Git 项目推荐 | Golang 实现数据采集工具 collmz
collmz
介绍
COLL-MZ项目主要用于采集煎蛋、飞G、妹子图、Xiuren网站,以及本地类似图片、视频等文件,并展示到浏览器中。
特别申明
该项目主要是个人学习golang而开发的第一个试水程序,请勿将该项目用于非法用途。
特点
- 专为闷骚程序员提供;
- 采集各大妹子图片数据;
- 手动采集、定时采集(2小时进行一次);
- 在浏览器快速浏览相关采集数据;
- 可整理本地文件、视频、漫画、文本等数据;
- sqlite3开放式数据库,可自行构建访问,方便二次开发;
- 可根据具体需求,构建其他网站的采集程序;
- 纯Golang实现。
界面预览
浏览界面
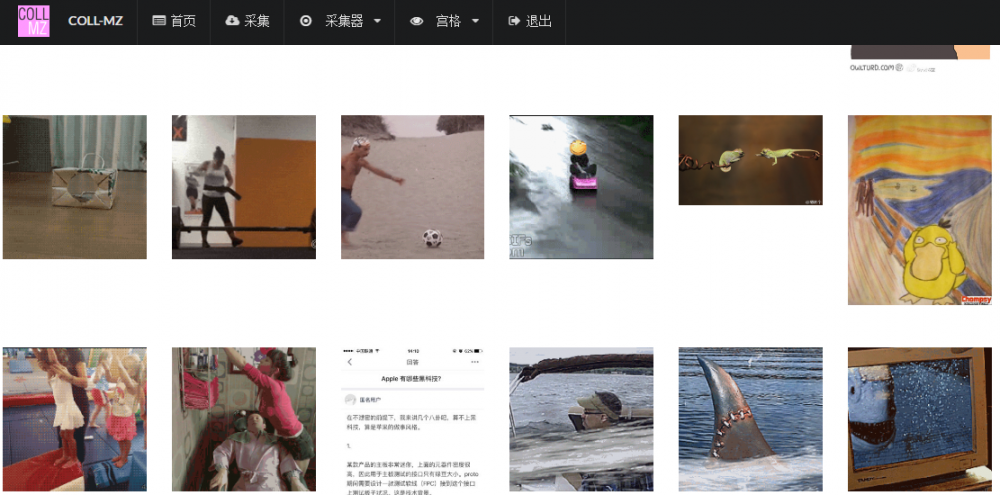
采集界面
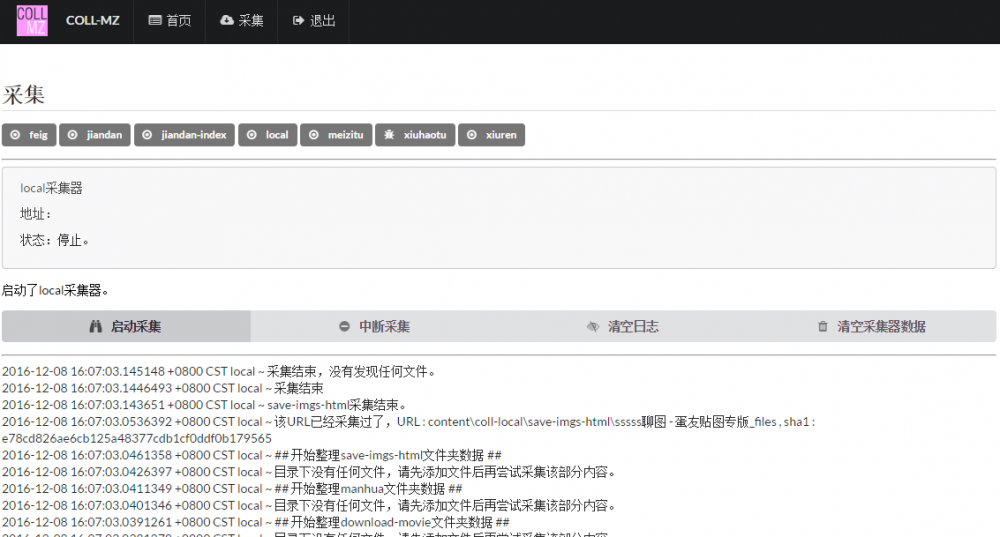
使用方法
1、下载项目到本地任意文件;
2、运行collmz-server-..exe文件;
3、通过浏览器访问 http://localhost:8888可以看到项目,可在./config/config.json文件内自行修改端口。
4、初始用户名: admin@admin.com ,密码:adminadmin
代码编译环境搭建步骤
1、安装golang语言运行环境,配置好环境变量;
2、安装gcc编译环境,并配置好环境变量,推荐使用mingw,下载地址: https://sourceforge.net/projects/mingw-w64/
3、安装golang第三方库:
* goquery github.com/PuerkitoBio/goquery * sqlite3 github.com/mattn/go-sqlite3 * session github.com/gorilla/sessions
4、下载该项目代码,到golang工作目录中任意目录,建议使用git克隆。
5、因为是在win10 x64下开发、编译的,所以只能保证该环境下运行良好,其他环境请自行排错。
项目地址
GIthub: https://github.com/fotomxq/coll-mz
OSchina: https://git.oschina.net/fotomxq/collmz
项目协议
Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
FAQ
1、可以不部署代码直接使用么?
可以,下载整个项目,之后运行exe文件即可。项目内的controller文件夹可自行删除。
2、编译失败是什么情况?
常见的错误主要出在sqlite3上,因为该第三方库是用C实现的,需要用到GCC编译器,也就是mingw,所以如果安装错版本、没有配置对环境变量,都会报错。64位系统一定要使用64位的GCC编译。
3、想在此结构上构建其他采集器怎么做?
在controller下有coll-children-...go的文件,这些文件都是对应的采集器代码,可参考这些代码写自己需要的采集项目。
可使用构建好的相关框架,首先在coll.go内注册好采集器,这样可直接通过浏览器访问到采集器;然后自行建立go文件写入代码,这样就可以了。
注意,如果是正在开发的项目,CollChildren.dev尽量等于true,这样在浏览器端内容易区分。
CollOperate.Auto...(),这几个方法是集成了大部分情况下采集工作,可以极大方便采集工作。
关于项目逻辑、思维导图
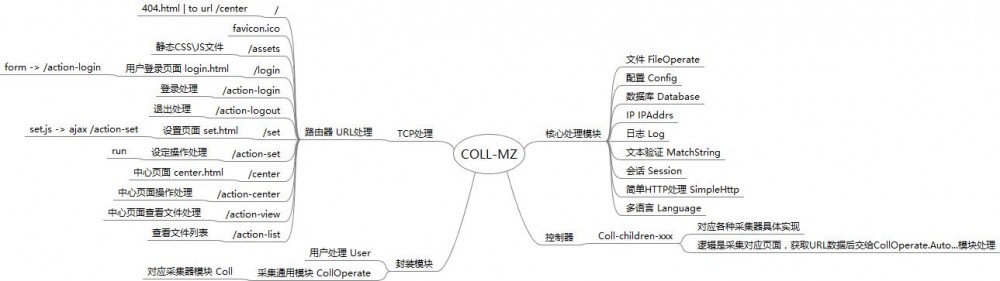
4、采集速度如何?
由于sqlite3无法多开线程,所以一个采集器只能对应一个并发操作,如果发现重复运行、在采集过程中浏览数据会自动阻止。
每个采集器有各自的线程。
5、为什么某些采集器不能用?
个别采集器因为国内局域网限制,需要自行解决问题。
其次极个别采集的网站存在JS动态加载功能,以及各种阻拦采集工作的功能,所以未来看个人开发能力提升后再解决。这类采集器都标记了dev状态,你可以在采集界面中看到。
6、如何修改初始用户名和密码?
在写这段文本的时候,我才想起来没有做这个页面,所以暂时请用sqlite工具打开./content/database/coll-mz.sqlite数据库,修改其中的user表数据即可。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

