开车啦!一键爬知乎各种爆照
这是一篇严肃的技术分享文章,旨在向大家介绍一些网络安全方面的知识,及相关工具的使用。闲话少说,直接进入正题。
实现目标
知乎上经常有各种爆照及钓鱼贴,类似「胸大是一种什么样的体验?」, 「女生有翘臀是什么样的体验?」等。其实大家关心的只有照片,是不是?
我们的目标是在终端输入:
./get.sh 胸大
就能从知乎将 胸大 (或者其他关键词)相关的话题回答中的图片,一键下载到本地的文件夹中。我试着跑了下脚本,有好多让人看了就脸红:flushed:的照片:
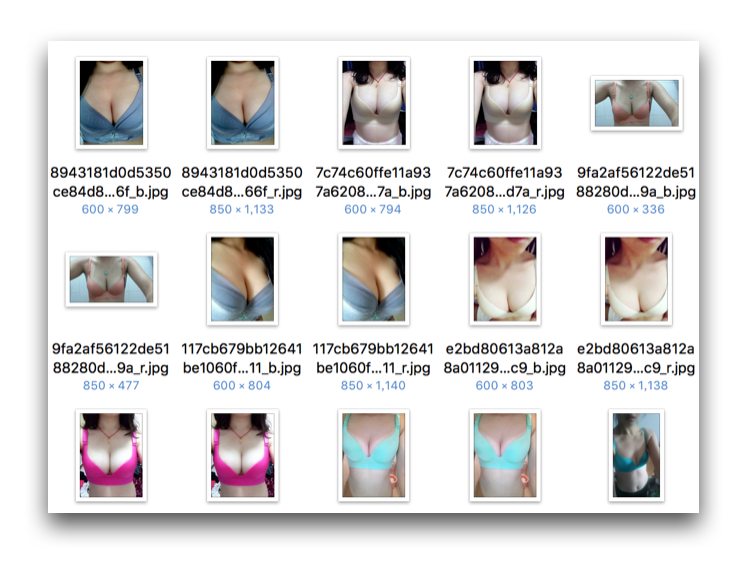
真的是来自知乎。。
着急的同学可以直接在我的公众号(MrPeakTech)回复z,获取可运行的脚本。
准备工作
技术手段:中间人攻击,replay attack。
工具:Mac,装有知乎App的iPhone手机,mitmproxy,mitmdump,grep,wget。
知识储备:http协议,python脚本,基础的安全知识。
实现思路
第一步:使用mitmdump记录知乎App的搜索request,和进入回答的request。
第二步:replay搜索request,hook请求,修改request参数。
第三步:获取搜索结果后,replay回答的request,hook请求,修改request参数。
第四步:使用正则提取回答response中的图片url。
第五步:使用wget将图片下载到指定文件夹。
动手
这次我们的主角是mitmproxy和mitmdump。之前我写过一篇文章介绍如何使用mitmproxy做https抓包。这次要使用到更高阶一点的功能:replay attack。建议先看下我之前那篇文章。
安装mitmproxy
没有安装mitmproxy的同学可以先通过brew安装下:
brew install mitmproxy
安装好之后,在终端启动mitmproxy:
mitmproxy
接下来需要在iPhone上设置http代理:
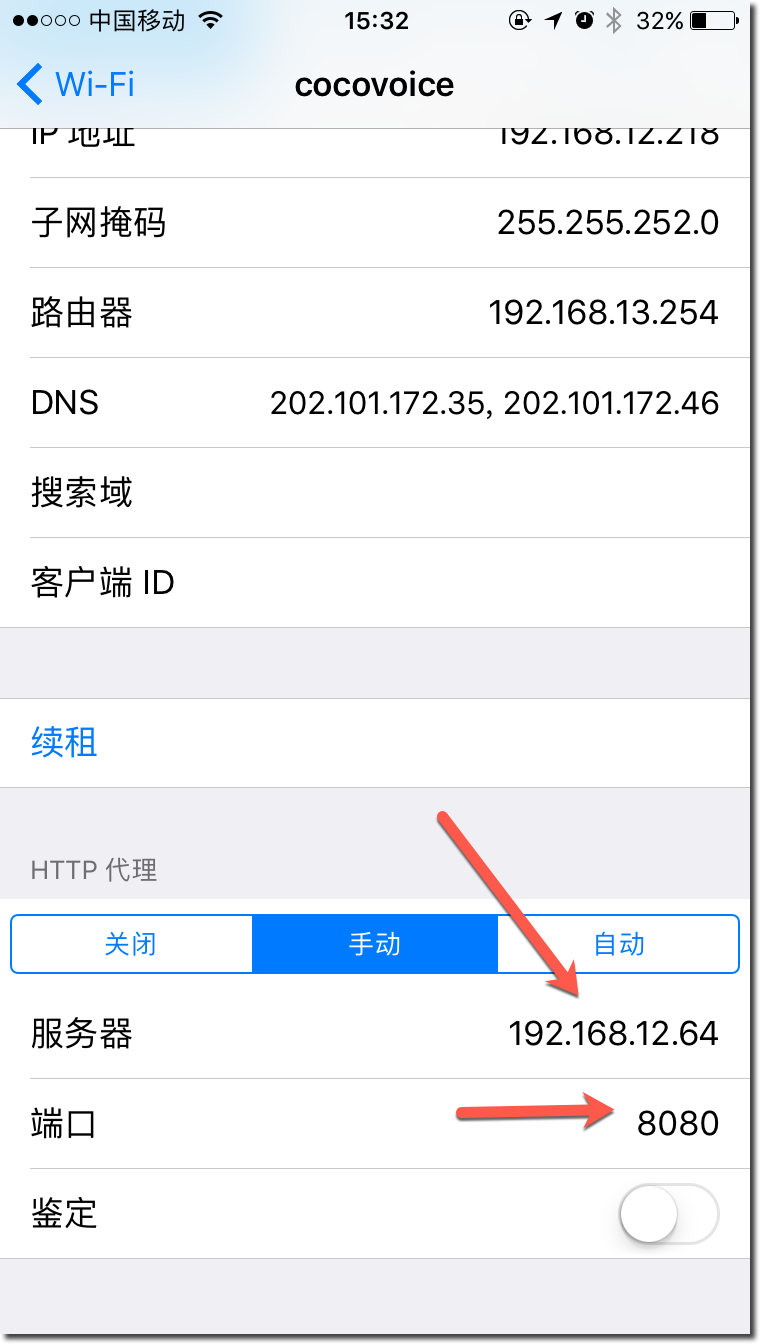
IP地址填你Mac系统当前的IP,端口默认8080,记住iPhone要和我们的Mac处于同一个局域网中。
如果是第一次使用mitmproxy,需要在iPhone上安装CA证书,打开iPhone Safari,输入地址:mitm.it,在下图中点击Apple安装证书。
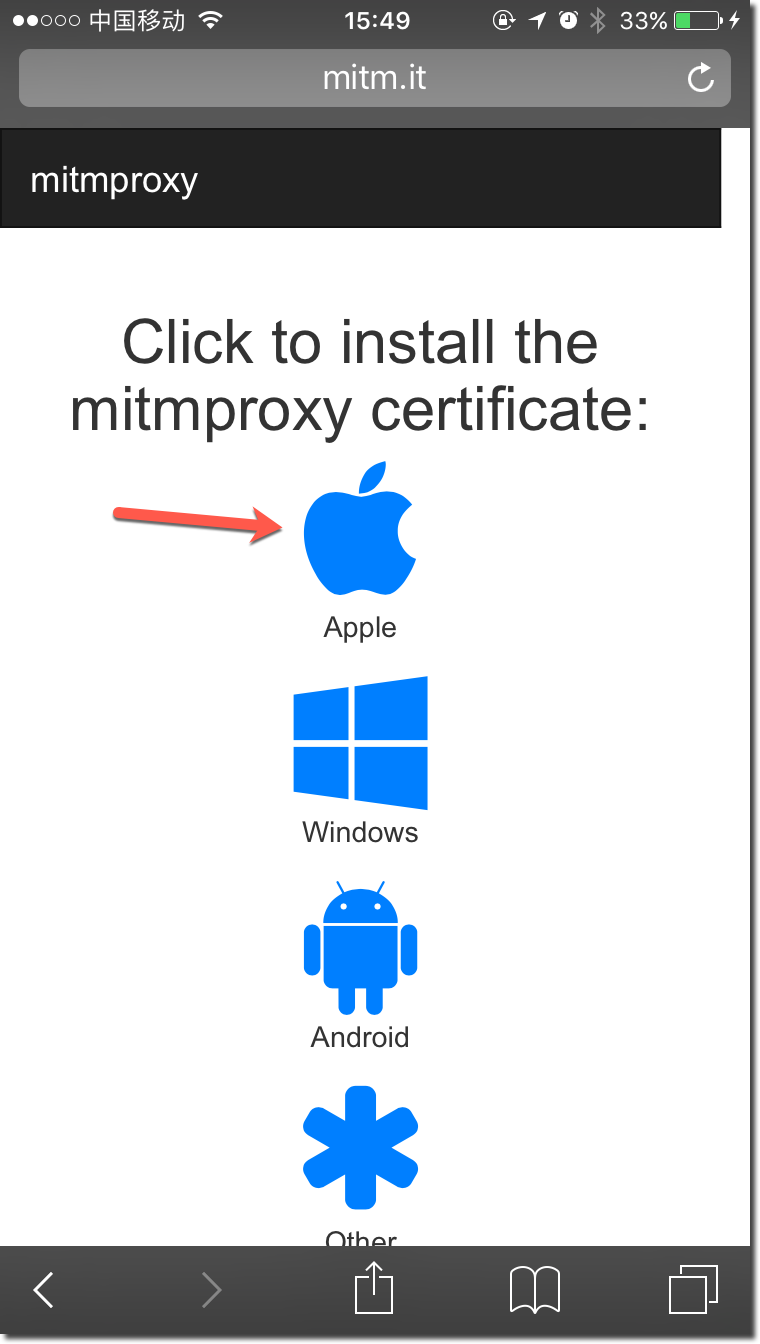
这样就配置完毕了,下面我们来记录知乎App的request。
记录App Request
首先我们先打开知乎App,进入搜索界面:
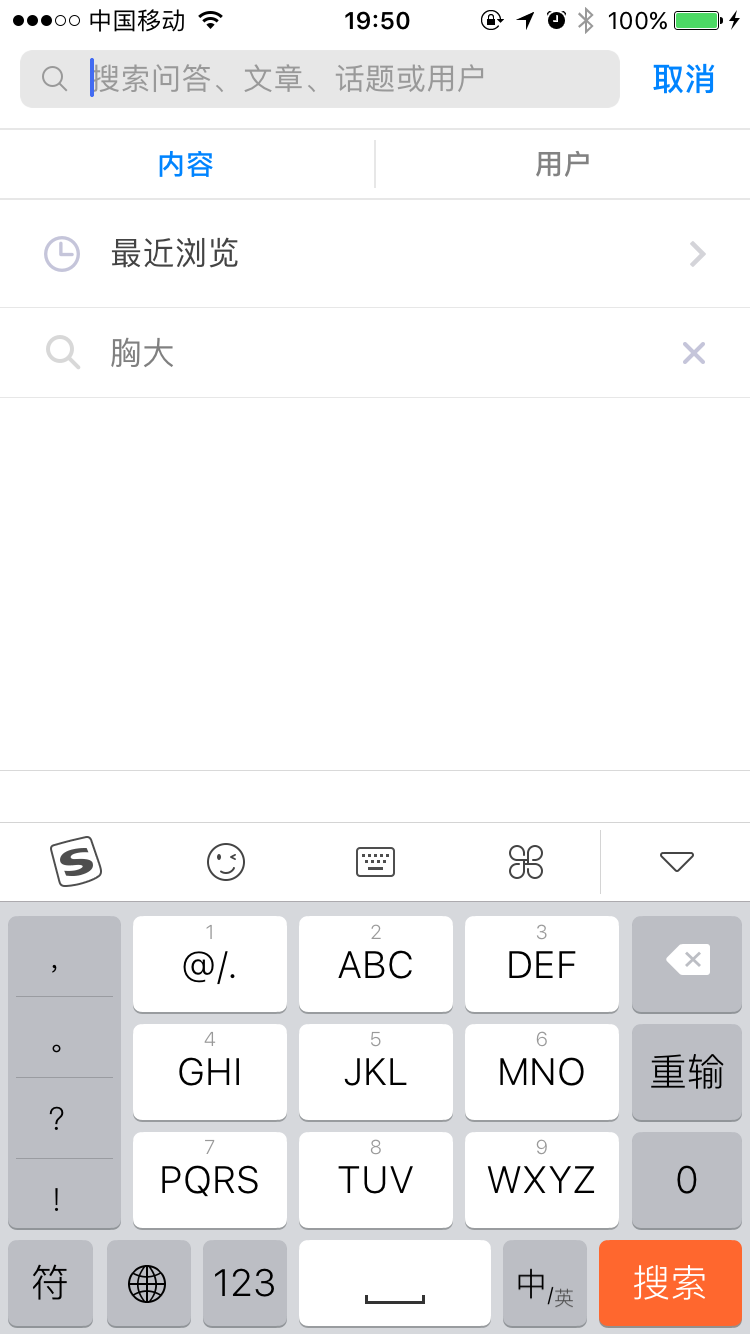
接着启动mitmdump,来记录手机端的https请求,在终端输入:
mitmdump -w raw
回车之后,手机端的请求就都会写进raw文件了。
下面在App端输入关键字「胸大」,点击搜索,翻页(想要结果多点,可以多翻几页)。
这样我们在终端可以看到如下三个被捕捉请求。
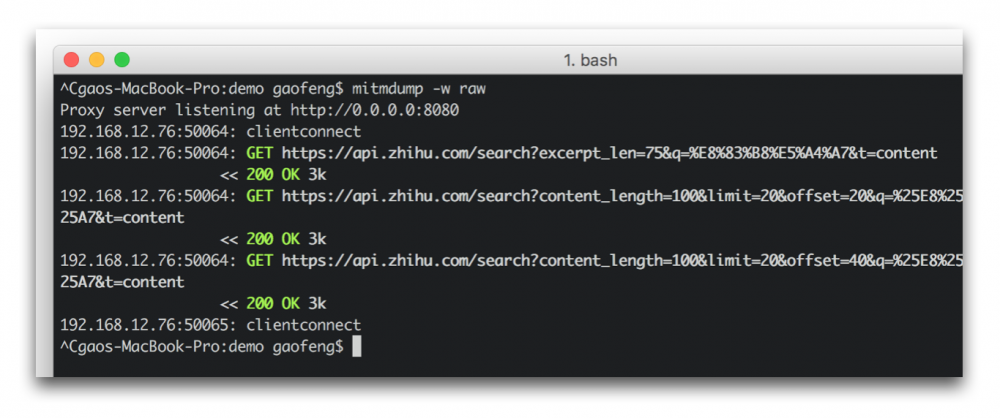
有时候我们会捕捉到多余的请求,需要手动删除下,可以先退出mitmdump,然后再终端输入:
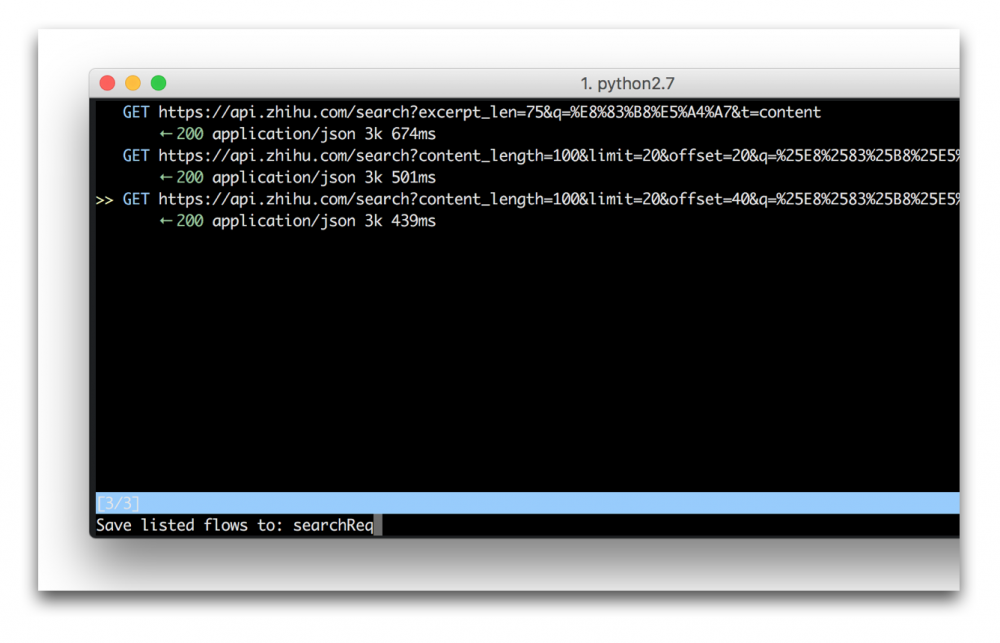
mitmproxy -r raw
进入请求的编辑界面,按d可以删除我们不想要的请求,编辑完之后,按w会提示保持到文件,我将请求保持到searchReq文件:
在重复上面的操作,在App端点击进入回答的操作,将单个回答的request保存到文件detailReq。
到这里我们就记录完毕原始请求了!
Replay Attack
经过之前的操作,我们有了两个原始请求文件:searchReq,detailReq。
接下来回放search请求,回放的时候我们还需要hook一个python脚本来修改请求参数。先看下search请求的格式,通过mitmproxy可以查看详情:
GET https://api.zhihu.com/search?excerpt_len=75&q=%E8%83%B8%E5%A4%A7&t=content
这是个非常简单的GET请求,参数格式也一目了然。而且幸运的是知乎的后台即没有做参数的签名,也没有加时间戳来防replay attack。看上去我们只需要替换q=xxx这个参数值即可。所以写段简单的python脚本来替换吧:
class Replacer:
def __init__(self,dst):
self.dst = dst
def request(self,flow):
flow.request.path=flow.request.path.replace("%25E8%2583%25B8%25E5%25A4%25A7", urllib.quote_plus(urllib.quote_plus(self.dst)))
flow.request.path=flow.request.path.replace("%E8%83%B8%E5%A4%A7", urllib.quote_plus(self.dst))
def start():
parser = argparse.ArgumentParser()
parser.add_argument("dst", type=str)
args = parser.parse_args()
return Replacer(args.dst)
脚本很简单,就是将我们输入的关键字urlencode下,再替换原先的参数。
我的系统是python 2.xx,3.xx的encode方法调用有些差别,要注意。
这里有点奇怪的是知乎搜索翻页的接口,将关键字连续urlencode了两次,不知道有神马讲究在里面。不过不管啦,我们继续。
写好脚本(replace_query.py)之后,再写个bash脚本来实施replay attack。这个脚本也是我们的关键执行脚本get.sh:
#!/bin/bash #replay attack mitmdump -dd -s "./replace_query.py $1" -znc searchReq -w searchRsp
参数我就不一一解释啦,大家自己看mitmproxy的官方文档,总之这段脚本会回放存在searchReq当中的搜索请求,并执行replace_query.py当中的替换方法,最后将请求的结果存放在searchRsp文件当中。
大家可以先执行这段脚本,看看searchRsp有没有我们想要的请求结果。
chmod +x get.sh ./get.sh 胸大
如果一切正常,我们会看到一段格式规范,结构清晰的json串。类似:
{
"data": [
{
"content": {
"excerpt": "也要表现出来(基本上<em>胸大</em>的人.在<em>大胸</em>的对比下腰都是细的,腰围和胸围一样大的<em>大胸</em>……那种应该不是<em>大胸</em>吧.只是<em>大胸</em>围而已)很多<em>大胸</em>妹子的误区都是喜欢穿宽松的上衣.配合含胸.以为自己",
"url": "https://api.zhihu.com/answers/61382005"
},
肉眼扫描下就可以发现我们的目标是 https://api.zhihu.com/answers/61382005 。这种url是我们进入回答页面的url,61382005应该就是我们的detail ID号。
接下来我们需要使用grep,写个简单的正则提取出这些ID号。走你:
#extract answer url cat searchRsp | grep -aoE 'https[^"]*(answers)[^"]*' | sed 's/////g' | grep -oE '[0-9]+' > answers
很简单的正则,上面的脚本就将我们的ID号统统提取出来,并写进answers文件。执行下打开answers文件,看看ID有木有。
Replay Answer Request
接下来我们按同样的步骤回放下进入回答的请求。
先看下请求的格式:
GET https://api.zhihu.com/answers/61382005
也是个光秃秃的url,替换ID号就OK拉。上脚本(replace_url.py):
import mitmproxy
import argparse
class Replacer:
def __init__(self,dst):
self.dst = dst
def request(self,flow):
flow.request.path=flow.request.path.replace("61382005", self.dst)
def start():
parser = argparse.ArgumentParser()
parser.add_argument("dst", type=str)
args = parser.parse_args()
return Replacer(args.dst)
很简单的GET请求,替换ID号即可。
接着实施replay attack:
#replay attack
while IFS= read -r p; do
#echo "$p"
mitmdump -dd -s "./replace_url.py $p" -znc detailReq -w detailRsp | grep -aoE 'http[^"]*.jpg' | xargs wget -P ./magic
done < answers
这段bash脚本将之前保存在answers文件中的ID号,一行行读取出来,再通过mitmdump进行replay,并通过replace_url.py替换ID号,最后将结果经过grep过滤,xargs传递给wget来下载,最后文件都会下载到magic目录下。
没有下载wget的同学,可以先通过brew安装下:
brew install wget
到这里所有的工作就完成啦,所以我们有了最后的get.sh:
#!/bin/bash
#replay attack
mitmdump -dd -s "./replace_query.py $1" -znc searchReq -w searchRsp
#extract answer url
cat searchRsp | grep -aoE 'https[^"]*(answers)[^"]*' | sed 's/////g' | grep -oE '[0-9]+' > answers
#replay attack
while IFS= read -r p; do
#echo "$p"
mitmdump -dd -s "./replace_url.py $p" -znc detailReq -w detailRsp | grep -aoE 'http[^"]*.jpg' | xargs wget -P ./magic
done < answers
赶紧运行脚本,发挥想象力,感受下知乎爱的供养吧。
安全知识总结:
这里只是给大家提供个思路,我相信还有很多App都有类似的问题,在安全方面投入太少。
这个小工具之所以能成功,是由于:
知乎App的客户端没有做ssl pinning,所以可以通过中间人攻击分析请求。
知乎Server端也没有针对replay attack做任何防范。
大家做App还是要多注意下安全方面的东西,即使上了https,也要做多做一层加密保护。安全方面的工作,做得再多也为过。
我这个脚本对应的账号有可能会被停了,如果失效,可以照着上面的步骤自己做一个:)
最后,温馨提示:在公众号恢复消息z,可以下载脚本。使用方式:
chmod +x get.sh ./get.sh 好好学习
欢迎关注公众号: MrPeakTech

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

