微店分布式监控系统实践
为什么我们要造一套轮子
早期我们和很多公司一样使用的是zabbix监控, 应该说zabbix的功能还是蛮强大的。但是随着公司的业务发展,我们很快发现有很多问题zabbix很难解决。
问题主要提现在几个方面:第一,协作的问题,zabbix界面设计非常晦涩难懂,更多是站在运维的角度设计,和时下流行的devops理念显得格格不入,我们希望开发能更多参与进来,而现状是只有运维在配置 zabbix;第二,随着服务化的推进,调用关系越来越复杂,问题诊断定位也越来越困难,光报警出来还不够,还要能够快速的定位问题根源;第三,配置繁琐,配置一些简单的系统指标问题还不大,但在虚拟化、容器、服务化等理念深入人心的现在,监控指标开始呈爆炸式的增长,配置zabbix不但需要较高的水平,更需要坚韧的毅力。
基于以上问题,刚开始我们围绕着zabbix并结合cmdb的服务树做了一些二次开发,但还是慢慢发现越来越感到力不从心,而且也满足不了我们的需求,所以我们决定做一个我们自己的监控系统。
如何将监控系统落地
zabbix虽然并不好用,但功能非常强大,涵盖了大部分的监控需求,在短期内我们难以造一个轮子完全取代zabbix,而且闭门造轮子,不快速上线快速试错,我们很难真正将这个轮子造好。
我们在规划新的监控系统之初,有一个共识,觉得大多数问题都是能通过日志记录下来,并可以通过日志监控去发现,所以首先搞定对日志的监控就能覆盖绝大多数的监控场景,这块恰恰又是zabbix在devops理念下薄弱的地方。在搞定日志监控后,再去完善zabbix 已有的功能就能从线上慢慢移除对于zabbix的依赖。
项目从16年4月份开始写下第一行代码,到现在历时半年多,经历了多个重大版本的迭代,从最开始简单的日志处理系统逐渐成长为一个覆盖各种场景的全功能监控系统,将上百个服务都纳入监控范畴,系统指标超过10W个,日志指标超过1万个,报警也超过了万次。 这个发展历程也非常符合我们当初对于监控系统的定位。
现有的功能点
操作维护简单
-
按照产品树组织的dashboard,查看和配置更加容易,开发和运维都可以操作。
-
与cmdb结合,不需要额外维护应用,机器,人员,角色信息。
-
agent节点自发现,自动推送任务。
-
支持监控任务自发现。
-
支持自定监控模板和自发现模板。
监控指标类型
-
应用监控支持外部方式监控日志,也支持java应用通过 sdk 生成指标。
-
jvm 监控。
-
大部分常用的系统监控指标。
-
http/https 方式监控,特别的是支持了text,xpath,jsonpath方式解析响应体。
日志监控
-
支持对日志的字段解析和多种指标聚合方式。
-
支持日志的实时采集,不再需要额外手动部署flume或者logstash,方便与kafka,elk生态打通。
报警及诊断
-
同时支持多种报警方式(邮件、短信、微信、电话)。
-
指标报警、日志异常、调用链跟踪三者关联,快速定位问题。
架构设计
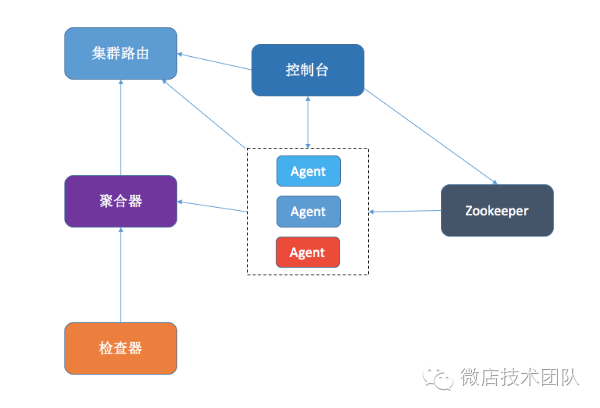
存储层:我们利用graphite(carbon,whisper) 来存储我们的时序数据,利用 mysql 来存储任务信息和少量需要分析的异常日志。
集群路由:我们设计了一个单独的路由器,用于切割集群成为不同的集群,例如测试集群、预发集群和线上集群,路由器也方便我们设计无状态的组件,每个组件不需要附带任何信息,只需要启动的时候访问路由器便能知道自己属于哪个集群。
zookeeper:我们依赖zookeeper 来实现服务发现和集群选主的功能。
设计理念
日志:在设计整个监控的时候,我们的架构都围绕着日志而设计,我们关心如何处理日志,如何提取日志中的指标,如何对指标作聚合,如何报警,报警之后如何提炼出日志的关键词。应用异常、业务数据、性能指标甚至内核参数都能从日志中着手监控,围绕着日志,我们已经能覆盖 80% 的监控场景。
服务化:作为服务化治理的工具,监控系统本身也应该服务化,我们将控制台、聚合器、检查器等重要组件都设计成独立的服务,这方便了日后的开发和维护,同时当我们想加功能的时候,也可以将新功能作为一个独立的服务加入到整个系统里,不破坏原有的功能模块。
高可用和自监控:监控系统作为独立的系统,也需要能够对自身做监控,例如对于各个组件做健康检查,每个组件在设计部署的时候也要考虑到高可用的问题,不能存在单点的问题。
我们趟过的河
1. 如何提取日志的指标
我们为日志设计了一套正则处理机制,将日志中的指标分为几种类型:
-
Count 指标,只要被正则匹配,就为该指标加一,这是最常用的类型,对于 exception 等关键字非常有用。
-
Max/Min/Avg 类型,在一段时间(通常为一分钟)范围内,统计某个浮点型的数据的最大值,最小值或平均值,对于监控例如 sql 语句的慢查询非常有效。
-
Map 类型,可以累加 Count/Max/Min/Avg 等类型,对于不确定指标 Key 的情况,利用 Map 可以自动产生指标名称,利用在日志里出现又被正则命中的关键字作为 Key。
例如我们做异常监控,可以将 Exception 作为关键字,选择 Count 类型,每当出现 Exception, log.exception 指标就加一并立即报警。
2. 如何打通指标、日志内容和链路关系
我们在配置日志指标的时候可以配置一个特殊的指标,当日志符合这个特殊指标的时候,agent 会同时提取这行日志并连同指标发送出去,聚合器在聚合指标的同时并把这些日志存储起来。
这些日志里通常都存有 trace id,这是报警和链路关系的关键所在。链路跟踪系统(在微店称为 vtrace)的 sdk 会在日志抛出异常的时候将 trace id 也打印在日志里,一个 trace id 和一个完整的链路请求一一对应,它记录着这个请求经过了哪些服务,每个服务的上下游状态和耗时。
当发生故障的时候,检查器会快速将这些日志查询出来,并对于日志里的 trace id 和关键字进行分析,根据关键字我们能快速地知道故障的直接原因,根据 trace id 能快速知道整个链路的故障原因。
3. 日志如何去重
当故障发生的时候,如果关联日志较少,提取关键字还比较容易,但如果日志有成千上万条,提取关键字就显得不那么容易。我们借鉴搜索引擎处理文本的办法,利用 simhash 和海明距离帮助我们准确地定位关键字。 每个日志可能有不同的时间戳、IP,但其实他们都是类似的,我们先利用 simhash 计算每条日志的哈希值,并利用海明距离判定两条日志是否相似,海明距离在 3 以下的日志,我们就认为他们是同一条日志。 标记每种日志的出现次数,对他们进行排序,我们再对 top 10 的日志抓取关键字和 trace id。
simhash 对于中长日志的效果较好,特别是对于带堆栈的日志,但小日志因为文本少,误差会较大,如果有需要对短日志做相似匹配,建议自己设计算法提取文本的特征值。
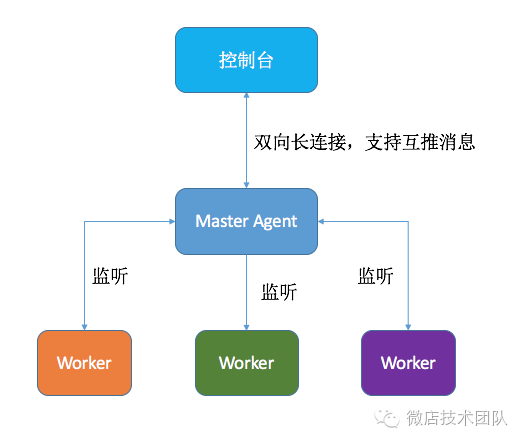
4. 如何设计 agent 结构
我们从稳定、可运维性、安全几个角度做了一些设计:
-
单 Master 多 Worker 结构,我们将 Agent 设计成了多进程的模式,Master 功能非常单一,只负责和控制台通信以及维护 Worker 的启动状态和版本,当 Master 启动的时候,控制台会告知 Master 需要启动的 Worker 列表以及版本,但 Worker 不存在或是版本过旧,Master 会拉取最新的文件,然后启动,并监听 Worker 的管道,一旦 Worker 因为某些原因挂掉,Master 会重启它。
-
自升级和灰度发布,每次 Agent 升级都是一次大型的发布,而一旦发布出问题,往往会焦头烂额,所以我们为 Agent 的升级设计了灰度机制,我们可以精确地升级某台机子的 Agent 版本或是某个网段某个分组的 Agent,以方便我们测试某个功能或是检查是否有兼容问题。
-
双向通信,控制台在有新的监控任务的时候,需要主动将任务推送到 Agent,因为大部分的 rpc 框架都是单向通信,所以传统的做法是让 Agent 也开一个端口,利用两条 rpc 连接来达到目的。但我们觉得这个方式不利于扩展,碰到多层网络结构就歇菜了,况且 tcp 本身就是全双工的连接,两个连接显得多此一举,为此我们在 tcp 的基础上利用 protobuf 重新封装了一个双工的 rpc 协议。
-
资源控制,Agent 作为监控系统的一部分,首要限制就是不能影响正常的业务,不能和业务进程争抢 CPU、内存和网卡等重要系统资源。Agent 在解析日志的时候会判断任务的资源使用率,自动抛弃过大的日志并作报警。
成果
在经过半年的使用后,我们的监控比起原先的 zabbix 有长足的进步:
-
依靠日志监控和自发现,现在每上线一个服务,都自动对服务的异常日志、中间件日志做监控,一旦服务某个功能有问题,立刻报警提醒开发和运维关注。
-
每次报警之后,监控系统立刻对此次报警作分析,根据相关的日志提取关键字和链路信息,在第一时间将分析结果发送到开发和运维的手中,我们将问题的排查时间从原来的数小时缩短到几分钟。
-
精心设计的 dashboard 和任务面板完整地呈现服务树的关系,并把每个服务的 metric 都罗列出来,在 metric 过多的时候,还可以通过关键字进行搜索,开发和运维登录监控系统的频次比以前高出很多。
-
通过对日志中业务指标的提取,监控系统也覆盖到了大部分重要的业务监控,利用环比进行业务指标曲线的监控。对于无法从日志中提取的业务指标,例如使用 Elasticsearch 来存储数据的一些业务,我们也同样设计了一个服务将 Elasticsearch 的数据转化为时序数据并进行监控。
展望
整套监控系统经过半年的开发,已经完成系统监控、JVM 监控、日志监控、ES 数据监控、网络监控等重要的功能,我们的目标是将整个系统打造成一个强大的全功能监控体系,还有工作等待我们去完善。 例如我们的 Agent 虽然是多进程结构,但对于 worker 的控制还不够完善,无法支持自定义脚本的监控,我们还需要改造 master 做更灵活的控制。最后,如果你对打造监控系统或者其他技术岗位感兴趣,欢迎加入我们。

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

