果仅仅是修改了 SADC_OPTIONS,那么很可能会无效, FAQ :
IMPORTANT NOTE: The list of activities that are saved in a file can no longer be modified once the file has been created. So it is important to use the proper options the first time sadc is called (whether via a crontab, a script like sa1 or even the script used to insert a RESTART message when the machine is rebooted).
当然,我们并不用重启服务器,只要删除 /var/log/sa 下的旧日志即可。
最后,让我们讲解一个实战的例子来作为本文的结尾:sar 可以用来监控各种错误事件,比如通过「sar -n ETCP 1」实时监控 TCP 相关的错误事件:
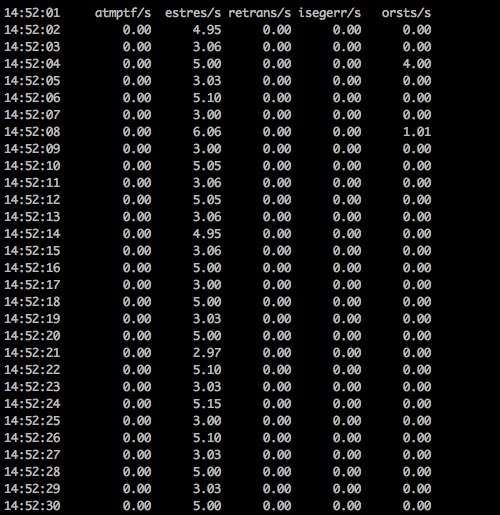
sar -n ETCP 1
如上我们可以发现 estres/s 和 orsts/s 都出现了错误数不为零的情况:
- estres/s: The number of times per second TCP connections have made a direct transition to the CLOSED state from either the ESTABLISHED state or the CLOSE-WAIT state [tcpEstabResets].
- orsts/s: The number of TCP segments sent per second containing the RST flag [tcpOutRsts].
说明:关于 estres/s 和 orsts/s 介绍中结尾出现的 tcpEstabResets 和 tcpOutRsts 源自何处?你可以参考「nstat -z | grep -iE ‘tcpEstabResets|tcpOutRsts’」。
两者都是关于 RESET 的数据,区别是:estres/s 指的是每秒收到的 RESET 数量;orsts/s 指的是发出的 RESET 数量。从数据上看 estres/s 的问题更严重,几乎无时无刻都在不停的收到 RESET,为了探明究竟,我们用 tcpdump 抓包,然后用 wireshark 查看:
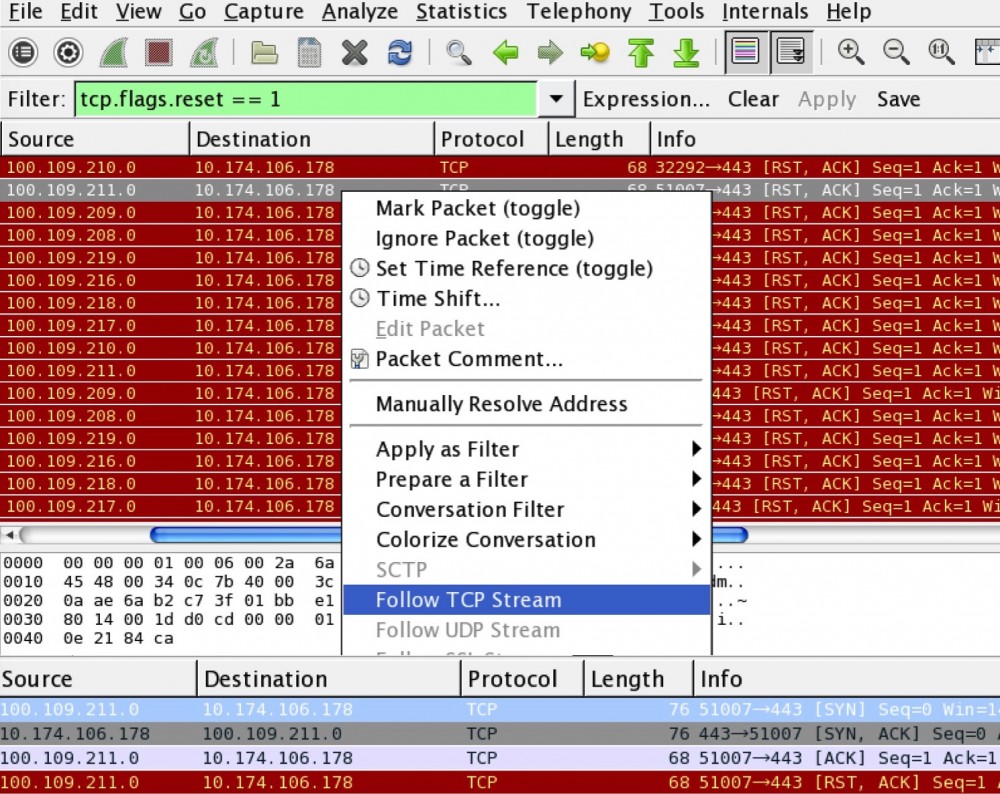
Wireshark
通过「tcp.flags.reset == 1」语法我们能筛选出所有的 RESET 包,然后在鼠标右键菜单里选择「Follow TCP Stream」就可以跟踪一个具体的 TCP 会话,如图片下方所示,对方在和我方进行了 TCP 三次握手之后,直接就 RESET 了!
实际上,问题分析到这里,我们已经找到了 estres/s 的源头了,不过对方为什么要发送这么多 RESET?说起来这是一台阿里云的服务器,在配置负债均衡的时候错误的选择了 TCP 监控的方式,而阿里云的 TCP 监控本身又 DDoS 般粗野:一大堆请求通过三次握手确认端口是否存活,然后并没有通过正常的四次握手关闭连接,而是直接通过 RESET 关闭连接。至于为什么阿里云如此选择?我猜可能它不想出现 TIME_WAIT 吧,呵呵!
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

