Etcd 架构与实现解析
前一段时间的项目里用到了 Etcd, 所以研究了一下它的源码以及实现。网上关于 Etcd 的使用介绍的文章不少,但分析具体架构实现的文章不多,同时 Etcd v3的文档也非常稀缺。本文通过分析 Etcd 的架构与实现,了解其优缺点以及瓶颈点,一方面可以学习分布式系统的架构,另外一方面也可以保证在业务中正确使用 Etcd,知其然同时知其所以然,避免误用。最后介绍 Etcd 周边的工具和一些使用注意事项。
阅读对象:分布式系统爱好者,正在或者打算在项目中使用Etcd的开发人员。
Etcd按照官方介绍
Etcd is a distributed, consistent key-value store for shared configuration and service discovery
是一个分布式的,一致的 key-value 存储,主要用途是共享配置和服务发现。Etcd 已经在很多分布式系统中得到广泛的使用,本文的架构与实现部分主要解答以下问题:
-
Etcd是如何实现一致性的?
-
Etcd的存储是如何实现的?
-
Etcd的watch机制是如何实现的?
-
Etcd的key过期机制是如何实现的?
为什么需要 Etcd ?
所有的分布式系统,都面临的一个问题是多个节点之间的数据共享问题,这个和团队协作的道理是一样的,成员可以分头干活,但总是需要共享一些必须的信息,比如谁是 leader, 都有哪些成员,依赖任务之间的顺序协调等。所以分布式系统要么自己实现一个可靠的共享存储来同步信息(比如 Elasticsearch ),要么依赖一个可靠的共享存储服务,而 Etcd 就是这样一个服务。
Etcd 提供什么能力?
Etcd 主要提供以下能力,已经熟悉 Etcd 的读者可以略过本段。
-
提供存储以及获取数据的接口,它通过协议保证 Etcd 集群中的多个节点数据的强一致性。用于存储元信息以及共享配置。
-
提供监听机制,客户端可以监听某个key或者某些key的变更(v2和v3的机制不同,参看后面文章)。用于监听和推送变更。
-
提供key的过期以及续约机制,客户端通过定时刷新来实现续约(v2和v3的实现机制也不一样)。用于集群监控以及服务注册发现。
-
提供原子的CAS(Compare-and-Swap)和 CAD(Compare-and-Delete)支持(v2通过接口参数实现,v3通过批量事务实现)。用于分布式锁以及leader选举。
更详细的使用场景不在这里描述,有兴趣的可以参看文末infoq的一篇文章。
Etcd 如何实现一致性的?
说到这个就不得不说起raft协议。但这篇文章不是专门分析raft的,篇幅所限,不能详细分析,有兴趣的建议看文末原始论文地址以及raft协议的一个动画。便于看后面的文章,我这里简单做个总结:
-
raft通过对不同的场景(选主,日志复制)设计不同的机制,虽然降低了通用性(相对paxos),但同时也降低了复杂度,便于理解和实现。
-
raft内置的选主协议是给自己用的,用于选出主节点,理解raft的选主机制的关键在于理解raft的时钟周期以及超时机制。
-
理解 Etcd 的数据同步的关键在于理解raft的日志同步机制。
Etcd 实现raft的时候,充分利用了go语言CSP并发模型和chan的魔法,想更进行一步了解的可以去看源码,这里只简单分析下它的wal日志。

wal日志是二进制的,解析出来后是以上数据结构LogEntry。其中第一个字段type,只有两种,一种是0表示Normal,1表示ConfChange(ConfChange表示 Etcd 本身的配置变更同步,比如有新的节点加入等)。第二个字段是term,每个term代表一个主节点的任期,每次主节点变更term就会变化。第三个字段是index,这个序号是严格有序递增的,代表变更序号。第四个字段是二进制的data,将raft request对象的pb结构整个保存下。Etcd 源码下有个tools/etcd-dump-logs,可以将wal日志dump成文本查看,可以协助分析raft协议。
raft协议本身不关心应用数据,也就是data中的部分,一致性都通过同步wal日志来实现,每个节点将从主节点收到的data apply到本地的存储,raft只关心日志的同步状态,如果本地存储实现的有bug,比如没有正确的将data apply到本地,也可能会导致数据不一致。
Etcd v2 与 v3
Etcd v2 和 v3 本质上是共享同一套 raft 协议代码的两个独立的应用,接口不一样,存储不一样,数据互相隔离。也就是说如果从 Etcd v2 升级到 Etcd v3,原来v2 的数据还是只能用 v2 的接口访问,v3 的接口创建的数据也只能访问通过 v3 的接口访问。所以我们按照 v2 和 v3 分别分析。
Etcd v2 Watch,以及过期机制
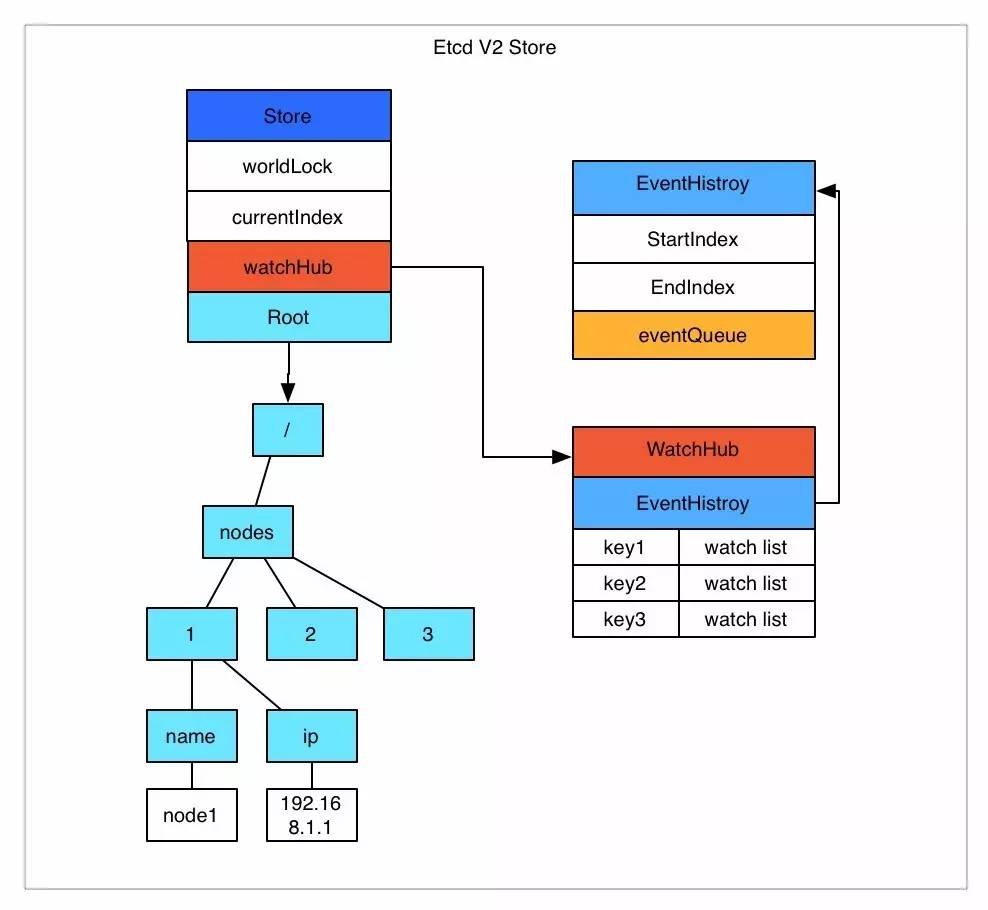
Etcd v2 是个纯内存的实现,并未实时将数据写入到磁盘,持久化机制很简单,就是将store整合序列化成json写入文件。数据在内存中是一个简单的树结构。比如以下数据存储到 Etcd 中的结构就如图所示。
/nodes/1/name node1 /nodes/1/ip 192.168.1.1
store中有一个全局的currentIndex,每次变更,index会加1.然后每个event都会关联到currentIndex.
当客户端调用watch接口(参数中增加 wait参数)时,如果请求参数中有waitIndex,并且waitIndex 小于 currentIndex,则从 EventHistroy 表中查询index小于等于waitIndex,并且和watch key 匹配的 event,如果有数据,则直接返回。如果历史表中没有或者请求没有带 waitIndex,则放入WatchHub中,每个key会关联一个watcher列表。 当有变更操作时,变更生成的event会放入EventHistroy表中,同时通知和该key相关的watcher。
这里有几个影响使用的细节问题:
-
EventHistroy 是有长度限制的,最长1000。也就是说,如果你的客户端停了许久,然后重新watch的时候,可能和该waitIndex相关的event已经被淘汰了,这种情况下会丢失变更。
-
如果通知watch的时候,出现了阻塞(每个watch的channel有100个缓冲空间),Etcd 会直接把watcher删除,也就是会导致wait请求的连接中断,客户端需要重新连接。
-
Etcd store的每个node中都保存了过期时间,通过定时机制进行清理。
从而可以看出,Etcd v2 的一些限制:
-
过期时间只能设置到每个key上,如果多个key要保证生命周期一致则比较困难。
-
watch只能watch某一个key以及其子节点(通过参数 recursive),不能进行多个watch。
-
很难通过watch机制来实现完整的数据同步(有丢失变更的风险),所以当前的大多数使用方式是通过watch得知变更,然后通过get重新获取数据,并不完全依赖于watch的变更event。
Etcd v3 存储,Watch,以及过期机制
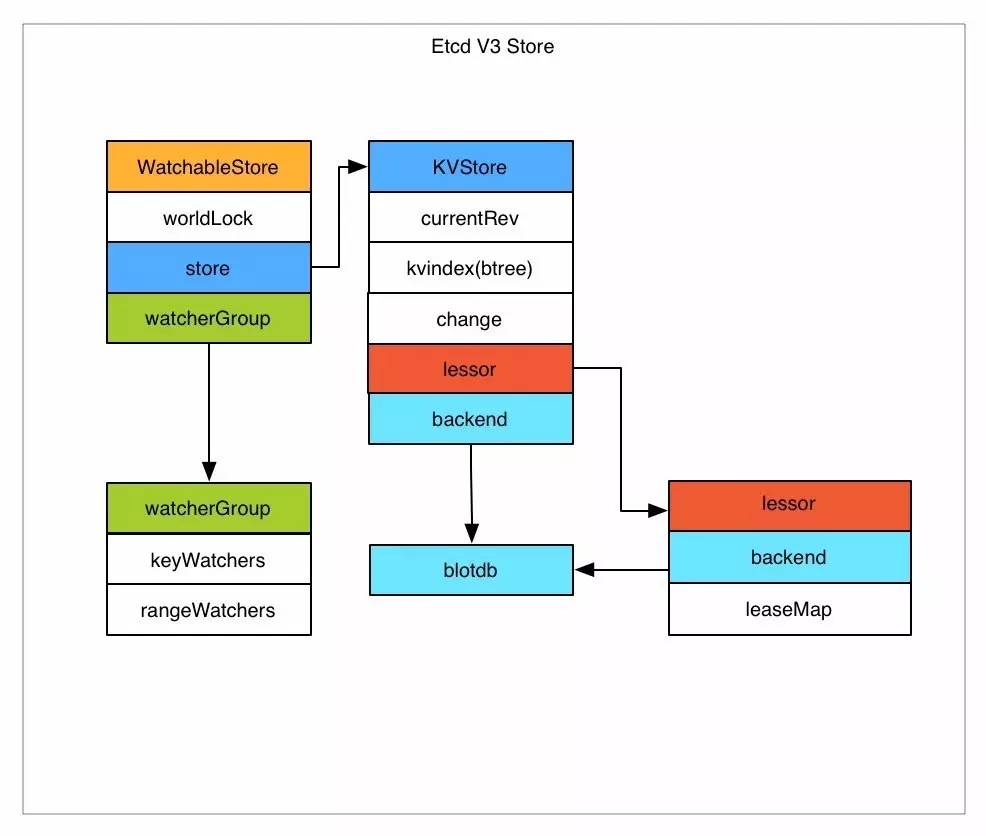
Etcd v3 将watch和store拆开实现,我们先分析下store的实现。
Etcd v3 store 分为两部分,一部分是内存中的索引,kvindex,是基于google开源的一个golang的btree实现的,另外一部分是后端存储。按照它的设计,backend可以对接多种存储,当前使用的boltdb。boltdb是一个单机的支持事务的kv存储,Etcd 的事务是基于boltdb的事务实现的。Etcd 在boltdb中存储的key是reversion,value是 Etcd 自己的key-value组合,也就是说 Etcd 会在boltdb中把每个版本都保存下,从而实现了多版本机制。
举个例子: 用etcdctl通过批量接口写入两条记录:
etcdctl txn <<<' put key1 "v1" put key2 "v2" '
再通过批量接口更新这两条记录:
etcdctl txn <<<' put key1 "v12" put key2 "v22" '
boltdb中其实有了4条数据:
rev={3 0}, key=key1, value="v1"
rev={3 1}, key=key2, value="v2"
rev={4 0}, key=key1, value="v12"
rev={4 1}, key=key2, value="v22"
reversion主要由两部分组成,第一部分main rev,每次事务进行加一,第二部分sub rev,同一个事务中的每次操作加一。如上示例,第一次操作的main rev是3,第二次是4。当然这种机制大家想到的第一个问题就是空间问题,所以 Etcd 提供了命令和设置选项来控制compact,同时支持put操作的参数来精确控制某个key的历史版本数。
了解了 Etcd 的磁盘存储,可以看出如果要从boltdb中查询数据,必须通过reversion,但客户端都是通过key来查询value,所以 Etcd 的内存kvindex保存的就是key和reversion之前的映射关系,用来加速查询。
然后我们再分析下watch机制的实现。Etcd v3 的watch机制支持watch某个固定的key,也支持watch一个范围(可以用于模拟目录的结构的watch),所以 watchGroup 包含两种watcher,一种是 key watchers,数据结构是每个key对应一组watcher,另外一种是 range watchers, 数据结构是一个 IntervalTree(不熟悉的参看文文末链接),方便通过区间查找到对应的watcher。
同时,每个 WatchableStore 包含两种 watcherGroup,一种是synced,一种是unsynced,前者表示该group的watcher数据都已经同步完毕,在等待新的变更,后者表示该group的watcher数据同步落后于当前最新变更,还在追赶。
当 Etcd 收到客户端的watch请求,如果请求携带了revision参数,则比较请求的revision和store当前的revision,如果大于当前revision,则放入synced组中,否则放入unsynced组。同时 Etcd 会启动一个后台的goroutine持续同步unsynced的watcher,然后将其迁移到synced组。也就是这种机制下,Etcd v3 支持从任意版本开始watch,没有v2的1000条历史event表限制的问题(当然这是指没有compact的情况下)。
另外我们前面提到的,Etcd v2在通知客户端时,如果网络不好或者客户端读取比较慢,发生了阻塞,则会直接关闭当前连接,客户端需要重新发起请求。Etcd v3为了解决这个问题,专门维护了一个推送时阻塞的watcher队列,在另外的goroutine里进行重试。
Etcd v3 对过期机制也做了改进,过期时间设置在lease上,然后key和lease关联。这样可以实现多个key关联同一个lease id,方便设置统一的过期时间,以及实现批量续约。
相比Etcd v2, Etcd v3的一些主要变化:
-
接口通过grpc提供rpc接口,放弃了v2的http接口。优势是长连接效率提升明显,缺点是使用不如以前方便,尤其对不方便维护长连接的场景。
-
废弃了原来的目录结构,变成了纯粹的kv,用户可以通过前缀匹配模式模拟目录。
-
内存中不再保存value,同样的内存可以支持存储更多的key。
-
watch机制更稳定,基本上可以通过watch机制实现数据的完全同步。
-
提供了批量操作以及事务机制,用户可以通过批量事务请求来实现Etcd v2的CAS机制(批量事务支持if条件判断)。
Etcd,Zookeeper,Consul 比较
这三个产品是经常被人拿来做选型比较的。 Etcd 和 Zookeeper 提供的能力非常相似,都是通用的一致性元信息存储,都提供watch机制用于变更通知和分发,也都被分布式系统用来作为共享信息存储,在软件生态中所处的位置也几乎是一样的,可以互相替代的。二者除了实现细节,语言,一致性协议上的区别,最大的区别在周边生态圈。Zookeeper 是apache下的,用java写的,提供rpc接口,最早从hadoop项目中孵化出来,在分布式系统中得到广泛使用(hadoop, solr, kafka, mesos 等)。Etcd 是coreos公司旗下的开源产品,比较新,以其简单好用的rest接口以及活跃的社区俘获了一批用户,在新的一些集群中得到使用(比如kubernetes)。虽然v3为了性能也改成二进制rpc接口了,但其易用性上比 Zookeeper 还是好一些。 而 Consul 的目标则更为具体一些,Etcd 和 Zookeeper 提供的是分布式一致性存储能力,具体的业务场景需要用户自己实现,比如服务发现,比如配置变更。而Consul 则以服务发现和配置变更为主要目标,同时附带了kv存储。 在软件生态中,越抽象的组件适用范围越广,但同时对具体业务场景需求的满足上肯定有不足之处。
Etcd 的周边工具
-
Confd
在分布式系统中,理想情况下是应用程序直接和 Etcd 这样的服务发现/配置中心交互,通过监听 Etcd 进行服务发现以及配置变更。但我们还有许多历史遗留的程序,服务发现以及配置大多都是通过变更配置文件进行的。Etcd 自己的定位是通用的kv存储,所以并没有像 Consul 那样提供实现配置变更的机制和工具,而 Confd 就是用来实现这个目标的工具。
Confd 通过watch机制监听 Etcd 的变更,然后将数据同步到自己的一个本地存储。用户可以通过配置定义自己关注那些key的变更,同时提供一个配置文件模板。Confd 一旦发现数据变更就使用最新数据渲染模板生成配置文件,如果新旧配置文件有变化,则进行替换,同时触发用户提供的reload脚本,让应用程序重新加载配置。
Confd 相当于实现了部分 Consul 的agent以及consul-template的功能,作者是kubernetes的Kelsey Hightower,但大神貌似很忙,没太多时间关注这个项目了,很久没有发布版本,我们着急用,所以fork了一份自己更新维护,主要增加了一些新的模板函数以及对metad后端的支持。
-
Metad
服务注册的实现模式一般分为两种,一种是调度系统代为注册,一种是应用程序自己注册。调度系统代为注册的情况下,应用程序启动后需要有一种机制让应用程序知道『我是谁』,然后发现自己所在的集群以及自己的配置。Metad 提供这样一种机制,客户端请求 Metad 的一个固定的接口 /self,由 Metad 告知应用程序其所属的元信息,简化了客户端的服务发现和配置变更逻辑。
Metad 通过保存一个ip到元信息路径的映射关系来做到这一点,当前后端支持Etcd v3,提供简单好用的 http rest 接口。 它会把 Etcd 的数据通过watch机制同步到本地内存中,相当于 Etcd 的一个代理。所以也可以把它当做Etcd 的代理来使用,适用于不方便使用 Etcd v3的rpc接口或者想降低 Etcd 压力的场景。
-
Etcd 集群一键搭建脚本
Etcd 官方那个一键搭建脚本有bug,我自己整理了一个脚本,通过docker的network功能,一键搭建一个本地的 Etcd 集群便于测试和试验。一键搭建脚本
Etcd 使用注意事项
-
Etcd cluster 初始化的问题
如果集群第一次初始化启动的时候,有一台节点未启动,通过v3的接口访问的时候,会报告Error: Etcdserver: not capable 错误。这是为兼容性考虑,集群启动时默认的API版本是2.3,只有当集群中的所有节点都加入了,确认所有节点都支持v3接口时,才提升集群版本到v3。这个只有第一次初始化集群的时候会遇到,如果集群已经初始化完毕,再挂掉节点,或者集群关闭重启(关闭重启的时候会从持久化数据中加载集群API版本),都不会有影响。
-
Etcd 读请求的机制
v2 quorum=true 的时候,读取是通过raft进行的,通过cli请求,该参数默认为true。 v3 –consistency=“l” 的时候(默认)通过raft读取,否则读取本地数据。sdk 代码里则是通过是否打开:WithSerializable option 来控制。
一致性读取的情况下,每次读取也需要走一次raft协议,能保证一致性,但性能有损失,如果出现网络分区,集群的少数节点是不能提供一致性读取的。但如果不设置该参数,则是直接从本地的store里读取,这样就损失了一致性。使用的时候需要注意根据应用场景设置这个参数,在一致性和可用性之间进行取舍。
-
Etcd 的compact机制
Etcd 默认不会自动compact,需要设置启动参数,或者通过命令进行compcat,如果变更频繁建议设置,否则会导致空间和内存的浪费。
脑洞时间
自动上次 Elasticsearch 的文章之后,给自己安排了一个作业,每次分析源码后需要提出几个发散思维的想法,开个脑洞。
-
并发代码调用分析追踪工具
当前IDE的代码调用分析追踪都是通过静态的代码分析来追踪方法调用链实现的,对阅读分析代码非常有用。但程序如果充分使用CSP或者Actor模型后,都通过消息进行调用,没有了明确的方法调用链,给阅读和理解代码带来了困难。如果语言或者IDE能支持这样的消息投递追踪分析,那应该非常有用。当然我这个只是脑洞,不考虑实现的可能性和复杂度。
-
实现一个通用的 multiple group raft库
当前 Etcd 的raft实现保证了多个节点数据之间的同步,但明显的一个问题就是扩充节点不能解决容量问题。要想解决容量问题,只能进行分片,但分片后如何使用raft同步数据?只能实现一个 multiple group raft,每个分片的多个副本组成一个虚拟的raft group,通过raft实现数据同步。当前实现了multiple group raft的有 TiKV 和 Cockroachdb,但尚未一个独立通用的。理论上来说,如果有了这套 multiple group raft,后面挂个持久化的kv就是一个分布式kv存储,挂个内存kv就是分布式缓存,挂个lucene就是分布式搜索引擎。当然这只是理论上,要真实现复杂度还是不小。
Etcd 的开源产品启示
Etcd在Zookeeper已经奠定江湖地位的情况下,硬是重新造了一个轮子,并且在生态圈中取得了一席之地。一方面可以看出是社区的形态在变化,沟通机制和对用户反馈的响应越来越重要,另外一方面也可以看出一个项目的易用的重要性有时候甚至高于稳定性和功能。新的算法,新的语言都会给重新制造轮子带来了机会。
gitchat交流群的问答
问:业务使用的etcd v2 升级到 v3 会有什么问题呢,如何平滑过渡?
答:v2的大多数功能,用v3都能实现,比如用prefix模拟原来的目录结构,用txn模拟CAS,一般不会有什么问题。但因为v2和v3的数据是互相隔离的,所以迁移起来略麻烦。建议先在业务中封装一层,将etcd v2,v3的差异封装起来,然后通过开关切换。
问:metad的watch是怎么实现的?
答:metad的watch实现的比较简单,因为metad的watch返回的不是变更事件,而是最新的结果。所以metad只维护了一个全局版本号,只要发现客户端watch的版本小于等于全局版本号,就直接返回最新结果。
问:etcd和zk都是作为分布式配置管理的组件。均提供了watch功能,选主。作为初使用者,这两个之间的选取该如何?
etcd和zk二者大多数情况下可以互相替代,都是通用的分布式一致性kv存储。二者之间选择建议选择自己的开发栈比较接近并且团队成员比较熟悉的,比如一种是按语言选择,go语言的项目用etcd,java的用zk,出问题要看源码也容易些。如果是新项目,纠结于二者,那可以分装一层lib,类似于docker/libkv,同时支持两种,有需要可以切换。
问:etcd和eureka、consul 的异同,以及各自的适用场景,以及选型原则。这个问题其实可以把zk也包括进来,这些都有相同之处。
答:etcd和zk的选型前面讲到了,二者的定位都是通用的一致性kv存储,而eureka和consul的定位则是专做服务注册和发现。前二者的优势当然是通用性,应用广泛,部署运维的时候容易和已有的服务一起共用,而同时缺点也是太通用了,每个应用的服务注册都有自己的一套元数据格式,互相整合起来就比较麻烦了,比如想做个通用的api gateway就会遇到元数据格式兼容问题。这也成为后二者的优势。同时因为后二者的目标比较具体,所以可以做一些更高级的功能,比如consul的DNS支持,consul-template工具,eureka的事件订阅过滤机制。Eureka本身的实现是一个AP系统,也就是说牺牲了一致性,它认为在服务发现和配置中心这个场景下,可用性和分区容错比一致性更重要。 我个人其实更期待后二者的这种专门的解决方案,要是能形成服务注册标准,那以后应用之间互相交互就容易了。但也有个可能是这种标准由集群调度系统来形成事实标准。
后二者我了解的也不深入,感觉可以另起一篇文章了。
问:接上面,etcd和zk各自都有哪些坑可能会被踩到,都有多坑。掉进去了如何爬起来?
答:这个坑的概念比较太广泛了,更详细的可以翻bug列表。但使用中的大多数坑一般有几种:
-
误用导致的坑。要先认识清楚etcd,zk的定位,它需要保存的是整个集群共享的信息,不能当存储用。比如有人在某个zk的某个数据节点下创建了大量的子节点,然后获取,导致zk报错,zk的buffer有个4mb的限制,超过就会报错。
-
运维方面的坑。etcd,zk这种服务,一般都比较稳定,搭建好后都不用管,但万一某些节点出问题了,要增加节点恢复系统的时候,可能没有预案或者操作经验,导致弄坏集群。
-
网络分区以及可用性设计的坑。设计系统的时候,要想清楚如果etcd或zk整个挂了,或者出现网络分区,应用的一部分节点只能连接到少数派的etcd/zk(少数派不可用)的时候,应用会有什么表现。这种情况下,应用的正确表现应该是服务正常运作,但不支持变更,等etcd/zk集群恢复后就自动恢复了。但如果设计不当,有自动化的一些行为,可能带来的故障就大了。
想要少踩坑,一个办法就是我文中提到的,研究原理知其然同时知其所以然,另外一个问题就是多试验,出了问题有预案。
问:一个实验性质的硬件集群项目的几个问题
我们实现了基于Arm的分布式互联的硬件集群(方法参考的是https://edcashin.wordpress.com/2013/12/29/trying-etcd-on-android-mac-and-raspberry-pi/comment-page-1/ 将etcd跑在Arm开发板上),将Etcd当作一个分布式的数据库使用(但是Etcd本身运行在这些硬件之上),然后参考go-rpiohttps://github.com/stianeikeland/go-rpio 实现基于etcd的key-value同步硬件的信息,控制某些GPIO。
问题1:目前已知Etcd可以为别的服务提供服务发现,在这个场景下假设已经存在5个运行Etcd节点的硬件,当一个新的Etcd硬件节点被安装时,Etcd能否为自己提供服务发现服务,实现Etcd节点的自动发现与加入?
问题2:随着硬件安装规模的增加,Etcd的极限是多少,raft是否会因为节点的变多,心跳包的往返而导致同步一次的等待时间变长?
问题3:当规模足够大,发生网络分区时,是否分区较小的一批硬件之间的数据是无法完成同步的?
答:这个案例挺有意思,我一个一个回答。
-
etcd本来是做服务发现的,如果etcd集群也需要服务发现,那就再来一个etcd集群 :)。你可以自己搭建一个etcd cluster或者用etcd官方提供的 discovery.etcd.io。详细参看:etcd 官方的 op-guide/clustering
-
etcd的机制是多节点一致的,所以它的极限有两部分,一是单机的容量限制,内存和磁盘。二是网络开销,每次raft操作需要所有节点参与,节点越多性能越低。所以扩展很多etcd节点是没有意义的,一般是 3,5,7,9。再多感觉就没意义了。如果你们不太在意一致性,建议读请求可以不通过一致性协议,直接读取节点本地数据。具体方式文中有说明。
-
etcd网络分区时,少数派是不可用状态,不支持raft请求,但支持非一致性读请求。
问:如果跨机房部署服务,是部署两套ETCD吗?如果跨机房部署,如何部署及配置?
答:这个要看跨机房的场景。如果是完全无关联需要公网连接的两个机房,服务之间一般也不需要共享数据吧?部署两套互不相干的etcd,各用各的比较合适。但如果是类似于aws的可用区的概念,两个机房内网互通,搭建两套集群为了避免机房故障,可以随时切换。这个etcd当前没有太好的解决办法,建议的办法是跨可用区部署一个etcd cluster,调整心跳以及选举超时时间,这个办法如果有3个可用区机房,每个机房3个节点,挂任何一个机房都不影响整个集群,但两个机房就比较尴尬。还有个办法是两个集群之间同步,这个etcdv3提供了一个mirror的工具,但还是不太完善,不过感觉用etcd的watch机制做一个同步工具也不难。这个机制consul倒是提供了,多数据中心的集群数据同步,互相不影响可用性。
相关链接 (微信不支持链接,点击查看原文获取)
-
raft官网 有论文地址以及相关资料。
-
raft动画演示 看了这个动画就懂raft了。
-
Interval_tree
-
etcd:从应用场景到实现原理的全方位解读 这篇文章对使用场景描述的比较全面。
-
confd 我们修改版的confd仓库地址。
-
metad 仓库地址。
-
etcd集群一键搭建脚本
-
并发之痛 Thread,Goroutine,Actor 本人关于并发模型的一篇文章,有利于理解文章内提到的CSP模型。

扫码关注 @谢工 的新项目gitchat。本文最初在gitchat上分享,并在付费交流群中进行交流。本文原计划10月份发布,结果一拖再拖,在gitchat上发布题目后,订阅达标,才在gitchat编辑的『监督』下完成。 感谢gitchat提供这样的知识分享平台。
正文到此结束
- 本文标签: 开源 core Go语言 源码 js 搜索引擎 管理 CTO value 总结 src Clustering 测试 https cat IDE 空间 key 锁 lib 文章 协议 git 产品 数据 时间 Docker 开发 dist Word id apache ip 压力 UI 需求 json 参数 solr 生命 长连接 java 自动化 数据库 配置 代码 解析 REST 详细分析 删除 IO 目录 db swap 安装 GitHub Kubernetes Eureka Uber http ORM wordpress node zookeeper Google Android 同步 主机 Service Hadoop DNS 集群 API App 软件
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

