专访| 独家对话百度 NLP:先解决语义理解,再谈机器翻译取代人类
9 月 28 日,Google 在 Research Blog 中介绍其神经网络机器翻译系统(GNMT)进展,译文质量的大幅提升引发业内极大关注。据称,在双语评估者的帮助下,通过对维基百科和新闻网站的例句测定,在多个样本的翻译中谷歌神经网络机器翻译系统将错误降低了 55-85%甚至更多。

翻译质量对比,来自 Google Research Blog
即便如此,网友发现其翻译效果虽有显著提升,但仍未避免将「我想下班」翻译为「I want to work」等低级错误(第二天已被修复)。
事实上百度的在线翻译系统,一年前就应用了基于神经网络的翻译方法(NMT)。去年百度曾在 ACL 会议上发表论文《Multi-Task Learning for Multiple Language Translation》,探讨用 NMT 技术解决多语言翻译及语料稀疏的问题。该论文得到业内研究人员的极大关注,并被 ACL2016 的 NMT Tutorial 列为研究方向。Google 和 Bengio 的研究团队都在此论文的基础上进一步扩展了研究。
为此,机器之心专访百度自然语言处理部技术负责人吴华、高级总监吴甜,就神经网络机器翻译系统的优缺点、如何获得高质量训练数据及百度翻译目前进展展开话题。同时也借此机会了解百度自然语言处理部及其开展的 NLP 技术研发工作。以下为采访内容整理,以飨读者。
NMT、SMT 的优与缺
机器之心:能请您先介绍一下百度 NLP 部门吗?
答:百度 NLP 部门在公司内部是具有较长历史的部门,从最初搜索诞生时,就已经有 NLP 方面的工作。2009 年底左右,百度正式成立自然语言处理部。现在,这个团队人员构成非常多元,有自然语言处理、机器学习、信息检索、数据挖掘、机器翻译等多领域的专业性人才,擅长工程实践和擅长科学研究的人才都能够在团队中发挥重要作用。同时,架构开发、前端开发、客户端等软件开发和硬件开发工程师,产品设计及语言学专业人才也是团队的重要组成部分。
整个部门的大方向有几个。第一是为百度的众多产品提供最基础的、NLP 模型算法,包括百度所有产品都在用的分词算法、专名识别、词性分析、语义理解、篇章理解等等一些基础的一些工具。目前 NLP 部门为整个公司提供一个大型平台 NLP 云,未来这个平台也会对公司外有所开放,目前(这个平台)每天都有千亿量级的调动量。还有贴近应用的一些大型的应用系统,比如说深度问答系统。NLP 开发的深度问答系统在百度的搜索产品上,会有一些直接展示。比如在搜索引擎中提出一个问题,用户可以不需要打开网页,直观的得到答案。
第二大方向是语义理解,实际上从最初期开始,NLP 就一直在致力于这样的一个方向。在原来的搜索时代,会分析用户的搜索 Query 含义是什么。到今天新的产品形态产生之后,已经不仅仅是分析搜索的意图。越来越多的用户会开始尝试有上下文的、更积极的交互方式,这就需要有上下文的理解。
第三个方向是对话系统。对话系统就是让机器能像人一样,和用户有对话性质的交互。NLP 过去几年一直在积累相应的技术,通过对话引导让用户和机器人能一句一句的交流下去。这部分实际上已经应用在百度的度秘产品中。
第四个就是机器翻译。百度在机器翻译上已有 6 年的积累,每天有大量用户使用线上机器翻译产品,翻译 API 也有很多外部的企业开发者在使用。从 2014 年开始,百度尝试做基于神经网络的翻译系统,正式上线发布时间要早于 Google 一年。并且我们在发布的同时,还开发了离线版本,可以在手机上使用。
还有一些是更前瞻的探索。比如小度机器人。机器人能看、能写、能听,和人相比它还需要一个特别重要的能力就是思考。思考的前提,是先能听得懂语言。所以从 NLP 角度来说,更多的是希望机器人能懂语言、理解语言,然后能够跟人交流。那这款小度机器人,过去的几年也有频繁的亮相。

领导百度 NLP 工作的百度副总裁王海峰博士,已于近日当选 ACL Fellow
机器之心:谷歌最近发布了神经网络翻译系统,我们怎么看这个系统?
答:Google 发布的系统综合了 NMT(Neural Machine Translation,神经机器翻译)领域近年来的研究成果。其所使用的 Seq2Seq 翻译模型、Attention 机制、以及深层 LSTM,在此前已有 Bengio 团队等多篇论文提及,从 Google 发布的论文的参考文献中可以看到。
此外,Google 针对大数据和深层模型的训练,进行了诸多工程方面的优化。例如,其使用了自身研发的针对深度学习的计算机器—TPU,加速了训练和解码。
机器之心:那么百度是否有相关的研究?
答:百度在这方面的研究起步很早,成果也非常多。而且,我们的神经网络翻译系统早在 2015 年 5 月就正式上线发布了。
我们从 2014 年开始便尝试做基于神经网络的翻译系统,2015 年发布在线翻译系统的时,BLEU(Bilingual Evaluation Understudy)指标已经比传统的 SMT(统计机器翻译)系统高六、七个点。我们同时还开发了离线版本,可以在手机上使用,
当时学术界对于深度学习的翻译方法到底是否实用还有一番争论,我们很早就发现基于 Attention 机制的 Seq2Seq 深度学习模型是有用的,经过多次实验验证,在很多集合上超过了传统方法。同时,针对 NMT 本身存在的一些问题,进行了技术攻关,短短 3 个月的时间便完成了开发和上线。当大家还在讨论 Attention 机制时,我们已经结合了原有的统计方法上线。可以说,百度翻译是全球首个互联网神经网络翻译系统。
机器之心:NMT(基于神经网络的翻译系统)效果就真的好于 SMT(基于统计的翻译系统)吗?或者说他会在哪个方面会好于 SMT 呢?
答:机器翻译目前是两大流派,一大流派是统计翻译模型(SMT),在整个业界已经持续了 20 多年的研究。另一个就是基于神经网络的翻译模型(NMT),过去的两年发展比较迅速。
从很多公开的评测上能看出,基于神经网络的翻译系统已经取得了比以前系统更好的成绩。这两大翻译系统我们一直在向前推进研究。总体上来说,基于神经网络的翻译系统,在长句翻译上有明显优势。
机器之心:可以从技术角度具体解释下吗?
答:从整体看,在数据训练比较充分,比如有大数据集的时候,NMT 效果是好于 SMT 的。一句英文翻译成一句中文,这算一个句对。如果中文和英文之间的双语语料对有很多,那么 NMT 整体上好于 SMT。
原因就在于,SMT 以前用的都是局部信息,处理单位是句子切开以后的短语,最后解码时将几个短语联系在一起,并没有充分利用全局信息。NMT 则利用全局信息,整个句子的信息解码后,才生成结果。这就是它的优势,也是其在流畅性上更胜一筹的原因。
再进一步,翻译有一个很重要部分是「语序调整」。比如中文会把所有的定语都放在中心词前面,英文则会把修饰中心词的介词短语放在后面,机器常混淆这个顺序。NMT 在语序学习上的优势也带来了它翻译的流畅性。
而 SMT 在短句或者数据较小的情况下,优势较为明显。以成语翻译为例,实际上不是意译而是直译,必须在语料库中有对应内容才能翻译出来。NMT 的翻译过程决定了其有时不能很好的处理这类问题。
如今互联网用户的需求是多种多样的。翻译涉及口语、简历、新闻等多领域,一种方法很难满足所有的需求。因此现在百度的翻译系统中包含了 SMT、NMT,甚至还有传统的 EBMT。所以,一个线上服务的翻译系统,其实是综合的系统。
不过从整个大趋势看,随着神经网络技术的进一步发展,它会越来越成为主流。目前在我们的中、英、日、韩等多个系统中,它就是主流。
机器之心:那么能否通过不断增加网络层数来提升 NMT 效果?
答:在网络层数的增加过程中,成本、复杂度也随之提升。并不是线性地增加网络层数,收益比就更高,我们会去继续研究,但并不代表不断增加层数就一定是好方法。
就翻译本身这个任务,现在有两大问题造成翻译效果不好。一是在于,训练语料本身是有噪音的,我们花费了大量时间和精力研究怎样找到更好的训练语料,怎样清洗出更好的语料。第二个是模型本身的不完美性,我们会不断优化。这两大方面的工作都是我们的重点。
获取数据与解决语料稀疏问题
机器之心:刚才有提到 NMT 是非常依赖数据规模的,以及训练语料中的噪音问题,如何获得高质量的训练数据?
答:我们能获取的语料很多,比如网络上存在的大量翻译句对,但这些数据存在三个问题。
第一个在于它们可能是机器翻译产生的语料。因为机器翻译技术已经比较普及,尤其是医疗方面有大量的机器翻译产生的语料。由于国外的医疗研究比国内先进,很多人会借助机器翻译技术来看文档。而这种语料若进入语料库,翻译系统学出来的还是机器翻译的句子。
第二种噪声是来自于恶搞。比如我们最早的时候看到「how old are you」,翻译成「怎么老是你」。因为语料里面「how old are you」,全是「怎么老是你」,出现频次非常高。
第三种是翻译得不地道的。互联网上翻译内容的人不一定是翻译水平很高的人,他们在翻译文章时会自己加入一些内容。这种是比较难识别的,因为很零散。
针对每一类噪声,我们都会建立一个不同的质量检测模型,结合了翻译自身的技术以及互联网技术。机器翻译的语料是不能用机器翻译的概率特征过滤的,比如「how old are you」每个对齐,怎么(how)老(old)是(are)你(you),翻译得特别完美肯定无法过滤。所以我们一般从网站本身的权威性着手,对于权威性低的,相应高置信度就要打低。此外,我们还通过识别翻译特征判断其是否为机器翻译语料,比如:流畅性不好、语序不对等等。
机器之心:不同语言的语料规模的差别较大,英语可能会多一些,小语种会少一些。如何将 NMT 的研究成果,应用于不同语言语料的构建中?
答:这其实是语料稀疏问题。语料稀疏是 NLP 一直在面对的问题,以前有一些解决方案,比如说: Transfer Learning(转移性学习)、机器翻译的 Pivot-Language(枢轴语言)技术、标签传播等技术。从一种语言翻译到另外一种语言,即使同一种语言在不同领域的语料也是不一样的,从这个领域迁移到另外一个领域,都需要解决语料的构建问题。
NMT 是可以应用于此的,因为 NMT 本质是把一种语言翻译成另外一种语言。它的好处在于,不同语言之间可以互相学习他们的语义表示,比如中文的「看」,和英文的「See」(看见)或者「Read」(看书)。以相似度来计算,相似度高的就认为它们拥有同样的语义,可以用在不同语言的标注上。
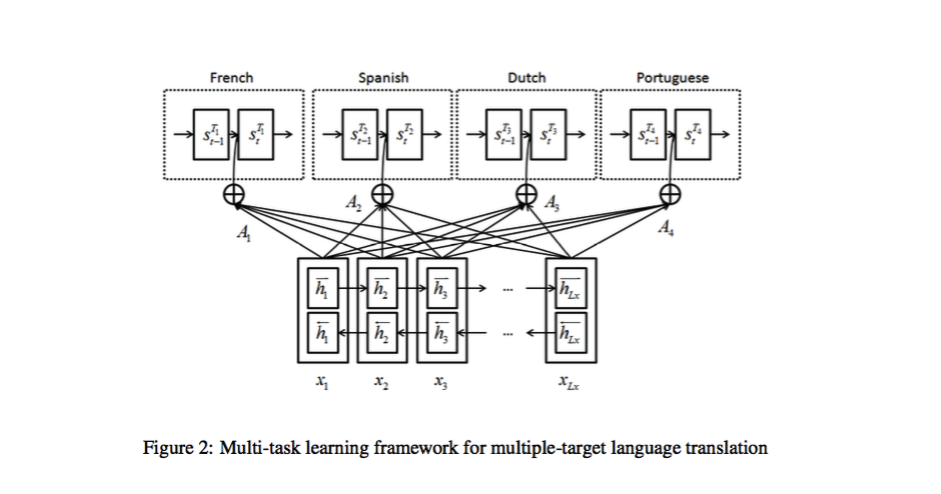
用来解决语料稀疏问题的多任务学习框架,来自《Multi-Task Learning for Multiple Language Translation》
这样说可能有些抽象,举例来说我们去年在 NLP 领域国际会议 ACL 上发表了一篇文章,讲述用 NMT 解决语料稀疏的问题。中文和英文之间的句对很多,但中文和其他语言如日文、泰文、西班牙文的句对就很少。怎么办?我们同时学习。中文翻译成英文、日文、韩文、泰语的句对都一起学习,这样就能充分利用中文在源语言端的表示。此外,还学习关联知识,韩语-日语之间结构类似,从日语中学习到的结构性信息适用于韩语翻译。
后来 Bengio 团队还在我们论文的基础上做了类似的工作,他们在我们的研究基础上扩展成多(语言)对多(语言),其实思想是类似的。后来他们还把这个工作开源了。
机器翻译能否取代人工翻译?
机器之心:很多人可能就会问,人工翻译会不会被机器取代?您怎么看这个想法?
答:从很长一段时间来看,完全取代还是不太可能的。
现在基于互联网大数据的机器翻译的优势在于,突破了原来编辑规则的局限。与人工翻译相比的好处是能迅速翻译很多语言。同时它解决了一些问题,比如几个场景:出门旅游的沟通、写 E-mail 借鉴机器翻译用词、小孩利用机器翻译扩充词汇。这种形式解决了用户的一些问题,也达到了实用的程度。
但是翻译最终的目标是「信、达、雅」,「信」至少是忠于原文,「达」就是译文通畅,符合目标语言用语习惯,「雅」是在这个基础上表达生动、形象。尤其在「雅」上,目前机器翻译远远不够。
就像我们说英文,能说但不一定达到「达」的标准。「达」的意思是用语非常「native」(地道),我想机器翻译也没到。更不用说「雅」,即使人工翻译也只有少数人能达到雅的标准。
机器之心:达到「信、达、雅」的关键是什么?
答:主要是语义理解问题。我们现在的翻译方法,没有做到「理解」。深度学习只是在模式识别这个手段上更加高明一点,但还没有理解语言。
与专业的人工翻译相比,机器翻译有很多不足。首先,机器翻译是以句子为单位,即使是篇章翻译也是不看上下文,翻译完一句算一句。人工翻译是以篇章为单位,翻译前要先通读一遍,抓住意境和主旨。
其次,翻译需要常识背景。口语交流、会议翻译、随意聊天、正式作文等所需的文体是不同的,而同一个词在不同的文体上翻译也不同,这也是机器翻译的缺点。尤其是意译,比如翻译诗歌。如果没有知识背景,将中国的诗翻译成英文就会显得直白而没有韵味。跨语言的「信、达、雅」,连人都很难做到。
事实上,机器翻译需要综合多学科,包括计算机学、语言学、认知学等等。机器翻译,看似简单,实则很难。因此我认为,机器翻译的道路还任重道远。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

