新一代数据查询语言GraphQL来啦!
1. GraphQL来啦!
当Facebook构建移动应用的时候,它需要的是一个强大的数据获取API:
- 足够强大,满足Facebook自身复杂业务的需求;
- 足够简单,对开发者和使用者来说很容易上手与使用;
 GraphQL就是为了满足这一个需求而产生的,Facebook从2012年开始完善,与2015年展开GraphQL的开源的进程,并形成一个 围绕GraphQL的社区 。
GraphQL就是为了满足这一个需求而产生的,Facebook从2012年开始完善,与2015年展开GraphQL的开源的进程,并形成一个 围绕GraphQL的社区 。
GraphQL每天都为Fackbook接收、处理着上百亿的请求,为Fackbook提供了强大的基础数据平台的支持,滋养大量业务与产品。
2. 为什么是GraphQL?
回到2012年,Fackbook开始重构他们的本地移动应用。当时他们的iOS和android移动应用实际上是就是他们Web应用的内容再加上一个本地浏览器的壳。这看上去给他们带来了“ 一次开发,多端应用 ”的好处,但是随着Fackbook移动应用越来越复杂,这样的做法直接带来了极差的性能和时常发生的程序崩溃,所以他们开始开发真正的本地应用。
而当时 Facebook 现有的服务器主要功能还是只提供 HTML ,数据接口并不能直接复用,服务模式就是请求一个 URL ,返回一堆 HTML。而本地移动应用,为了给应用提供需要的数据,填充数据模型,显示视图,要解决的问题是怎么去请求,准备,传递这些数据。
Facebook考量了两种实现方案,包括 RESTful服务资源 和 FQL表 。
- RESTful:对于Facebook这种复杂的应用,可能需要定义很多端点,这些数据接口可能只是返回字段有所不同,造成重复工作,同时难以表达复杂的逻辑;
- FQL:FQL是Facebook类似于SQL的API,它功能强大、格式明确,但是查询的语言非常难以理解,例如一些数据表JOIN等操作。
Facebook工程师们希望能够在移动应用和服务端的查询达到一致,最后使用的模型可以类似于NSObjects或者JSON那样的结构。
几个工程师开始了现在的 GraphQL, 一种用对象,属性来表示数据关系,有点像图形的方式来表达想要的数据 。所以最终GraphQL给了产品设计人员和开发人员重新思考移动应用数据获取的机会,它将开发的重点转移到了客户端应用中,这里是设计师和开发人员最关注的地方。
3. 什么是GraphQL?
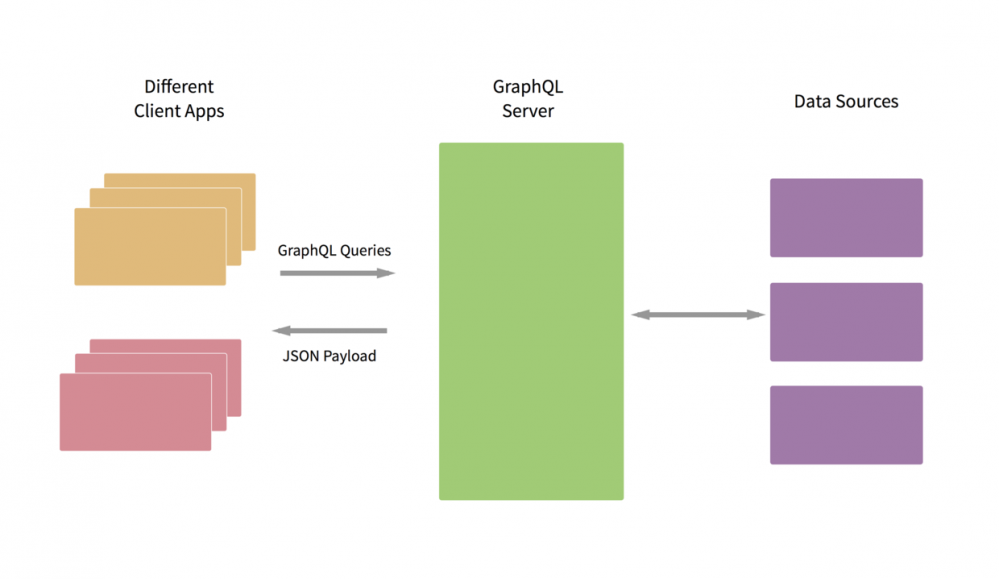
GraphQL是一种API查询语言,是一个对自定义类型系统执行查询的服务端运行环境
一个GraphQL查询是一个被发往服务端的字符串,该查询在服务端被解释和执行后返回JSON数据给客户端。
3.1 定义数据模型
首先让人一目了然的是GraphQL查询可以直接映射到返回的数据,它们的结构非常相似。这带来个好处就是你很简单就 从查询预测到即将返回的数据 ,相反的 知道需要的数据也可以很简单写出相应的查询语句 。更重要的是,这使得GraphQL更加容易学习和应用。
// 下面是一个简单的GraphQL查询,获取id为1001的用户的名字和头像
{
user (id: 1001){
name,
photo
}
}
// 对应的结果
{
"user": {
"name": "shiji",
"photo": "https://ss1.baidu.com/6ONXsjip0QIZ8tyhnq/it/u=2639867671,3554518423&fm=58"
}
}
3.2 分层的
GraphQL另外一个重要的方面就是它自然而成的分层结构。GraphQL很自然的以对象和属性来表示数据之间的关系,这也是GraphQL的命名由来。 你可以简单的把GraphQL查询看成三部分。
- 由{}包裹的
对象 - 对象由
属性列表组成 - ()包裹的
查询条件
// 获取用户信息的同时获取该位用户的朋友信息列表,包括姓名、性别和地址信息
{
user (id: 1001){ // 第一层
name,
photo,
age,
friends { // 第二层
name,
sex,
addr { // 第三层
country,
city
}
}
}
}
3.3 强类型
每一级GraphQL查询都关联着一个特殊的类型,而每一种类型都描述了一组可用的字段集合。 GraphQL服务通过定义类型和属性来创建 ,然后为在这些类型上的每个属性创建函数。跟SQL类似,这使得GraphQL在执行查询之前可以提供描述性的错误信息。
// 对应上一个GraphQL查询,GraphQL 服务需要建立以下自定义类型
type Query {
user: User
}
type User {
name: String,
photo: String,
age: Integer,
addr: Address,
friends: [User]
}
type Address {
country: String,
city: String
}
GraphQL 的类型系统分为 标量类型 (Scalar Types,标量类型)和其他 高级数据类型 ,标量类型即可以表示最细粒度数据结构的数据类型,可以和 JavaScript的原始类型对应。
GraphQL 规范目前规定支持的标量类型有:
-
Int: 整数,对应JavaScript的Number -
Float:浮点数,对应JavaScript的Number -
String:字符串,对应Javascript的String -
Boolean: 布尔值,对应JavaScript的Boolean -
ID:序列化后唯一的字符串,对应JavaScript的Symbol
高级数据类型包括: Object 、 Interface 、 Union 、 Enum 、 Input Object 、 List 、 Non-Null 这里不做详述,请参考官方指引 Schemas and Types 。
3.4 协议而非存储
GraphQL并不直接提供后端存储的能力,它不绑定任何的数据库或者存储引擎,它可以利用你已有的代码和技术来进行数据源管理。当然这对改造现有的业务会带来相应的成本。
也就是说GraphQL提供给你了组织与管理数据源的能力,但是数据具体是存在文件系统还是数据库它并不关注。
3.5 自检性
一个GraphQL服务可以直接查询出它所支持的类型,也就是说你不需要花时间写API文档,也不需要花时间理解API。GraphQL直接帮助开发者快速学习和探索API。
// GraphQL查询
{
__schema {
queryType {
name,
fields {
name
}
}
}
}
// 查询结果
{
"data": {
"__schema": {
"queryType": {
"name": "User",
"fields": [{
"name": "name"
},{
"name": "photo"
},{
"name": "age"
},{
"name": "addr"
},{
"name": "friends"
}]
}
}
}
}
每个 GraphQL 根域都会自动加上一个 __schema 域 ,这个域有一个子域叫 queryType 。我们可以通过查询这些域来了解 GraphQL 服务器支持那些查询
3.6 无需版本的
返回数据的模型完全由客户端的查询决定,所以服务端变得更简单、更容易一般化。
当你添加新的产品功能时,额外的字段可以被添加到服务中,同时并不会影响到现有的业务;当你淘汰老功能的时候,遗弃对应的服务字段依旧可以继续工作。
这种 渐进式、向后兼容 的过程去除了递增版本号的需要。在Fackbook中使用相同版本的GraphQL API 支持了跨域三年的Fackbook应用。
4. GraphQL vs RESTful
之前谈过Fackbook不使用RESTful自研发GraphQL的原因,这里再详细讲一下。
RESTful API的问题在于:
1、 缺乏可拓展性 。 一个刚开始简单的用户接口可能只返回少部分信息,例如用户名、头像等。随着API的不断发展,可能需要返回更多的信息,例如年龄、昵称、签名等。很多时候 客户端只是需要其中的部分信息,但是接口依旧传输了所有的信息,这个情况增加了网络传输量 ,特别对于移动应用来说特别不友好,同时需要客户端自行提取需要的数据。而 建立两个功能大致相同只是返回字段有所区别的API则增加了后端实现的复杂度 ,或者是需要增加业务逻辑判断,或者是增加了维护的难度。
2、 复杂的数据需求需要做多次API调用 。 例如客户端要显示文章的内容,可能要调用文章接口、评论接口、用户信息接口。为构成对一个资源的完整视图,需要做多次单独调用,这样的数据获取方式非常不灵活。
而GraphQL给客户端带来了自主选择的权利。
- RESTful: 服务端决定有哪些数据获取方式,客户端只能挑选使用 ,如果数据过于冗余也只能默默接收再对数据进行处理;而数据不能满足需求则需要请求更多的接口。
- GraphQL: 给客户端自主选择数据内容的能力,客户端完全自主决定获取信息的内容,服务端负责精确的返回目标数据 。
举个例子:我们要获取指定id的文章相关信息,包括标题、作者、发布时间以及前两条评论;同时加载当前用户信息。
RESTful:
// 两趟查询,难以拓展 GET /user/111 GET /article/1001?comment=2
GraphQL:
// 一趟查询,易于扩展
{
article (id: 1001){
title,
author,
time,
comments (first: 2)
nickname,
time,
content
}
},
user (id: 111){
nickname,
photo,
sign
}
}
获取的数据结果如下所示,就是这么简单粗暴的完成了API定制。
我们不仅按照我们的需求完成数据过滤,同时仅仅使用一次请求就获取了所有你想要的数据。
{
"article": {
"title": "新一代API查询语言GraphQL",
"author": "shiji",
"time": 1481127981218,
"comments": [{
"nickname": "狗剩子",
"time": 1481127981218,
"content": "楼主写的真好"
}, {
"nickname": "不明真相的吃瓜群众",
"time": 1481127981218,
"content": "这瓜真好吃"
}]
},
"user": {
"nickname": "shiji",
"photo": "https://ss1.baidu.com/6ONXsjip0QIZ8tyhnq/it/u=2639867671,3554518423&fm=58",
"sign": "我的地盘我做主——动感地带"
}
}
当然GraphQL给服务器端代码带来了不公平的额外复杂度和管理,GraphQL非常适合于客户对底层数据具有复杂规模的需求,客户端完全可以自主定制个性化API。
5. GraphQL存在的问题
1、 改造成本 ,要使用GraphQL对数据源进行管理,相当于要对整个服务端进行一次换血。你需要考虑的不仅仅是需要针对现有数据源建立一套GraphQL的类型系统,同时需要改造服务端暴露数据的方式,这对业务久远的产品无疑是一场灾难,让人望而却步。
2、 实践方案 ,GraphQL在前端如何直接与视图层、状态管理方案结合,目前也只有React/Relay这个官方方案。也就是说,如果你不是使用Node+React这个技术栈,引入GraphQL看上去带来了额外的成本和风险。
3、 查询性能 ,GraphQL查询的每个字段如果都有自己的resolve方法,可能导致一次查询操作对数据库跑了大量了query,数据库里一趟select+join就能完成的事情在这里看来会产生大量的数据库查询操作,虽然网络层面的请求数被优化了,但是数据库查询可能会成为性能瓶颈。
6. GraphQL安全性?
或许有人有疑问,感觉 GraphQL 把我所拥有的资源全部都暴露了,别人不只一览全局,能够了解你所有的数据结构,而且还能一次把所有数据都拉取下来,这也太可怕了!
事实上,GraphQL 提供的资源不一定要和你数据库一样,因为它只是扮演 中间层 的角色,虽然也可能很像。所以,你完全可以控制你期望暴露给用户的资源。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

