使用K-Means算法对数据进行聚类
K-Means是聚类算法的一种,以距离来判断数据点间的相似度并对数据进行聚类。前面的文章中我们介绍过K-Means聚类算法的原理及实现。本篇文章使用scikit-learn库对数据进行聚类分析。

准备工作
开始之前先导入要使用的各种库文件,首先是scikit-learn库,然后是数值计算numpy和科学计算pandas库,以及用于绘制图表的matplotlib库文件。
</pre> from sklearn.cluster import KMeans import numpy as np import pandas as pd import matplotlib.pyplot as plt <pre>
读取并查看数据表
读取用于聚类的数据并创建名为loan_data的数据表,用于后续的聚类分析。
</pre>
#读取用于聚类的数据,并创建数据表
loan_data=pd.DataFrame(pd.read_csv('loan_data.csv',header=0))
<pre>
</pre> #查看数据表 loan_data.head() <pre>

</pre> #查看表中的各列的名称 loan_data.columns Index(['member_id', 'loan_amnt', 'term', 'grade', 'emp_length', 'annual_inc', 'issue_d', 'loan_status', 'total_pymnt_inv', 'total_rec_int'], dtype='object') <pre>
我们对数据表中的贷款金额和用户年收入进行聚类,这里先绘制两个维度的散点图,观察分布情况并与后续的聚类结果进行对比。
</pre>
#绘制散点图
plt.rc('font', family='STXihei', size=10)
plt.scatter(loan_data['loan_amnt'],loan_data['annual_inc'],50,color='blue',marker='+',linewidth=2,alpha=0.8)
plt.xlabel('贷款金额')
plt.ylabel('年收入')
plt.xlim(0,25000)
plt.grid(color='#95a5a6',linestyle='--', linewidth=1,axis='both',alpha=0.4)
plt.show()
<pre>
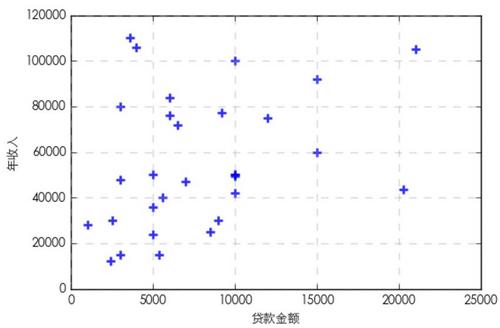
K-Means聚类
我们数据表中的贷款金额和用户年收入两个维度进行聚类,这里先对数据进行预处理,然后设置类别数量。
</pre> #设置要进行聚类的字段 loan = np.array(loan_data[['loan_amnt','annual_inc']]) #设置类别为3 clf=KMeans(n_clusters=3) #将数据代入到聚类模型中 clf=clf.fit(loan) <pre>
聚类结果将数据分析三类,第一类的均值是贷款金额8754,年收入88853。第二类的均值是贷款金额4596,年收入22406。第三类的均值是贷款金额9168,年收入46870。换个角度来看,第一个类的用户属于贷款金额高,年收入也较高的一群人。第二个类别的用户属于贷款金额较低,年收入也较低的一群人。第三个类别的用户则属于贷款金额高,年收入居中的一群人。
</pre> #查看聚类结果 clf.cluster_centers_ array([[ 8754.54545455, 88853.19909091], [ 4596.875 , 22406.5 ], [ 9168.18181818, 46870.72727273]]) <pre>
假设这时我们又有了新的用户数据输入,在原有聚类模型中,新数据贷款金额7000,年收入30000,被分为了第三个类别,贷款金额高,年收入居中的类别。
</pre> #测试新数据聚类结果 clf.predict(['7000','30000']) array([2]) <pre>
将K-Means模型对原始数据聚类的结果标记在原始数据表中。
</pre> #在原始数据表中增加聚类结果标签 loan_data['label']=clf.labels_ <pre>
查看标记聚类结果的数据表,其中label字段为聚类结果。
</pre> #查看数据表 loan_data.head() <pre>
为了更加清晰和直观的查看原始数据的聚类结果,我们将聚类结果绘制成散点图,以三种不同颜色标记不同的类别的数据点。
</pre> #提取不同类别的数据 loan_data0=loan_data.loc[loan_data["label"] == 0] loan_data1=loan_data.loc[loan_data["label"] == 1] loan_data2=loan_data.loc[loan_data["label"] == 2] <pre>
</pre>
#绘制聚类结果的散点图
plt.rc('font', family='STXihei', size=10)
plt.scatter(loan_data0['loan_amnt'],loan_data0['annual_inc'],50,color='#99CC01',marker='+',linewidth=2,alpha=0.8)
plt.scatter(loan_data1['loan_amnt'],loan_data1['annual_inc'],50,color='#FE0000',marker='+',linewidth=2,alpha=0.8)
plt.scatter(loan_data2['loan_amnt'],loan_data2['annual_inc'],50,color='#0000FE',marker='+',linewidth=2,alpha=0.8)
plt.xlabel('贷款金额')
plt.ylabel('年收入')
plt.xlim(0,25000)
plt.grid(color='#95a5a6',linestyle='--', linewidth=1,axis='both',alpha=0.4)
plt.show()
<pre>
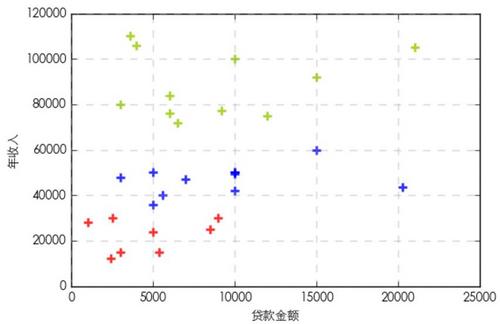
绿色表示第一个类别的用户属于贷款金额居中,年收入较高的一群人。红色第二个类别的用户属于贷款金额较低,年收入也较低的一群人。蓝色表示第三个类别的用户则属于贷款金额高,年收入居中的一群人。
—【所有文章及图片版权归 蓝鲸(王彦平)所有。欢迎转载,但请注明转自“蓝鲸网站分析博客”。】—
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

