深度学习在图像取证领域中的进展
雷锋网 (公众号:雷锋网) 按:本文作者杨朋朋,就读于北京交通大学,信号与信息处理专业博士生二年级,导师倪蓉蓉教授。研究兴趣包括多媒体取证、隐写分析,深度学习。所在团队为教育部创新团队和科技部重点领域创新团队,负责人为赵耀教授。
图像取证
在当今飞速发展的信息时代,数字图像已经渗透到社会生活的每一个角落,数字图像的广泛使用也促进了数字图像编辑软件的开发与应用,例如:Adobe Photoshop、CorelDRAW、美图秀秀等等。利用这些编辑工具,用户可以随意对图像进行修改,从而达到更好的视觉效果。然而,在方便了用户的同时,也给一些不法分子以可乘之机。在未经授权的情况下,不法分子对图像内容进行非法操作,如违规编辑、合成虚假图像等,从而造成篡改图像在人们社会生活中泛滥成灾。图像取证技术就是在这样的背景下提出,旨在 通过盲分析手段认证图像数据的原始性和真实性、鉴别和分析图像所经历的操作处理及估计图像的操作历史。
数字图像的完整周期包含三个部分: 图像获取、图像编码、图像编辑 ,如图1所示。
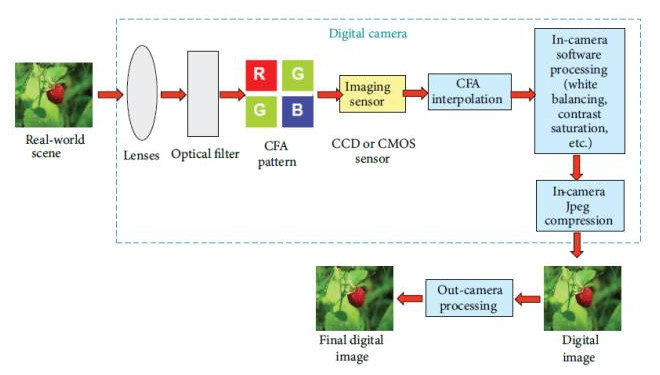
图1. 数字图像的完整周期
在 图像获取 过程中,真实场景中的光线通过相机镜头投射到相机传感器(如CCD或者CMOS传感器),产生数字图像信号。在投射到相机传感器之前,通常光首先经过CFA滤波处理,即每个像素点只会包含一种主要的颜色分量(红、绿、蓝)。在相机传感器之后会进行CFA差值(也称去马赛克处理),从而获取每个像素点的红绿蓝三通道分量。然后获取的数字图像信号会经历相机内部的软件处理,比如白平衡、对比度增强、图像锐化、伽马矫正等等。
在 图像编码 部分,经过处理后的数字图像信号为了节省相机内存通常会经过有失真压缩处理,最常见的压缩方式为JPEG压缩。部分压缩后的数字图像为了获得更好的视觉效果会进行后处理操作,任何的 图像编辑 都可以应用在后处理操作,经常使用的编辑为:几何变换(旋转、缩放等)、模糊、锐化、对比度调整、图像拼接、复制-粘贴。经过编辑后的数字图像重新保存为JPEG格式形成最终的数字图像。
数字图像取证的出发点是通过提取数字图像周期中留下的固有痕迹进行分析和理解数字图像的操作历史。以上介绍的数字图像完整周期的三个部分,每一部分都会留下不同的操作痕迹(指纹特性),即 获取指纹、编码指纹、编辑指纹 。在图像获取指纹研究中,根据镜头特性、传感器特性、CFA模式等引入数字图像中的不同指纹特性对数字图像进行分析。在图像编码指纹研究中,JPEG压缩以及多重JPEG压缩检测是主要关注的问题。在图像编辑指纹特性研究中,基于信号处理和基于物理/几何的技术被提出。利用信号处理技术进行复制粘贴检测、重采样检测、对比度增强检测、线裁剪检测等,利用光线/阴影进行拼接检测以及利用几何关系的一致性检测拼接处理都是取证研究中的热点问题。
图像取证深度学习之风
不同于传统的图像取证算法,深度学习算法将特征提取和特征分类整合到一个网络结构中,实现了一种end-to-end的自动特征学习分类的有效算法。从当前的研究工作来看,深度学习应用于图像取证领域大致可分为三个层次。
第一个层次是简单的迁移,即直接将CV领域常用的CNN网络结构引入到图像取证领域。取证领域比较常用的网络结构为AlexNet,选择此网络结构的原因,是因为AlexNet网络结构相较于其他网络结构复杂度相对较低并且性能较好,对于解决数据集少的取证问题有更好的尝试性条件。典型案例为Luca Baroffio, Luca Bond等发表的文章“Camera Identification With Deep Convolutional Networks”, 文章提出用深度学习解决取证中的相机源辨别问题。
第二个层次是尝试对网络输入的修改,进行此种尝试的初衷是由取证问题和CV问题的本质区别所驱使。取证问题虽可归类于识别、分类、定位问题,但是对于分类问题的类间差别取证分类问题远小于CV分类问题。举个例子:ImageNet中的22000种类别之间的形态差异是较大的,比如猫和狗两个类别之间的差异人眼可辨别;然而对于取证问题,类别之间的形态差异是极其微小的,类间差别以微弱信号的形式存在;比如对于常见的双重JPEG压缩取证,需要解决的问题是区分一幅图像是经历过一次JPEG压缩之后的图像,还是经历过两次JPEG压缩之后的图像。在两次压缩使用的压缩因子(压缩因子小于等于90)一致的前提条件下,内容相同的两幅图像的DCT域统计类间差别小于0.4%(数据来源于Detecting Double JPEG Compression With the Same Quantization Matrix)。
基于取证问题的此种特性,研究者尝试对网络的输入进行改进,添加预处理层(或信号增强层)放大类间差别,此种尝试取得较好的检测效果。典型案例为Jiansheng Chen, Xiangui Kang等发表的文章“Median Filtering Forensics Based on Convolutional Neural Networks”,根据论文报告的试验结果,预处理层的添加对检测准确率有了7.22个百分点的提升。
第三个层次是对网络结构的修改,结合取证的实际问题提出适合于取证问题的网络结构。典型案例为Belhassen Bayar, Matthew C. Stamm发表的文章“A Deep Learning Approach To Universal Image Manipulation Detection Using A New Convolutional Layer”。
下面针对于不同的取证问题介绍深度学习的应用。据我们所知,到目前为止,深度学习应用于取证领域的工作共有5篇,涉及到了取证问题中的相机源取证、中值滤波取证、重获取图像取证以及反反取证。
1.相机源取证
相机源取证研究的问题在于如何有效区分图像采集所使用的设备型号或模式,相机源取证可以在一定程度上解决图像版权问题,例如一副具有版权保护的图像未经过作者授权被重新拍摄并发布,可以利用相机源取证技术区分图像是由原始相机拍摄还是其他相机拍摄,从而判断图像版权所属。
不同厂商生产的数码相机之间存在着差异,相同厂商生产的不同型号的数码相机之间也存在着差异,已有的传统方案通过提取不同的相机存在的指纹特性实现对相机源的取证。Luca Baroffio, Luca Bond等人首次提出利用卷积神经网络的方法解决相机源取证问题。文章所使用的网络结构参数如图2所示。该结构使用了三个卷积层和两个全连接层的结构,网络结构与AlexNet结构相似。根据文章报告的实验结果,在相机源取证的benchmark库中测试,对于27种相机模式分类的准确率在94%以上。
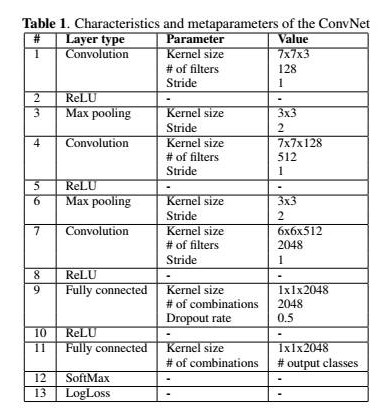
图2. 基于深度学习的相机源取证算法网络结构参数
2.中值滤波图像取证
中值滤波图像取证问题一直被图像取证领域所关注,取证目的是对图像是否经历过中值滤波操作进行判定。在图像经过篡改之后,为了去除篡改引入图像中的特性,通常会对图像进行中值滤波操作,从而隐藏篡改操作痕迹。图像是否经历过中值滤波操作对于判断图像篡改历史提供了重要线索。传统的图像中值滤波取证算法对于小尺寸图像和做过压缩后处理的图像性能有待提高。
Jiansheng Chen, Xiangui Kang等人首次提出利用深度学习解决中值滤波取证问题,该工作发表在Signal Processing Letters IEEE, 2015。与此同时,这也是深度学习应用在取证领域的第一个工作,为后续深度学习在取证领域的发展起到了重要的借鉴作用。该工作对网络的输入图像做了预处理操作:
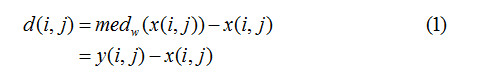
x(i , j)表示原始图像, medw(.)表示中值滤波操作,其中中值滤波窗口大小为w,d(i , j), 代表中值滤波图像与原始图像的差值图像。做这样预处理的动机来源于之前传统方案的设计。通过预处理操作,去除图像内容对检测性能的影响同时也起到了放大图像噪声信号的作用。预处理操作的效果图如图3所示:

图3. 原始图像、差值图像、中值滤波图像与原始图像的差分图像示例展示
(a)(b)(c)三幅图像分布代表原始图像,差值图像以及中值滤波与原始图像的差值图像。从图3(c)中可以看出中值滤波后的差值图像中对原始图像内容的反映几乎去除。
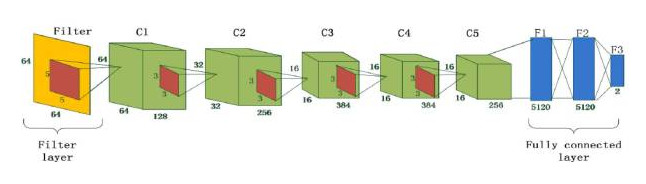
图4. 中值滤波深度网络结构图
图4中展示了该工作提出的网络结构示意图。滤波层实现的是式(1)的操作,紧接着的网络结构与AlexNet结构类似,5个卷积层以及3个全连接层。根据文章中报告的实验结果,对于压缩的小尺寸图像(64x64、32x32)该方法实现了最好的检测准确率。为了测试滤波层的作用,作者在使用滤波层和不使用两种情况下进行了对比实验,实验结果显示滤波层对于检测准确率有7.22个百分点的提升。
基于Jiansheng Chen, Xiangui Kang等人的工作,Belhassen Bayar,Matthew C. Stamm提出一种新的卷积结构。作者尝试利用新的卷积结构捕获图像操作过程中引入的图像临近像素之间相关关系的变化,于此同时尽可能压缩图像内容对于图像操作引入的像素相关关系的影响。为了实现这样的卷积结构设计,作者对卷积核的属性进行了限制,使得网络结构可以自动学习预测误差滤波器集合,从而抑制图像内容的影响同时捕获操作特性。限制条件如公式(2)所示:
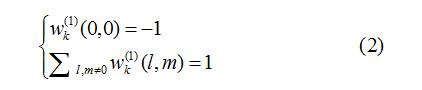
w为新的卷积核,w(0,0)为卷积核中心位置的数值。新的卷积结构只使用在第一层卷积中,从而实现图像预处理卷积核的自动学习。图5、图6分别展示了新的卷积结构和文章提出的网络结构图。
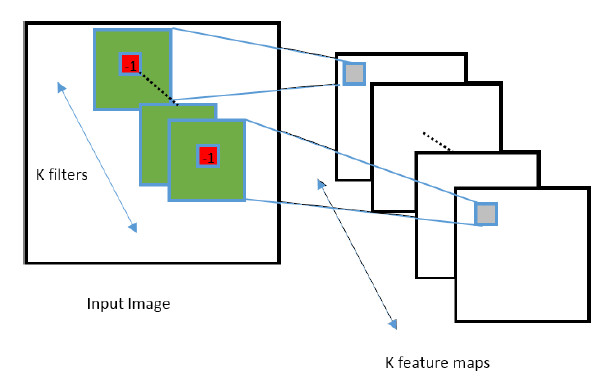
图5. 新卷积结构图示 固定卷积核中心位置数值为-1同时周围位置数值之和为1
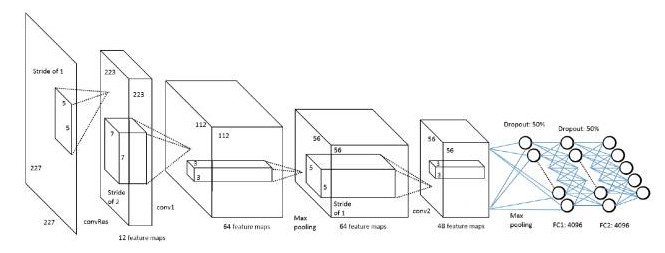
图6. 新卷积算法网络结构图
3.重获取图像取证
重获取图像取证近几年开始受到取证工作者的关注。 重获取操作是指原始图像被投影到新的媒介后被再次获取的过程。 图7展示了常见的图像重获取操作流程。原始图像首先被投影到新得到媒介:电脑屏幕、手机屏幕、打印纸,然后对投影后的图像进行重新拍摄,形成重获取图像。
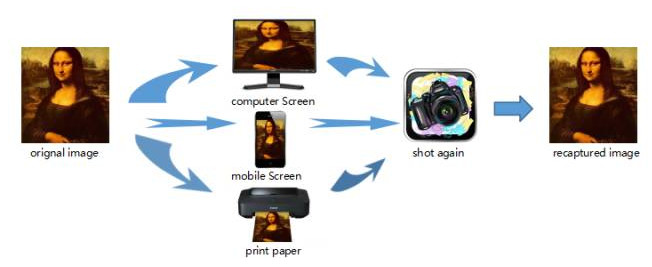
图7 图像重获取操作流程图
重获取图像取证有重要的研究价值, 对于篡改操作后的图像通常会在图像中留下指纹性的操作痕迹,消除这些痕迹的最简单的方式就是对篡改后的图像进行重新获取 。因其操作的简易性被很多篡改者使用。重获取图像取证通过辨别图像是否经过重获取操作对图像操作历史的鉴别具有重要意义。另一方面,随着人脸识别身份系统的快速发展和广泛使用,一些不法分子试图通过一些手段欺骗身份识别系统,活体检测技术的使用为身份识别系统提供了一层保障,然后face2face系统的推出又为活体检测提出了挑战。 重获取图像取证作为一种新的技术手段可以有效地增强身份识别系统的鲁棒性 。
基于深度学习的方法,我们提出了一种拉普拉斯卷积神经网络算法检测重获取图像。网络结构如图8所示,对于输入图像我们首先利用信号增强层放大重获取噪声信号,然后利用5个卷积层进行特征提取,最后使用全连接层作为特征分类层。我们提出的算法在不同尺寸的图像库上实现了95%以上的检测性能。
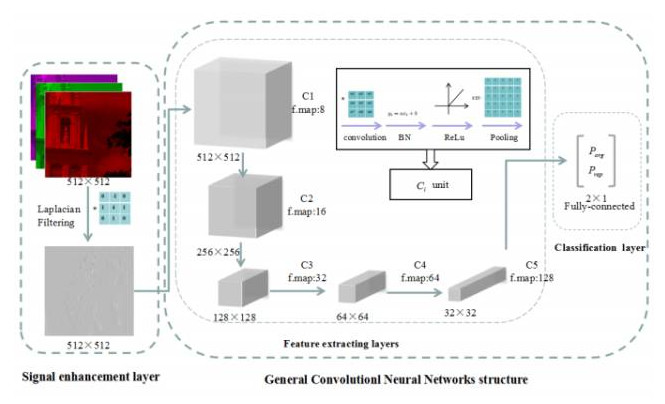
图8. 拉普拉斯卷积神经网络结构图
4.反反取证
Jingjing Yu, Xiangui Kang等将卷积神经网络应用在多类反反取证问题上。随着取证技术的发展,对抗取证的研究也随之兴起,称为 反取证研究 。 反取证是针对于特定的取证技术提出使其失效的算法 。该工作是针对于多种反取证算法进行取证,故而称为反反取证。文章提出的网络结构如下所示,四层卷积结构以及两层全连接结构。文章关注了四类反取证问题:JPEG压缩、中值滤波、重采样、对比度增强,根据文章报告的实验结果, 平均检测准确率达到了96.9% 。

图9. 反反取证算法网络结构图
5.隐写分析
把隐写分析列在这里,是因为隐写分析与取证领域存在极深的渊源。两者虽需要解决的具体问题不同,但是方法论本质上具有一致性,都是探寻微弱“噪声”信号的存在。隐写分析领域和图像取证领域的发展是相辅相成的,两者针对各自领域提出的有效算法通常在彼领域也能得到很好的应用。比如隐写分析领域常用的Rich Models、SPM算法都被应用于取证领域并取得了state-of-the-art的检测性能。
隐写分析是针对隐写问题发展而来的一种技术手段,目的是检测目标中是否包含隐藏信息。 待检测目标中嵌入隐藏信息的比特率越低,意味着隐藏信息量越少,检测难度越大 。传统的隐写分析都是基于特征提取加特征分类的两段论方案,为了更全面的刻画待测目标中的“微弱”信号,维度不断增加的高维特征被提出,例如Rich Models特征。特征分类方面为了加速高维隐写特征的分类,Fridrich课题组提出了针对隐写分析的特定分类器,集成分类器。
深度学习的发展为隐写分析提供了一种新的思路。Qian Y, Dong J等首次将深度学习算法应用于隐写分析领域,并基于隐写分析的领域知识提出高斯激活函数,取得了和传统方案性能相当的检测效果;Guanshuo Xu, Yun-Qing Shi等设计了一种新的网络结构,在网络结构中添加了绝对值层、BN层和全局pooling层,也取得了较好的检测效果。基于以上工作,两者又相继推出了后续工作。Qian Y, Dong J等融合迁移学习的方法进一步提高了算法性能;Guanshuo Xu, Yun-Qing Shi等提出了基于集成学习和集成分类的方案。
图像取证深度学习之风何去何从
如今深度学习的如火如荼让各行各业的同胞摩拳擦掌。就取证领域而言,深度学习的探索之旅还处于小荷才露尖尖角的状态。如施云庆教授在IWDW2016中的谈话所言:“深度学习在取证领域中的进步相较于计算机视觉领域是很小的,如何进一步提升深度学习在取证中的检测性能仍然值得关注”。另外,取证领域的数据集规模相对于计算机视觉领域较小,对于数据驱动型的深度学习算法,更大规模的公开的全面的精确标注的数据集对于图像取证问题无疑是迫切需要的。
这段时间本文作者经过一些探索也取得了一些心得,在此和大家一起探讨。首先就网络的深度而言,浅层的网络结构已然可以得到较好的实验结果。当然网络的加深会对实验结果略有提升,但是并不能和增加层数带来的计算复杂度的提升成比例。其次,预处理操作并不是对于所有取证问题都适用,预处理操作在放大噪声信号的同时也相应的丢失了部分原始信息,对于深度学习数据驱动型算法而言,这些丢失的原始信息对于算法性能的影响比重如何暂时还无定论,所以预处理操作添加与否还需具体情况具体分析。
目前基于深度学习的图像取证研究还有许多问题需要去解决,更多的路需要去探索,本文作者欢迎读者的任何意见或者建议,并期待和大家一起探讨。
雷锋网注:本文由深度学习大讲堂授权雷锋网发布,如需转载请联系原作者并注明作者出处,不得删减内容。
雷锋网原创文章,未经授权禁止转载。详情见 转载须知 。

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

