ELK部署详解
前言:
最近部署了ELK,遇到了不少的坑,而网络上又较少有比较完整且详细的文档,
因此将自己部署的过程记录总结下,开始使用的服务器配置如下:
主机:2 (elk1,elk2)
系统:CentOS7
配置:4核16G内存
网络:内网互通
ELK版本:elasticsearch-2.4.1 kibana-4.6.1
logstash-2.4.0 logstash-forwarder-0.4.0
redis-3.0.7
ELK简单介绍
ELK是三个不同工具的简称,组合使用可以完成各种日志分析,下面简单介绍下三个工具的作用
Elasticsearch:是一个基于Apache Lucene(TM)的开源搜索引擎,简单点说就是用于建立索引并存储日志的工具,可参考( http://es.xiaoleilu.com/)
Logstash:是一个应用程序,它可以对日志的传输、过滤、管理和搜索提供支持。我们一般用它来统一对应用程序日志进行收集管理,提供Web接口用于查询和统计
Kibana:用于更友好的展示分析日志的web平台,简单点说就是有图有真相,可以在上面生成各种各样的图表更直观的显示日志分析的成果
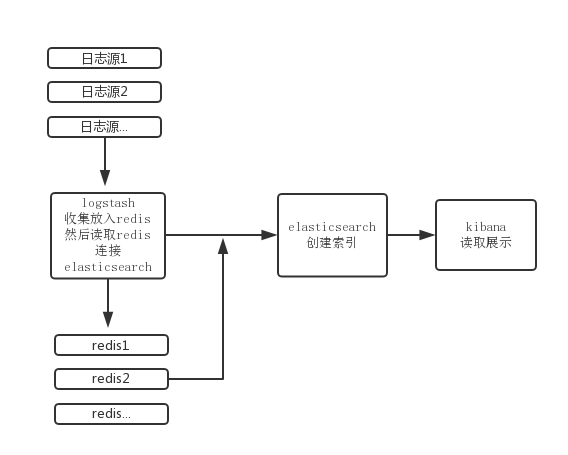
总结:将三个工具组合起来使用我们就可以收集日志分析并展示分析结果
部署安装
简要:
安装过程我基本上参考了: https://www.digitalocean.com/... 来做,
不过遗憾的是,这里只告诉最最基本的安装方式,如果日志量较大又怎么办,遇到问题又怎么查看,资料相对较少,这里我根据自己的安装来详细阐明步骤
注意:
1.本文下载的官网RPM包安装(比较方便),可自行选择
2.这里是单台服务器安装elk,集群安装一样,修改配置文件即可
一、去下载最新的稳定版,因为功能最多最全,这里贴出官网
https://www.elastic.co/downloads
二、Elasticsearch安装
1 由于安装ELK需要jdk,因此没有jdk的可以先安装1.8版本以上
$cd ~ $wget --no-cookies --no-check-certificate --header "Cookie: gpw_e24=http%3A%2F%2Fwww.oracle.com%2F; oraclelicense=accept-securebackup-cookie" "http://download.oracle.com/otn-pub/java/jdk/8u65-b17/jdk-8u65-linux-x64.rpm" $sudo yum localinstall jdk-8u65-linux-x64.rpm $rm ~/jdk-8u65-linux-x64.rpm
2 下载并安装Elasticsearch
$rpm -ivh elasticsearch-2.4.1.rpm
3 编辑配置文件,主要修改以下几项
$vim /etc/elasticsearch/elasticsearch.yml
path.data: /data/elasticsearch #日志存储目录
path.logs: /data/elasticsearch/log #elasticsearch启动日志路径
network.host: elk1 #这里是主机IP,我写了hosts
node.name: "node-2" #节点名字,不同节点名字要改为不一样
http.port: 9200 #api接口url
node.master: true #主节点
node.data: true #是否存储数据
#手动发现节点,我这里有两个节点加入到elk集群
discovery.zen.ping.unicast.hosts: [elk1, elk2]
4 创建配置文件夹后启动
$mkdir -pv /data/elasticsearch/log $systemctl start elasticsearch
检查:/data/elasticsearch/elasticsearch/nodes/0/indices目录是否正确创建
三、Kibana安装
1 下载并安装Kibana
$rpm -ivh kibana-4.6.1-x86_64.rpm
2 编辑配置文件,主要修改如下
vim /opt/kibana/config/kibana.yml server.port: 5601 #server.host: "localhost" server.host: "0.0.0.0" elasticsearch.url: "http://elk1:9200"
3 启动并检查是否安装成功
$systemctl start kibana $netstat -ntlp|grep 5601 #检查5601是否监听 tcp 0 0 0.0.0.0:5601 0.0.0.0:* LISTEN 8354/node
四、安装redis
1 此处我选择安装redis-cli 3.0.7,可以去官网下载编译安装( https://redis.io/)
2 启动
$redis-server /etc/redis_6379.conf &
注:redis安装此处就不多赘述,需要指出的是由于redis是单进程,在ELK中一般用作队列,对I/O读写消耗较高,因此我起多个进程(将在后面优化详细提到),将不同的日志分发到不同的redis,更多redis安装请自行百度
五、生成SSL证书用于Logstash免密传输日志
1 编辑配置文件/etc/pki/tls/openssl.cnf
$vim /etc/pki/tls/openssl.cnf # 这里的IP信息填写logstash的IP,最好内网传输 subjectAltName = IP: 10.26.215.110
2 生成证书
$cd /etc/pki/tls $sudo openssl req -config /etc/pki/tls/openssl.cnf -x509 -days 3650 -batch -nodes -newkey rsa:2048 -keyout private/logstash-forwarder.key -out certs/logstash-forwarder.crt
六、Logstash安装
1 下载并安装Logstash
$rpm -ivh logstash-2.4.0.noarch.rpm
2 接收日志并放入redis的配置文件
elasticsearch output参数参考:
http://www.elastic.co/guide/e...
elasticsearch input参数参考:
https://www.elastic.co/guide/...注意:Logstash没有默认的配置文件,需要手动编辑,此处我给出我使用的两个实例
vim /etc/logstash/conf.d/redis-input.conf
input {
lumberjack {
port => 5043
type => "logs"
ssl_certificate => "/etc/pki/tls/certs/logstash-forwarder.crt"
ssl_key => "/etc/pki/tls/private/logstash-forwarder.key"
}
}
filter{
#这里可以不做任何操作,用于过滤日志分割字段
}
output {
####将接收的日志放入redis消息队列####
redis {
host => "127.0.0.1"
port => 6379
data_type => "list"
key => "logstash:redis"
}
}
3 读取redis消息队列日志,调用elasticsearch接口建立索引
vim /etc/logstash/conf2.d/redis-output.conf
input {
# 读取redis
redis {
data_type => "list"
key => "logstash:redis"
host => "10.24.245.21" #redis-server
port => 6379
#threads => 5
}
output {
elasticsearch {
# 这里填写elasticsearch的http端口
hosts => ["meizu-elk:9200"]
# 建立的索引名,这里我以type加时间来建不同索引
index => "%{type}-%{+YYYY.MM.dd}"
document_type => "%{type}"
# 线程数,对redis队列消费能力有显著影响
# 建议自己测试不同值观察
workers => 100
template_overwrite => true
#codec => "json"
}
#如果你要将logstash读取redis并建立索引的
# 过程显示或者调试,可以打开stdout
#stdout { codec => rubydebug }
}
4 启动Logstash
自己编写了下启动脚本,用于适应我自己需求
#!/bin/bash
# chkconfig: - 07 02
# description: logstash start|stop|restart|reload|check
# author=WZJ
# date=2016-11-7
# 用于管理进程启动关闭查看,此处比较特殊,因为logstash是日志的中间件,负责日志的输入输出
# 而瓶颈在于建立索引,因此,在建立索引的时候多几个进程去读取redis,然后连接elasticsearch
function conf()
{
# 启动脚本名字
script_name="logstash"
# 启动程序文件
start_command=/opt/logstash/bin/logstash
# 启动配置文件
conf_file=/etc/logstash/conf.d/redis-input.conf
# 启动建立索引进程的配置
output_conf=/etc/logstash/conf2.d/redis-output.conf
# Log文件
log_path=/var/log/logstash_output.log
# input-redis log
log_input_path=/var/log/logstash_input.log
# 建立索引的work进程数量
works=4
}
function getPid()
{
i_pid=$(ps -ef | grep "${conf_file}"|grep -v "grep"|awk '{print $2}')
o_pid=$(ps -ef | grep "${output_conf}"|grep -v "grep"|awk '{print $2}')
}
function _start(){
getPid
[ -n "$i_pid" ] && { echo "[start] ${start_command} -f ${conf_file} is already unning,exit";exit; }
${start_command} -f ${conf_file} >> ${log_input_path} 2>&1 &
[ $? != 0 ] && { echo "[start] Running ${start_command} -f ${conf_file} Error";exit; }
echo "[startBase] Config file:${start_command} ${conf_file}"
[ -n "$o_pid" ] && { echo "[start] ${start_command} -f ${output_conf} is already unning,exit";exit; }
for i in $(seq ${works});do
${start_command} -f ${output_conf} >> ${log_path} 2>&1 &
done
[ $? != 0 ] && { echo "[start] Running ${start_command} -f ${output_conf} Error";exit; }
echo "[startToElastic] Config file:${start_command} ${output_conf}"
}
function _stop(){
getPid
for i in ${i_pid[@]}
do
kill -9 $i || echo "[stop] Stop php-fpm Error"
sleep 1 && echo "[stop] ${start_command} pid:$i stoped"
done
for i in ${o_pid[@]}
do
kill -9 $i || echo "[stop] Stop php-fpm Error"
sleep 1 && echo "[stop] ${start_command} pid:$i stoped"
done
sleep 1
}
function _check(){
getPid
if [ ! -n "$i_pid" ];then
echo "[check] ${start_command} -f ${conf_file} is already stoped"
else
for i in ${i_pid[@]}
do
echo "[check] ${start_command} -f ${conf_file} is running,pid is $i"
done
fi
if [ ! -n "$o_pid" ];then
echo "[check] ${start_command} -f ${output_conf} is already stoped"
else
for i in ${o_pid[@]}
do
echo "[check] ${start_command} -f ${output_conf} is running,pid is $i"
done
fi
}
function manager()
{
case "$1" in
start)
_start
_check
;;
stop)
_stop
_check
;;
check)
_check
;;
restart)
_check
_stop
_start
_check
;;
*)
printf "Arguments are error!You only set: start|check|stop|restart"
;;
esac
}
conf
if [ "$#" -ne "1" ];then
echo ""
echo "Scripts need parameters,parameters=1"
echo "For example:"
echo "/etc/init.d/${script_name} startAll|startBase|startToElastic|stop|check|restart"
echo "start | 启动需要启动的进程"
echo ""
exit 1
fi
ctrl=$1 && manager ${ctrl}
启动logstash
$systemctl start logstash
七、安装logstash客户端logstash-forwarder发送日志
1 在需要收集的服务器上面安装客户端,收集日志后通过TCP协议传输过去
这里我随便选择一台服务器,例如web1 $rpm -ivh logstash-forwarder-0.4.0-1.x86_64.rpm
2 修改默认配置文件
vim /etc/logstash-forwarder.conf #找到"network",在此作用域中修改 "servers": [ "10.26.215.116:5043" ], "ssl ca": "/etc/pki/tls/certs/logstash-forwarder.crt", "timeout": 15
#找到"files"在此作用域中修改
"files": [
{
"paths": [ "/var/log/message.log"],
"fields": { "type": "logstash" }
},
{
"paths": [ "/data/log/nginx/access.log"],
"fields": { "type": "web1_nginx" }
}
]
3 将elk1服务器的/etc/pki/tls/certs/logstash-forwarder.crt复制到web1
4 启动logstash-forwarder
$/etc/init.d/logstash-forwarder start
八、安装并配置nginx用于http访问
1 nginx安装
$sudo yum -y install epel-release $sudo yum -y install nginx httpd-tools
2 设置用于http访问的权限
#创建kibanaadmin用户,这里会让你输入密码,比如输入123 $sudo htpasswd -c /etc/nginx/htpasswd.users kibanaadmin
3 nginx配置
$vim /etc/nginx/nginx.conf
include /etc/nginx/conf.d/*.conf;
$vim /etc/nginx/conf.d/kibana.conf
server {
listen 80;
server_name example.com;
auth_basic "Restricted Access";
auth_basic_user_file /etc/nginx/htpasswd.users;
location / {
proxy_pass http://localhost:5601;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection 'upgrade';
proxy_set_header Host $host;
proxy_cache_bypass $http_upgrade;
}
}
启动nginx
$sudo systemctl start nginx $sudo systemctl enable nginx
校验各服务是否正常
我们安装好了elk服务,但是如何知道是否安装正确,如何知道数据是否进行了正确传输流向呢
下面就说下几个检查点
一、logstash检查
1 查看logstash-forwarder是否发送日志给logstash服务
[root@test]# tail -f /var/log/logstash-forwarder/logstash-forwarder.err 2016/12/01 21:22:00.856750 Registrar: processing 116 events 2016/12/01 21:22:05.877525 Registrar: processing 100 events # 看到这种就表示连接成功并发送给服务端
2 检查logstash服务端日志是否异常
查看input收集日志情况
$tail -f /var/log/logstash_input.log
{:timestamp=>"2016-12-01T15:54:55.113000+0800", :message=>"Pipeline main started"}
#此处是写入到redis的日志文件,更详细的我们可以登录redis更直观查看是否有数据
$redis-cli -h IP -p 6379
10.24.245.1:6379> LLEN "logstash:redis"
(integer) 10
10.24.245.1:6379> LRANGE "logstash:redis" 1 10 #查看具体内容
查看output连接elasticsearch建立索引情况
$tail -f /var/log/logstash_output.log
{:timestamp=>"2016-12-01T15:54:55.113000+0800", :message=>"Pipeline main started"}
{:timestamp=>"2016-12-01T15:54:57.095000+0800", :message=>"Pipeline main started"}
此处的日志很少,因为我们关闭了处理的详细日志,我们可以通过两种方式来查看详细内容
(1)修改配置文件
vim /etc/logstash/conf2.d/redis-output-bbs.conf
# 这行打开,这样就能在日志里面查看更详细的信息
stdout { codec => rubydebug }
(2)手动启动进程,并调试打印在屏幕
/opt/logstash/bin/logstash -f /etc/logstash/conf2.d/redis-output-bbs.conf -vv
二、查看elasticsearch是否建立索引
1 查看日志
tail -f /data/elasticsearch/log/elasticsearch.log
2 进入elasticsearch数据索引目录,查看是否有索引被创建
$ll -h /data/elasticsearch/elasticsearch/nodes/0/indices/
三、检查kibana
1 可以在命令行直接启动,查看是否有报错信息
$/opt/kibana/bin/kibana
2 http访问kibana, http://example.com
绑定hosts Your_ip example.com

相关优化
这里提到优化主要还是针对单台服务器性能不能满足业务需求和尽可能的将服务器处理日志的能力发挥到最大,如日志量比较大时
由于elk本来就是分布式集群日志分析系统,因此可以将各个功能独立出来,单独服务器运行,避免相互影响
1 关于redis
笔者实验中,先后将各个功能独立出来,其中redis对性能的相互影响最大,因为redis用作消息队列,又是单进程,因此对既读又写时候有瓶颈,且在日志量处理不过来的时候,会堆积到redis里面,所以跟elk放到一起容易导致oom和内存争抢,最要命的是经常导致I/O等待
最后的解决方式:(1)将redis单独运行在一台服务器(2)业务隔离,不同业务日志放入不同的redis实例,多实例多通道充分利用服务器性能
2 关于logstash
logstash在读取收集并写入redis方面貌似并没有太大压力,笔者开启了一个socket用于接收日志,测试中并发写入redis很快,1W条/s的日志量应该都没有问题,就算日志量比较大,可以开多个socket分开传输
3 关于elasticsearch
elk一般用于大量日志分析,因此就不得不做集群,而日志的索引建立查询等操作最终都要回到elasticsearch这里,这会导致它压力非常大,集群可以拥有更好的处理能力,elasticsearch集群非常简单,只需要简单的配置即可
在主节点设置
$vim /etc/elasticsearch/elasticsearch.yml node.name: node-1 node.master: true node.data: true #手动发现节点,可以填写多个节点 discovery.zen.ping.unicast.hosts: [elk1, elk2]
在从节点配置
$vim /etc/elasticsearch/elasticsearch.yml node.name: node-1 node.master: false node.data: true
参考:
http://www.tuicool.com/articl... elasticsearch配置
https://www.elastic.co/guide/... logstash官方文档
https://www.elastic.co/guide/... elasticsearch官方文档
正文到此结束
- 本文标签: json node description DigitalOcean 安装 下载 java 需求 编译 REST https 压力 统计 数据 Master PHP 实例 端口 grep 开源 centos http 目录 API ssl list git 进程 src 调试 IO web Document rpm tar 百度 集群 主机 linux 管理 tail -f 服务器 key awk 线程 example UI cache apache TCP 测试 总结 搜索引擎 进程数 IDE id Nginx 消息队列 ip Oracle Connection 配置 message wget 时间 协议 js 参数 cat php-fpm redis 服务端 root
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

