卷积神经网络新玩法:分分钟让你变脸尼古拉斯·凯奇
近日,来自比利时根特大学和 Twitter 的几位研究者在 arXiv 上发表了一篇很有趣的利用人工智能进行「换脸」的论文《 Fast Face-swap Using Convolutional Neural Networks 》,而著名演员尼古拉斯·凯奇和著名歌手泰勒·斯威夫特很不幸地成为了他们的实验对象。机器之心对该论文进行了部分编译。

摘要
我们思考了在图像中进行面部交换(face swapping)的问题——即在保持原有姿势、面部表情和光照的同时,将一个输入的身份转换成一个目标身份。为了执行这样的映射,我们使用了卷积神经网络,并训练使其能够从一个人的照片的非结构化集合中获取目标身份者的外观。这种方法是通过将该面部交换问题描述成一种风格迁移问题而实现,而风格迁移的目标是将一张图像渲染成另一张图像的风格。基于这一领域的最新进展,我们设计一种能让该网络生成高照片真实度结果的新损失函数(loss function)。通过神经网络和简单的预处理与后处理步骤的结合,我们的目标是无需来自用户的输入就能实现实时的面部交换。
1. 相关工作(略)
2. 方法
假设有了一张某人 A 的图像,我们要将他/她的身份变成某人 B,同时保持头部姿势和表情以及光照情况不变。使用风格迁移,我们输入图像 A 的姿势和表情作为内容,输入图像 B 的脸作为风格。光线以另一种单独的方式处理,下面会介绍。
在 Ulyanov et al. [33] 和 Johnson et al. [11] 的基础上,我们使用一个经过权重 W 参数化的卷积神经网络来将这个内容图像x(即输入图像A)转换成输出图像 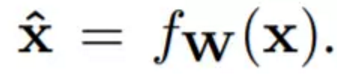
与之前的结果不同,我们假设给定的是一组而非一张风格图像,我们用 Y = {y1, . . . , yN } 来表示。这些图像描述了我们想要匹配的身份而且仅会在训练该网络的过程中使用。
我们的系统有两个另外的组分用来做脸对齐(face alignment)和背景/头发/皮肤分割。我们假设所有的图像(内容和风格)都与一张前向视角的参考脸。这可以通过一个仿射变换(affine transformation)实现,这需要将给定图像中的 68 个面部关键点对齐到参考的关键点。面部关键点是使用 dilb [13] 提取出来的。我们使用了分割来恢复来自输入图像 x 的背景和头发,而 x 目前还不会被我们的变换网络(transformation network)保存。我们使用了 OpenCV [22] 中的一种无缝克隆技术(seamless cloning technique)[25] 来拼接背景和所得到的面部交换了的图像。尽管目前确实存在一些相对准确的分割方法,包括一些基于神经网络的方法 [1, 21, 24],但为简单起见,我们假设 segmentation mask 已经给出,并将重点放到了剩下的问题上。关于该系统的概述可见于图 2.
下面我们会描述该变换网络的架构和训练中所使用的损失函数。

图 2:我们方法的示意图。在将输入图像的脸和参考图像对齐了之后,我们的方法使用了一个卷积神经网络来修改它。之后,生成的脸被重新对齐,并且使用了一个 segmentation mask 与输入图像结合到了一起。最上面一行表示了用于定义对齐和重新对齐步骤的仿射变换的面部关键点,以及用于拼接的皮肤 segmentation mask。
2.1 变换网络
我们的变换网络的架构基于 Ulyanov et al. [33] 的架构,如图 3 所示。这是一个带有分支的多尺度架构,这些分支在输入图像 x 的不同下采样版本上执行运算。每一个这样的分支都有零填充的卷积(zero-padded convolution)模块,其后还跟着线性修正(linear rectification)。这些分支再通过相差一倍的最近邻上采样(nearest-neighbor upsampling)和沿信道轴的级联(concatenation along the channel axis)组合起来。该网络最后的分支是以一个 1×1 卷积和 3 色信道结束的。
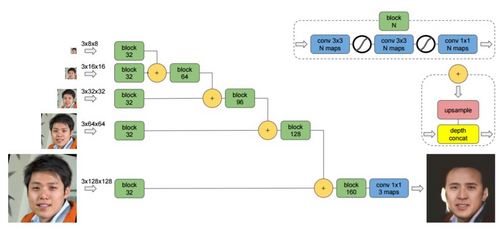
图 3:基于 Ulyanov et al. [33],我们的变换网络有一个多尺度的架构,支持不同分辨率的输入。
图 3 中的网络是为 128×128 输入设计的,有 100 万个参数。对于更大的输入,比如 256×256 或 512×512,其可以直接推断出带有额外分支的架构。该网络的输出仅从最高分辨率的分支中获得。
2.2 损失函数
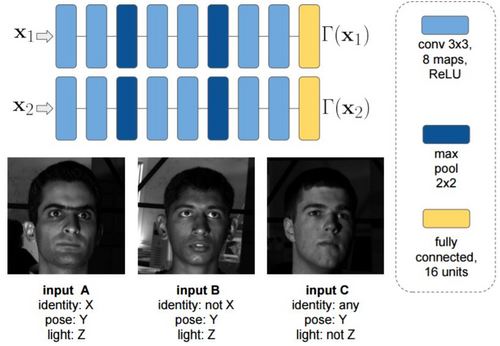
图 4:光照网络是一个 siamese network,其被训练用于最大化带有不同光照情况的图像(输入 A 和 C)之间的距离和最小化带有同等光照的图像(输入 A 和 B)之间的距离。这个距离被定义成了全连接层的特征空间中的一个 L2 范数(norm)。所有的输入图像都与同一张基准脸进行了对齐,这和对变换网络的输入的处理一样。
3. 实验
3.1. CageNet 和 SwiftNet
我们训练了一个变换网络来执行与尼古拉斯·凯奇(Nicolas Cage)的面部交换,为此我们在互联网上收集了他大约 60 张不同姿势和不同表情的照片。为了进一步增加风格图像的数量,每一张图像还都进行了水平翻转。至于内容图像源,我们使用了包含超过 20 万张名人图像的 CelebA 数据集 [20]。
为了测试我们的结果泛化到其它身份的情况,我们还使用了大约 60 张泰勒·斯威夫特(Taylor Swift)的照片训练了一个同样的变换网络。我们发现在同样的超参数(hyperparameter)下,这两个网络实现了质量相近的结果(图 5b)。

图 5:(a)原始图像;(b)上一行:使用尼古拉斯·凯奇的变脸结果,下一行:使用泰勒·斯威夫特的变脸结果;(c)上一行:CageNet 的原始输出,下一行:SwiftNet 的输出。注意我们的方法怎样改变了鼻子、眼睛、眉毛、嘴唇和面部皱纹的外观。其保持了凝视方向、姿势和唇部表情的完好,而且是以一种对目标身份来说很自然的方式。
图 6 给出了向目标函数加入光照损失(lighting loss)所产生的影响。当没有包含这样的损失的时候,CageNet 会生成光照均匀、缺乏阴影的图像。

图 6:左图:原始图像;中图:带有光照损失训练的 CageNet 的结果;右图:不带光照损失训练的 CageNet 的结果
和之前的成果比较,我们发现我们的风格迁移结果严重依赖于风格权重和内容权重之间的平衡 [8]。我们还使用变化的风格权重训练了几个网络。图 7 的结果表明当风格权重较大时,该网络会忽略面部表情,而似乎会直接从风格集合中复制一张最适合的图像。有趣的是,该网络仍然能够检测和保存输入图像的姿势。这意味着用大的风格权重训练的网络能够再现 Bitouk et al. [2] 中类似的卷积面部交换。

图 7:左图:原始图像;中图和右图:在风格权重分别为 α = 80 和 α = 120 的 256×256 图像上训练的 CageNet
后面,我们探索了我们的方法的一些失败案例。我们注意到我们的网络在前向视角上比在侧向视角上效果更好。在图 8 中,我们可以看到随着我们从侧向视角转向正向视角,其脸会变得越来越像尼古拉斯·凯奇。这可能是由数据的不平衡导致的。我们的训练集(CelebA)和风格图像中的正向图像比侧向图像多很多,因为正向图像在互联网上也更为普遍。

图 8:上一列:原始图像;下一列:与尼古拉斯·凯奇的对应变脸结果。可以看到随着脸从侧向转向正向,结果图像的脸也越来越凯奇了。
图 9 给出了其它一些我们的方法无法很好处理的样本。特别是当有眼镜这些东西的时候,眼镜会被移除,然后留下一些奇怪的东西。

图 9:有问题的案例。左图和中图:面部遮挡,在这两个例子中,眼镜被移除,但还是留下了一些东西。中图:闭着的眼睛没有被正确地交换,因为在风格集中没有这样的表情图像。右图:因为姿势、表情和发型太困难,结果非常差。
原文 http://www.jiqizhixin.com/article/1939正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

