深入探索并发编程系列(十)-Weakly-ordered CPU的由来
在这一系列博客中,我已经详细讨论了 lock-free编程 相关的一系列主题,比如Acquire与Release语义以及Weakly-ordered CPUs. 我已经努力尝试把这些主题讲的更加地通俗易懂,但大家都知道,Talk is cheap.没有言语比具体的例子更能把问题说清楚。
如果要概括weakly-ordered CPU,可以这么说:一个CPU core按照一定的顺序修改变量,然而其他的CPU core却可以看到对该变量不同的修改顺序 注1 . 这就是我要在这篇文章中使用纯C++11来讲述的内容。
对于一般程序来说,x86/64处理器家族从Intel到AMD都不具备这种特性。因此我们别想着在现有的桌面系统或者笔记本上来阐述这种问题了。我们需要的只是一个weakly-ordered的多核设备。幸运的是,在我口袋里恰好就有这么一台设备。

Iphone4s就能满足要求。它运行在一个多核ARM处理器上,而这种ARM架构就是weakly-ordered.
实验
我们的实验由一个整型变量 sharedValue 以及保护它的锁(mutex)组成。我们来生成两个线程,并且每个线程都会对 sharedValue 做递增操作1千万次。
我们不要让线程一直等待锁(mutex)而阻塞,而是让每个线程都会忙碌地重复做一些事情(比如只是等待CPU时钟),并试着在随机的时间里加锁。如果加锁成功,那线程就会将 shareValue 递增,否则,就会返回到原处继续做一些忙碌地工作。下面是其伪代码:
count = 0
while count < 10000000:
doRandomAmountOfBusyWork()
if tryLockMutex():
// The lock succeeded
sharedValue++
unlockMutex()
count++
endif
endwhile
每个线程都运行在不同的CPU核中,timeline应该是像下图这样的。每个红色区域代表一个成功的上锁和递增操作,灰色代表加锁失败,因为这时另一个线程已经拥有这把锁了。
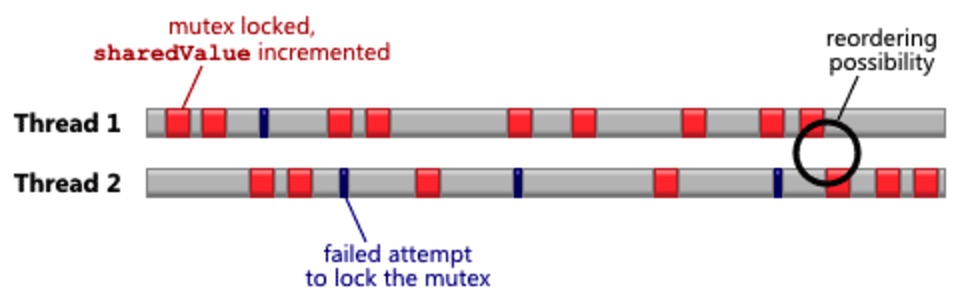
需要强调的是,锁只是一个概念,有许多实现锁的方法。我们采用std::mutex中提供的实现方法,当然了,保证其中一切都会运行正确。倘若真是那样,我就没什么可以跟你们讲的了。不如这样,我们来实现一个常规的锁-我们来看看弱硬件执行顺序的结果。直观上来看,当在线程间有个“close shave”时,内存乱序发生的可能性是最高的。举个例子,在上图中,当一个线程正好就在另一个线程释放锁的那一时刻获取锁,这种现象就叫做”close shave”。
Xcode的最新版本对C++11线程和原子类型支持非常好,那我们就用它吧。所有的C++标识符都定义在 std 命名空间中,我们假设 using namespace std 提前定义在了代码中某处。
一把诡异的简单锁
我们的锁由一个整型 flag 组成,1表示锁被持有,0表示不被持有。为了保证锁的独占权,一个线程只能在 flag 值为0的时候才能将其设置成1,而且这种操作必须保证原子性。为了做到这些,我们将 flag 定义为C++11的原子类型, atomic<int> ,并采用 read-modify-write 操作:
int expected = 0;
if (flag.compare_exchange_strong(expected, 1, memory_order_acquire))
{
// The lock succeeded
}
上面代码中用的 memory_order_acquire 参数被认为是执行顺序约束的(ordering constraint).我们在操作中采用acquire语义,用来保证我们能从持有锁的前一个线程中获取最新的共享值 注2 。
为了释放锁,我们执行下面的操作:
flag.store(0, memory_order_release);
上面操作使用 memory_order_acquire 执行顺序约束将 flag 设置回0了,其采用了release语义。Acquire与Release语义必须成对使用,用来确保共享值能从一个线程中传播到另一个线程中 注3 。
如果不实用Acquire和Release语义
现在,我们不限定任何的正确执行顺序约束,使用C++11重写上述实验,只要在两处都放置’memory_order_relaxed`。这意味着C++ 11编译器不会强制任何特殊的内存执行顺序,任何类型的乱序都是允许的。
void IncrementSharedValue10000000Times(RandomDelay& randomDelay)
{
int count = 0;
while (count < 10000000)
{
randomDelay.doBusyWork();
int expected = 0;
if (flag.compare_exchange_strong(expected, 1, memory_order_relaxed))
{
// Lock was successful
sharedValue++;
flag.store(0, memory_order_relaxed);
count++;
}
}
}
这时,看看编译器产生的ARM汇编代码能告诉我们很多信息,在Release中,使用Xcode中的反汇编视图:
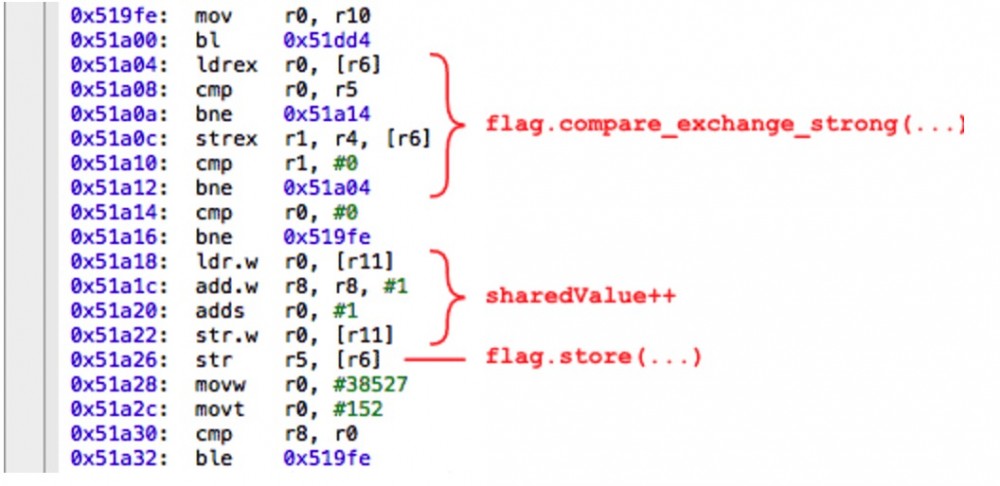
如果你对汇编不是很熟悉,也不必担心。所有需要知道的就是编译器是否在共享变量中对任何操作重新排序了。这里包括对 flag 的两种操作以及对 sharedValue 的递增操作。在上图中,我标明了相应区域对应的汇编代码。正如你所知,我们是幸运的:尽管 memory_order_acquire 参数意味着编译器可以对那些操作重新排序,但编译器并没有这么做.
我已经给出了一个样例程序来无限循环这个实验,并在每一次运行结束后将 sharedValue 的最终值打印出来。如果你想看源码并自己运行,可以在 github 上下载。
下面是iphone正在努力的运行这个实验

这是Xcode输出框中的输出:
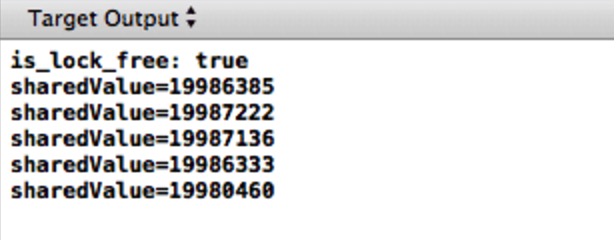
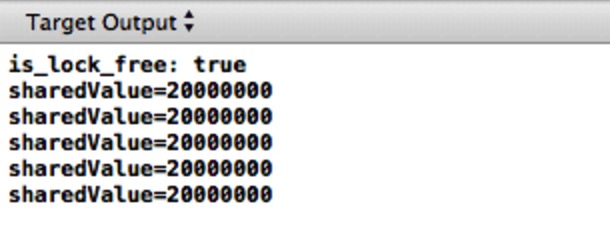
动手检验一下!尽管两个线程都分别执行了递增操作1千万次, sharedValue 的最终值一直小于2千万。并且,汇编指令的执行顺序和C++中定义在共享变量中的执行顺序操作是一致的。
你可能会觉得,这些结果可能是因为CPU上的内存乱序导致的。为了指出一种可能的乱序-实际上有很多种可能- str.w r0, [r11] (sharedValue写操作)与内存的交互可能会和 str r5, [r6] (将flag写入0)发生乱序。换句话说,在程序结束之前,锁能被有效地释放。正如我们所见,结果是另一个线程可以自由的擦除由这个线程对值的修改,导致在实验结束时 sharedValued 的不一致。
正确使用Acquire与Release语义
要修正上述的例子,意味着要重新放回正确的C++11内存执行顺序约束:
void IncrementSharedValue10000000Times(RandomDelay& randomDelay)
{
int count = 0;
while (count < 10000000)
{
randomDelay.doBusyWork();
int expected = 0;
if (flag.compare_exchange_strong(expected, 1, memory_order_acquire))
{
// Lock was successful
sharedValue++;
flag.store(0, memory_order_release);
count++;
}
}
}
编译器插入一系列 dmb ish 指令,这些指令在ARMv7指令集中充当内存屏障。我不是个ARM专家–欢迎评论–但可以保险的假设这个指令很像PowerPC上的 lwsync 指令,为 compare_exchange_strong 上的acquire语义和 store 上的release语义提供了所有内存屏障类型 注4 。
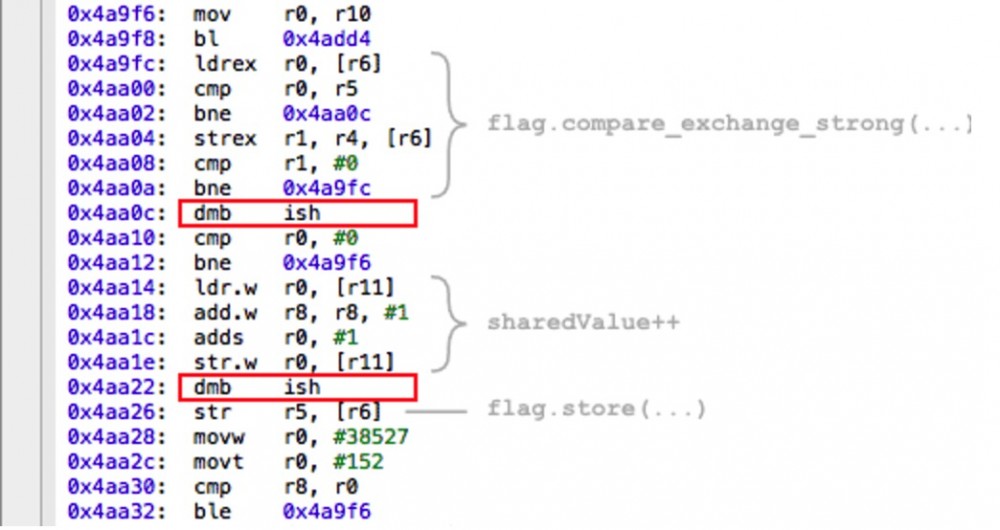
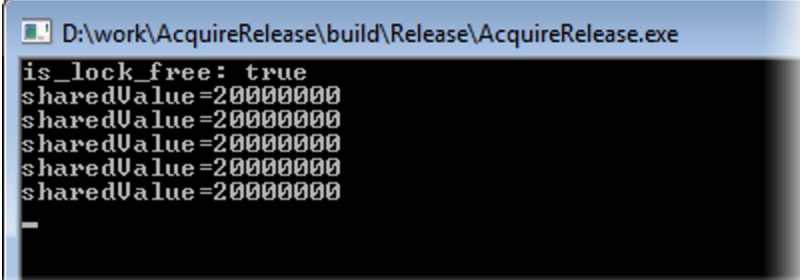
这次,我们可爱的自制锁的确保护了 sharedValue ,确保每次加锁时所有的修改都从一个线程中安全的传播到了另一个线程中 注5 。
如果你仍然无法理解这个实验发生了什么。我建议你看看这篇文章。就类比而言,你可以想象一下,两个工作站其中每个都有 sharedValue 和 flag 的本地副本,需要一些其它的工作来确保它们是同步的。个人而言,用这种方法将其可视化是很有帮助的。
我想重述一遍,我们在这里看到的内存乱序只能在多核或多处理器设备中才能发生 注6 。如果你把这个编译好的程序运行在Iphone3GS或更早一代的ipad中,它们都使用同样的ARMv7架构但只有一个CPU核,你也不会看到 sharedValue 最后结果的任何不匹配性。
有趣的笔记
你可以把这个 示例程序 运行在任何x86/x64架构上的Window,MacOS或Linux机器上。就算是在一个多核系统中,除非是你的编译器在一些特殊指令上执行了乱序,否则你是不会看到任何运行时的内存乱序的。当我用Visual Studio2012测试时,并没有发生内存乱序。那是因为x86/x64处理器通常都被认为是strongly-ordered:当一个CPU核执行一系列写操作时,每个其它CPU核都会看到它们在被写入时顺序的值变化 注7 。
上图为了说明如果不了解C++11原子类型,就很容易错误的使用,。很简单,因为它只有在一个特殊的处理器和工具链中才能正确运行
碰巧的是,Visual Studio2012的发行版对这个示例程序会产生非常糟糕的x86机器代码。在多核系统上使用lock-free编程,提高性能是最首要原因。现在有足够的理由让我无法忍受在Window平台上用C++11原子类型了。正如 评论 中提到的,VS2012专业版的最新版本产生的机器代码会好很多了。
这篇文章是前期文章讨论x86/64上的StoreLoad乱序的续集。从我的经验来看,#StoreLoad在实际运用中并不如这里提到的执行顺序约束用的频繁
最后,我不是第一个在实际运用当中阐述弱硬件执行顺序的人,但我可能是第一个使用C++11来阐述的人。之前 Pierre Lebeaupin 和 ridiculousfish 的一些文章采用了不同的实验来解释相同的现象。
译者注
注1:也就是说,假如CPU core1执行如下语句:
a = 1; b = 2;
CPU core2可能先看到b == 2 ,然后才是 a == 1
注2: acquire对应invalid queue。 release对应store buffer。
注3: 这里的配对,并不是严格的一一对应。也就是说,CPU core1修改共享变量时使用release语义,CPU core2、 core3、core4都用acquire语义去读。
那么core1和core2、core3、core4都配对。
注4: 这里值得一提的时,gcc下的 __sync_compare_and_swap 和 __sync_fetch_and_add 这些原子操作在X86下会自带一个memory barrier。所以这些原子操作之后没必要再加memory barrier了。
注5: 其实这也是锁的必备的一个语义。一般说来,锁要提供三种语义:
b++; lock.lock(); a++; d++; lock.unlock(); c++
语义1:当线程1更新完a(也包括d)的值之后释放锁,线程2进入临界区必须读到a(也包括d)的新值,也就是线程1更新完之后的值。可以认为是acquire release或者happen before语义。
语义2:同一时刻,a++这条语句只能有一个线程在执行。可以认为是临界语义或者互斥语义。
语义3:必须保证a++不会被乱序到b++处执行,也不能乱序到c++处执行。这个自然也是临界语义或者互斥语义的一部分,因为如果乱序,那么无临界区可言了。但是读者诸君要注意到,以下这样的乱序是完全可以的、合法的:
b++; lock.lock(); d++; a++; lock.unlock(); c++;
或者:
lock.lock(); b++; a++; d++; c++; lock.unlock();
注6:也就是说,单核多线程、多核单线程程序不用担心memory reordering问题,只有多核多线程才需要小心谨慎。为什么呢?
更进一步,读者可能还会有两个疑问:
1,为什么CPU要乱序执行,难道是考虑性能吗?那为什么乱序就能提升性能?
2,为什么在Intel X86/64架构下,就只有写读(Store Load)发生乱序呢?读读呢?读写呢?
要明白这两个问题,我们首先得知道cache coherency,也就是所谓的cache一致性。
在现代计算机里,一般包含至少三种角色:cpu、cache、内存。一般说来,内存只有一个;CPU Core有多个;cache有多级,cache的基本块单位是cacheline,大小一般是64B-256B。
每个cpu core有自己的私有的cache(有一级cache是共享的),而cache只是内存的副本。那么这就带来一个问题:如何保证每个cpu core中的cache是一致的?
在广泛使用的cache一致性协议即MESI协议中,cacheline有四种状态:Modified、Exclusive、Shared、Invalid,分别表示修改、独占、共享、无效。
当某个cpu core写一个内存变量时,往往是(先)只修改cache,那么这就会导致不一致。为了保证一致,需要先把其他core的对应的cacheline都invalid掉,给其他core们发送invalid消息,然后等待它们的response。
这个过程是耗时的,需要执行写变量的core等待,阻塞了它后面的操作。为了解决这个问题,cpu core往往有自己专属的store buffer。
等待其他core给它response的时候,就可以先写store buffer,然后继续后面的读操作,对外表现就是写读乱序。
因为写操作是写到store buffer中的,而store buffer是私有的,对其他core是透明的,core1无法访问core2的store buffer。因此其他core读不到这样的修改。
这就是大概的原理。MESI协议非常复杂,背后的技术也很有意思。
注7:X86写写不乱序;也就是说对于
a = 1; b = 3;
其他cpu core将先看到a == 1再看到 b == 3。(不考虑编译器优化)
Acknowledgements
本文由微博用户Diting0x 与睡眼惺忪的小叶先森 共同完成,在原文的基础上添加了许多精华注释,帮助大家理解。
感谢好友小伙伴-小伙伴儿阅读了初稿,并给出宝贵的意见。
原文: http://preshing.com/20121019/this-is-why-they-call-it-a-weakly-ordered-cpu/
本文遵守Attribution-NonCommercial-NoDerivatives 4.0 International License (CC BY-NC-ND 4.0)
仅为学习使用,未经博主同意,请勿转载
本系列文章已经获得了原作者preshing的授权。版权归原作者和本网站共同所有
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

