Yann LeCun连发三弹:人人都懂的深度学习基本原理(附视频)
一名 AI 专家值多少钱?
“基于我个人经验,一名计算机领域的 AI 专家对于企业的价值, 至少为 500-1000 万美元 。为了争夺这些少数的人才,正在开展竞标大战。”
这是卡耐基梅隆大学计算机科学院院长 Andrew Moore 教授在 11 月 30 日美国参议院听证会上 ,所说的话。

这场听证会名为 “AI 破晓” (The Dawn of Artificial Intelligence),由参议员泰德·科鲁兹主持,主题是探讨人工智能当前的形势,对政策的影响及其对商业形态的改变。共有 5 位 AI 专家出席,分别是:
-
Eric Horvitz(微软研究实验室总经理,人工智能伙伴关系委员会临时共同主席)
-
Andrew Moore(卡耐基梅隆大学计算机科学院院长)
-
Andrew Futreal(德州大学安德森癌症中心基因医学教授)
-
Greg Brockman(OpenAI CTO及其联合创始人)
-
Steve Chien(加州理工学院、NASA 喷气推进实验室高级研究科学家)
在 Moore 教授看来, 美国政府应该从高中阶段开始为人工智能产业积蓄研究人员了,而这个人才储备需求为 100 万名高中生 。这并不是 Moore 教授一个人的观点,吴恩达也表示赞同。
无独有偶,仅隔一天,Facebook 的博客上发布了一条新消息,放出大神 Yann LeCun 亲自讲解 AI 知识的三弹视频。然而如果 AI 领域的专业读者,稍微点开视频一看,便知道这好像是一个高中老师在讲科普课的风格。
三弹视频凑成一个系列,风格十分活泼,Yann LeCun 的讲解里穿插动画,并没有太多技术性的内容。LeCun 在视频里就明确表示, 这次主要是给大众普及关于深度学习的基本原理,希望可以鼓励年轻人、高中生对该领域有更多了解,激发他们来探索这一领域的兴趣。

所以这样看来,无论是美国的学术界、政府还是产业界,都普遍有一种要把 AI 的种子广泛播种到下一代的氛围。
虽然是科普性的视频,但大神的思路可见一斑。就像 Moore 教授所说的,真正的 AI 专家只是非常少的一波群体,其实如今的 AI 从业者仍旧处在一个“学习”阶段。
那么,到底 Yann LeCun 的三弹视频里讲了什么内容呢?
雷锋网根据 Yann LeCun 讲解总结成下文,供读者参阅,底部更是附上原英文视频。(另外在几天前,雷锋网 (公众号:雷锋网) 整理了 Yann LeCun 教授在 Quora 上关于“如何自学深度学习技术”的回答,非常具有可操作性,感兴趣的读者可移步: 大神Yann LeCun亲授:如何自学深度学习技术并少走弯路 )
监督学习最常用,关键是“调参”
很多人,对于智能机器非常着迷,而我们的实现方法其实非常简单。现在我跟大家解释一下它当中到底是如何工作的。
其实大部分人已经在日常生活中使用 AI 系统了,只不过他们都不知道而已,这里面的应用包括自动驾驶、购买建议、游戏等。
我们最常用的机器训练模型,就是监督学习(Supervised learning)。
举一个典型的例子,如果你想建造一个识别图像的机器,让它识别图像里的狗和汽车。那么你就需要给这个机器看几百万张含有狗和汽车的图片,并告诉机器里面是否有狗或汽车,这就是一个“训练”的过程。
在训练之前,这个机器只是产生随机的答案,当你给它显示一张汽车或狗的图片时,你都不知道它会怎么回答。如果它答对了,可能只是运气好罢了;如它答错了,这时候得人为纠正一下(调参数)。
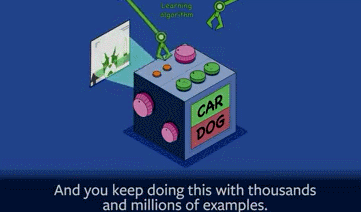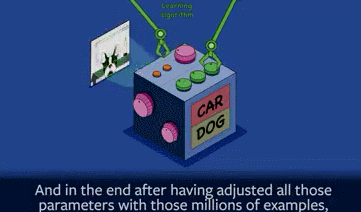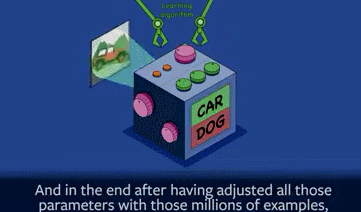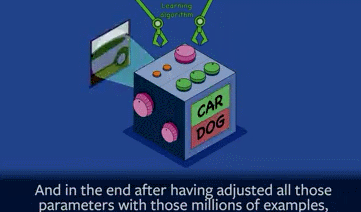
所以其中的一个关键就是,首先就是建造一个机器系统,然后就是调整内部参数或者结构,这样下一次你再展示图片的时候,系统就会答出正确答案了。
这就所谓的“学习型算法”,其关键就是在于“调整参数”。几百万张图片这样训练下来,不断地调整参数,最终机器会弄清楚“汽车”和“狗”之间的区别。当一张全新的照片给机器看时,它这时多半会给出正确答案。
我们把这个过程称为“泛化能力”(Generalization ability),指的是,机器能够识别出跟训练素材相似的,但从未见过的东西(The ability to recognize things that are similar to what the machine has been trained on but has never seen)。
机器学习,用模板来进行图像识别
计算机往往依照一串指令来运行,这一串指令就叫做“算法”(Algorithm)。清洗盘子,也是要遵循“算法”的:先从一摞盘子里选出一个放入水池中,然后擦拭清洗,然后烘干,最后放置在架子上。这个过程不断重复,就是一种很简单的“算法”。

那么我们如何为图像识别写一个“算法”呢?比如,如何区别图像里的汽车和狗?
计算机通常采用的方法,是用数字来表示图片,每一个数字代表特定区域像素的亮度。汽车的像素数组和狗的像素数组如图,这样就可以写一段代码来区别汽车和狗。
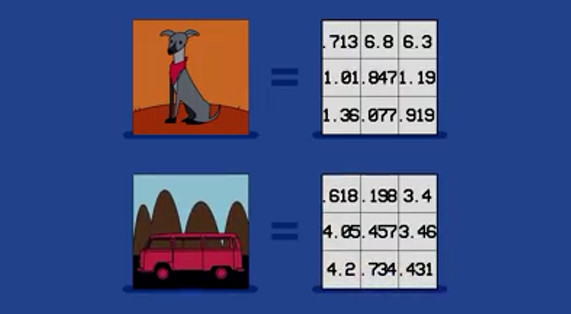
很多年来我们做的事情,就是建立大量的图片库,将已识别出的图像和等待识别的图像进行比较,如果匹配上时,计算机就可以判定图片里面到底是汽车还是狗。
但问题是,这个方法所需要的模板数量太巨大了,就汽车和狗而言,需要所有可能的位置、颜色、姿态的狗和汽车,这是非常不实际的。
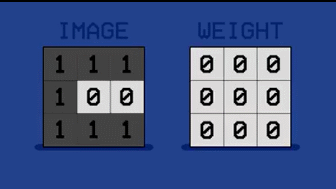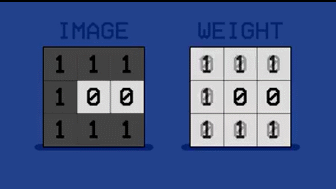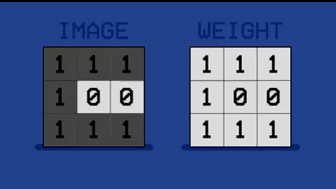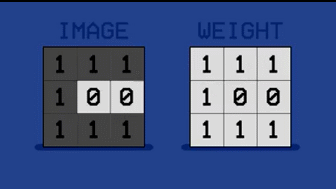
但机器学习不一样,我们并不对机器进行编程,而是用图片对其进行训练。我们来举个最简单的例子,让机器区分两个字母。我们看到下图里,分别是字母 D 和字母 C(黑色块构成字母轮廓)。 
每张图片包含 9(3*3)个像素,我们分别给像素赋值,黑色=1,白色=0,从而得到两张字母图片的像素矩阵。
接着,我们只让系统做一件很简单的事情:计算出像素权重(Weights)之和。

具体而言,我们需要两个部分: 像素值矩阵和权重模板,让这二者相乘得出结果。我们假定,如果结果>0,即判定为字母 C,如结果<0,即判定为字母D。
像素值矩阵很好设定,接下来就是得出一个有效的区分二者的权重模板,这是通过人工调节得到的。
当看到字母 C 时,人工告诉机器把 C 的权值调大。于是学习系统把字母 C 黑色像素对应的模板的权值增加为 1,白色像素对应的部分保持为 0。
同时将字母 D 的权值调小。
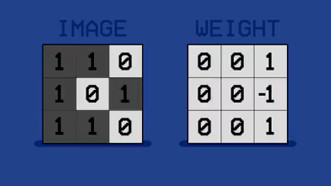
最终得到的模板权值中,正数(1)位置独属于字母C,负数(-1)位置独属于字母D。这就是一个很完美的将字母 C 和字母 D 区分的模板。

现在我们重新给系统一个字母C 的图片,计算机将新图与终极模板相乘,得到的 9个像素里的值,这些值相加得到的值=2。这时,2>0,所以计算机判断其为字母 C。
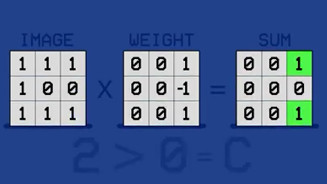
同样,如果新图是字母D,那么所得结果为-1,-1<0,所以计算机判断其为字母D。

现实中的分类问题要比区别字母 C 和字母 D 更费时、更复杂,而对模板的设定也更具有挑战,但是模板法是一种非常基础的原理。
深度学习新方法:卷积神经网络
在深度学习领域,我们使用一种特殊的方法:卷积神经网络(Convolutional Neural Network, CNN) 。有趣的是,这种网络结构,是受到哺乳动物的视觉皮层启发。
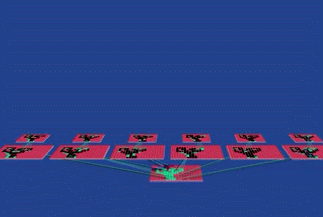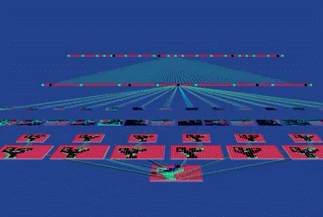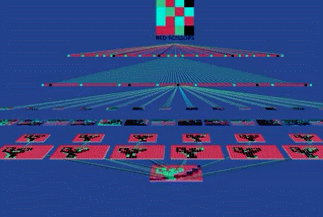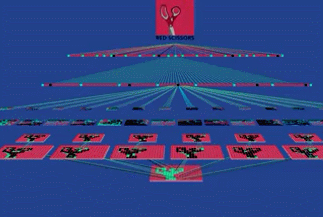
一个物体可以有多个角度的照片,比如我要给这个剪刀拍照,各个角度得到的图片是不一样的。

如果我要让计算机识别出这个剪刀,那么就要以这个洞为主要特征,无论剪刀出现在照片的哪个位置,系统都能依据这个“洞”找出这个剪刀。

这个“洞”只是这个剪刀的特征之一,我们可以对一个物体提取多个特征,让系统来锁定它。CNN 的特殊之处在于,我们并不需要人工来提取这些“特征”。CNN 的第一层,有几百个探测器(Detectors),它们自己学习并提取出几百个“特征”。
这种自我学习的方法,应用在很多领域,包括图像识别、自动驾驶、语音识别、翻译等。
Yann LeCun 表示:
这个视频不是课程,只是让普通人能够真正理解“深度学习”技术背后的基本原理,这或许能够鼓励年轻人、高中生对此有更丰富的了解,让他们对此产生兴趣,之后或许能在网上听一些课程,甚至日后在大学里学习相关课程。
我认为,让公众对深度学习技术有所了解,是很重要的。
所以,Facebook 已经要在培养青少年人才方面发力了,雷锋网大胆推测,莫非明年就要出现深度学习技术的高中生竞赛了?
从政界、学术界到产业界,美国都在向着“AI 破晓”大胆迈步,中国其实不乏在 AI 领域的专家大牛,是否也有一天,向 Yann LeCun 一样亲切地向大众普及 AI 知识,推动基础教育的发展呢?
PS: Yann LeCun三弹视频。
相关文章:
AI的自我重塑?看看Google、Facebook这些大公司都在做的事
雷锋网原创文章,未经授权禁止转载。详情见 转载须知 。

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

