Python实现网页解析翻译
先不说主流的几款提供翻译接口的产品在翻译的水准上如何,就HTML标签识别来说,度娘恐怕没有谷歌和必应做的好。
0x01 需求
最近需要写程序翻译一批英文网页,要求翻译后的网页排版样式基本不变。经过前期测试发现,Google和Bing的在线翻译可以直接识别出HTML的标签:
类似这样,看起来很舒心~~:
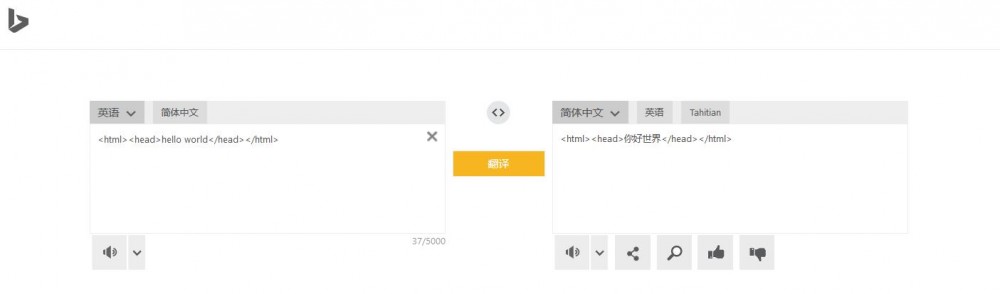
换做度娘,Oh~:
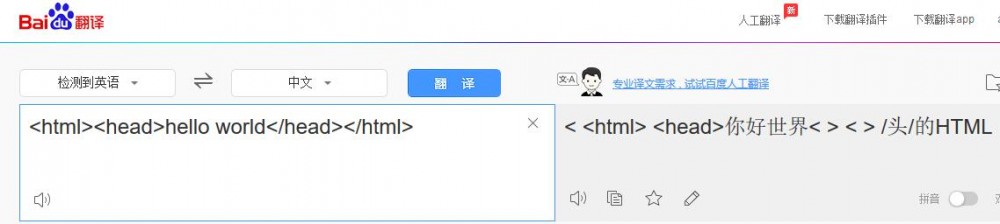
本以为是因为度娘没有做网页翻译插件的打算,所以没这个功能,但是查证后发现——其实百度是支持网页翻译的——也就是理论上应该可以识别网页标签,也许是我的姿势不对 (O.O)_? 求证大家的操作心得。
总之,在正常的百度翻译API调用下无法实现很好的解析翻译网页,而能够实现这一功能的另两位也有客观上的难度,Google就不用说了,如果要调用就需要在程序上挂一个代理;那么,Bing这厮呢?要申请它的API过程太繁琐,一是大陆这边好像这项服务选项为空,另外通过其他手段拿到的好像也是试用key。最终,决定自己写个中间件,处理标签后送入百度,拿到翻译结果再重组标签。
0x02 框架
决定自己写处理程序后面临两种选择,一种是一个网页每对闭合标签调用一次API,另一种是一个网页一次性全部翻译后再分割。
两种方法的不同之处在于,前者实现简单,但是每个网页多次调用API增加时间开销且浪费API调用次数,所以使用第二种方式实现。
预期结构如下:
读取网页 ——> 剔除标签,生成文本&标签数组 ——> 数组文本翻译
|
/ /
翻译完成 <—— 标签数组,文本数组组合 <—— 结果重分割数组
- 剔除标签,生成文本标签数组。
Python下有很多好用的HTML解析包,例如BS4,lxml,xpath等等,但是它们的封装都很高级,这里我只需要最简单的识别出标签和文本,所以使用代码更简单的HTMLParser来实现。
HTMLParser是一个基于正则匹配的解析包,它写好了HTML的正则规则,提供了一个类给使用者继承,个人觉得包本身的核心是它的 goahead 函数,利用这种步步识别的方法来解析HTML。
继承的类中,重写了如下方法:
def handle_starttag(self, tag, attrs):
attr = ''
for i in attrs:
attr = i[0]+'='+i[1] # 恢复标签属性值
if attr == '':
self.parser_dic.append('<'+tag+'>')
else:
self.parser_dic.append('<'+tag+' '+attr+'>')
def handle_endtag(self, tag):
self.parser_dic.append('</'+tag+'>')
def handle_startendtag(self, tag, attrs):
attr = ''
for i in attrs:
attr = i[0]+'='+'"'+i[1]+'"'
if attr == '':
self.parser_dic.append('<'+tag+'>')
else:
self.parser_dic.append('<'+tag+' '+attr+'>')
def handle_data(self, data):
self.parser_dic.append(data)
def handle_comment(self, data):
self.parser_dic.append('<!-- -->')
def handle_entityref(self, name):
self.parser_dic.append('&'+name+';')
def handle_charref(self, name):
self.parser_dic.append('&#'+name+';')
def output(self):
return self.parser_dic
通过调用父类中的 feed 方法来解析网页,解析结果输出成为一个按照顺序排列的标签和文本混合的数组。
遍历数组,提取文本数组,遍历文本数组,添加分割符,组合成一个含有分隔符的文本。
混合数组如下:

添加分割符如下:
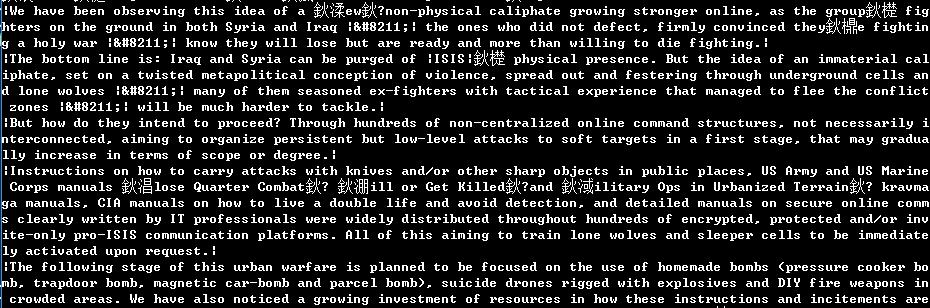
2.数组翻译
直接将含有分隔符的文本按照百度API调用规则发送,这个不需要多说。
3.结果重分割
使用文本自带的 split 或者正则的对应函数分割之前的分隔符,形成文本数组
4.标签重组
这一部分就是重新遍历之前的标签文本混合数组,遇见非标签的内容,就用翻译后的文本数组替换,这样依次替换完成就可以实现保留标签的文本翻译。
0x03 问题
实际操作绝大多数情况下是可行的。
但是也有些问题,一是百度API一次翻译的字数有限,这就意味着,还需要做文本分割,而分割时又要考虑标签的完整性。二是分割符的选择,分隔符有时候也会引起翻译结果的混乱,初步测试使用“|”相对效果较好,后期可能使用多个分割符来防止分割符和文本本身符号混淆。
最后放一张整个完成后的翻译效果图

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

