实践|如何从0开始 搭建应用监控架构?
本文由 易宝支付技术运营总监 黄小龙 供稿
随着业务系统的不断迭代建设,基于现有的日志监控系统或报警平台,是否能够精准的定位问题根源及自动化实时捕捉微小的异常或错误在系统运行的过程中会有什么样的影响?面向业务提供全栈性能监控和分析的诉求凸显越来越重要,本文将结合应用监控架构设计的最佳实践原则(《架构即未来》第三十一章节“应用监控”),结合实际的监控架构设计的思路,引申出应用性能监控建设架构并结合实际案例加以介绍。
“系统事故对企业的损失不言而喻,与其投入重点精力做时候的补救,倒不如提前在之前做好架构设计和业务应用监控。” ——摘自《架构即未来》之应用架构核心思想
监控架构的核心思想
当企业处在快速成长的时期,业务系统也在不断的迭代更新中,如若无法快速识别系统可扩展的瓶颈,必将遭受长期的系统服务中断的痛苦,因为任何微小的异常隐患或程序报错的发生,轻则影响用户体验,造成用户埋怨不断,重则可能会引发系统的故障,如业务系统宕机这般灾难性的故障。
在参与过往的业务系统应急处理过程中,经事后RCA(Root Cause Analyze )的源头分析发现均有共同点,就是引发错误的根源被隐藏极深,在事故处理过程中很难短时间内发现源头的端倪,即便通过了严格的业务变更评审及DBA细致的SQL走查,终究会有一些“漏网之鱼”,而这些问题通常在标准的业务覆盖回归测试中很难被发现,也只有在生产运行后的一段时间,被某种“神奇的力量”触发。要想做到事前预防或在最佳时期处理清楚问题隐患,确保业务大规模上量后能够稳健的运行,则需要思考的问题是 “基于现有的日志监控系统或报警平台,是否能够精准的定位问题根源及自动化实时捕捉微小的异常或错误在系统运行的过程中会有什么样的影响?”
如果想要能精准定位并具备相应的能力来捕获这些“漏网之鱼”,便离不开应用监控架构的思路来指导。因为要完成这件事情,有过行业经验的朋友或专家会告诉你,这不仅仅需要有大量的信息来搜集和检索,如统一的大数据日志监控系统(ELK),还得要有非常得力的应用性能管理(Application Performance Management)工具如云智慧透视宝进行7*24小时实时的监测分析,一旦出现问题可以做到秒级甚至毫秒级别的快速捕捉问题,通过配套的自动检查分析机制,来筛选并验证一些细小的错误,在通过共性部分来反查应用代码,刨根问底,发现存在的隐患是不是引发灾难源头。比如发生了故障,首先会考虑的是“出问题了吗?”之后就是“出什么问题了?”然后就是“问题出在哪里?”最后便是“是什么问题?”随着问题的递进和深入,所需要回答和准备的数据也越来越多,这也是数据规模与问题针对性之间的重要联系(见下图),作为架构设计者和事故处理负责人必然会问到的这四个核心问题。 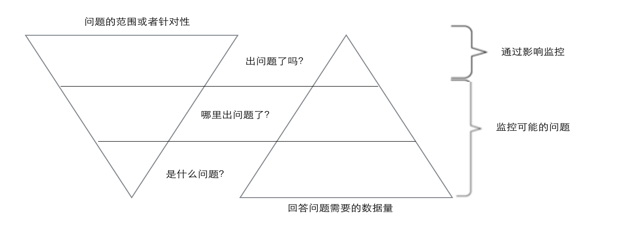 图一:数据规模与问题针对性之间的关系,摘自 “《架构即未来》第三十一章 应用监控架构P31.3”
图一:数据规模与问题针对性之间的关系,摘自 “《架构即未来》第三十一章 应用监控架构P31.3”
应用监控架构的核心思想就是帮助运维改变这样的窘迫局面:“每次发生系统级别故障,花费很长的时间去定位引发故障的根源如变更的步骤遗落、代码编写不规范、业务SQL的超出标准等,这些根源所引发的问题都不一样,都需要经过各式各样的应急去处理,直到事后的问题整改,完成故障的闭环。看似标准符合逻辑,但这样周而复始下去,往轻的一方面解读是在业务上所反馈出来表象便是让商户或用户不断的试错,正常的业务交易中断,逐渐地丧失了对产品的信心;往重的方面去分析,业务系统的故障,会增加企业的运营成本,甚至影响核心的技术团队实力”我们不妨换个思路来,首先解决“问题发生之前有尽早发现故障前兆的报错或者异常信息?”,因此,引申出了我们在进行业务应用监控架构设计的核心思想,这也是为客户提供更好的服务水平承诺(SLA:Service Level Agreement)的标准化结构设计重点。为提升用户体验,系统的平均响应时间(ART:Average Response Time)和有效成功率(EST:Effective Success Rate)这两大指标也是面向应用监控可量化衡量的参考依据。
监控系统的设计指导与框架模型
监控设计指导
为了能够清楚意识到 任何微小的延迟都可能预示着明天的局部停机或者系统瘫痪, 遵循通用监控系统设计的指导思想,需要进行对业务系统的划分:
1) 面向IaaS平台:包括但不限于硬件底层、操作系统主机、数据库、网络等;
2) 面向PaaS平台:如SOA公共框架(SOA框架、Dubbo服务等)、公共组件(缓存Redis组件、消息队列RabbitMQ组件等),公共服务子系统或公共服务平台等;
3) 面向SAAS服务:如提供业务服务的HTTP、API、SDK、APP、SOCKET等;
遵循分层的设计原则,企业级监控系统的采集周期(频次)必须能够细化到秒级甚至毫秒级别,监控数据必须完整覆盖天、周、月、年的单位,历史监控数据必须完整存储超过3年以上的时间,这也是对重要监控系统最基本的需求。其中,所设计的监控系统要面向的目标对象(Goal Object)必须能够准确反映出可用性状况、性能瓶颈指标、对外提供服务的SLA指标(ART&EST)等,如果是面向应用型监控系统,不仅仅能够完整的显示出应用中间件或容器的JVM等各类指标,包括但不限于GRP:GlobalRequestProcessor,BusyThread,JCA:JavaConnectionAvailable,MaxReuqestTime,AverageResponeTime等),而且可以捕捉到WebServer在运行过程中,应用系统中各方法类的性能开销状态,出现故障如果可以进行做追述和定位的时候,还能细化到开销方法的全栈追踪到每个数值,那这样的业务应用监控架构的设计就非常的完整,即通常我们所描述的监控系统的颗粒细度以及能够对重要的系统、业务、安全等指标进入预测分析。
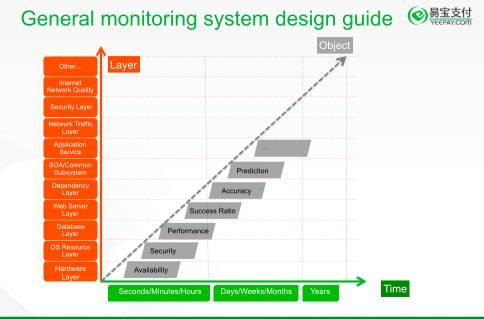 图二:通用监控系统设计指导思想
图二:通用监控系统设计指导思想
企业监控框架
对于企业内部趋向于成熟的监控框架通常会来行业通用的结构来部署,这个结构需要将 监控、分析与控制 完成三位一体的无缝融合。本人的切身感受而言, 一个好的监控架构不仅仅能够建设基于现状及未来发展提供有效的监控预警支撑,而且可以通过平台内实时或积累的系统或业务监测数据进行联动分析,找出问题的瓶颈点或未来的增长点,提供系统成长重要的数据决策支撑。
简单来说,监控系统框架分为如下三个部分:
统一监控
1) 基础层面的监控:通过选取开源或主流的监控系统,完成公共设施或系统运维方面的有效监控,如OpenNMS-Cacti聚焦网络层面; Zabbix/Hyerpic HQ聚焦IaaS公共层面;监控宝聚焦网站、API等。无论何种监控系统只是一种实现系统生命周期的有效运维工具,对工具本身的热爱及对工具所涉及的技术选型最好的依据主要是能够融会贯通,举一反三。因为没有任何一款监控工具都适用于所有公司的监控需求,基于量体裁衣以及在主流被广泛使用的系统,同时兼顾了为日后统一监控中心的数据融合所准备的,能够通过DevOps结合的监控系统才是最适合自己的。
2) 有效的应用性能监控:除了WebServer的各层基础运行指标,因代码BUG或者程序设计不当所引发的各种级别故障越来越多,对于企业来讲,业务代码的变更需经过严格的覆盖测试,甚至会在对外发布后进行全回归覆盖测试及在必要的时候进行性能压力测试,但漏网之鱼依然存在,而且企业通常很难做到7*24小时的实时业务性能检测分析,特别是在多业务复用的情况下,具体引发的问题根源无法在短时间内被快速定位和追踪到,这也是过往业务监控的一个短板,如何准确定位到业务代码级别的故障和异常,捕捉的信息能够直接为开发工程师提供第一手的信息反馈,确保业务高峰来临前能够被准确的发现修复, 我将在下文通过透视宝的实践操作来加深这方面的介绍。
3) 统一的业务日志平台:ELK(Elastic+Logfluent+Kibana)已然成为行业的标杆或首选,尽管市面上有很多主流的商业化产品,但对本人而言,更加青睐自身DevOps研发建设出一套大数据如日志监控系统,因为这也是作为一家互联网科技公司的技术标配,这样不仅能够个性化定制和配置,还能无缝对接集团或公司业务的特殊监控诉求。
4) 开放的API监控:能够完成如业务API的有效性监控,做到接口数据相关的故障分析,实现对系统的弹性预测、耗损/过期分析、颗粒细度的定位位。
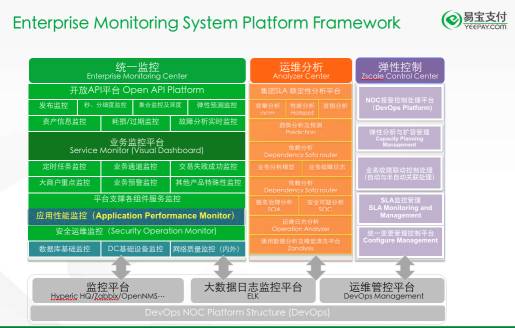
图三:企业级监控系统框架参考
APM应用性能监控系统介绍
“工欲善其事必先利其器”,做到代码级别的监控故障分析,提供7*24小时不间断的业务检测,就离不开专业有力的应用性能监控工具或平台,精准的应用性能监控分析也是业务上线后稳定健壮运行的重要保障。
应用监控
应用监控很重要,它能帮助我们回答“是什么”的问题。通常情况下,要确定“是什么问题?”我们需要特别编写一些监控代码或者需要有能够监控代码的工具,如果想要把它做好,我们可能需要把代码集成在产品或业务系统里。尽管有一些代理会告诉我们到底问题是什么,比如由于一个或多个磁盘损坏而导致的I/O子系统缓慢,但很少有现成的代理可以帮助我们准确地诊断出应用的哪一部分出现了问题;又比如一个在成熟运行的业务所依赖的子系统,经过近期的几次业务代码变更后,如公共子系统的Redis的效率变得越来越差,所有依赖这些公共子系统都会连带收到系统卡顿或者响应超时的报错。虽然那些完全自我愈合应用有点像白日梦,从开发时间的角度看,也不太经济划算,但是 应用可以对最常见类型的故障进行自我诊断的理念,是一个令人钦佩而且可实现的愿望。
以Java应用系统为例,JVM自身提供了相应的性能监控手段和工具,但这些分析工具主要是 侧重Java单方面的性能分析 ,需要通过我们的监控架构设计思路和框架,重新设计一套符合企业业务需求的应用性能监控系统,加入能够精准做到定位出代码级别的监控又或者实时抓取出异常的业务SQL及事务,配合可视化分析和预警,应用性能监控系统就可以直接、快速、有效的找到症结所在,并直观的把关键信息反馈给相关开发、运维人员。
比如现在有一套业务涵盖A,B,C之间的子系统(Subsystem)之间的调用关系,可能是Dubbo服务调用的、或是HTTP、Hessian、API等接口、又或是Rabbit MQ消息队列、异步线程调取等方式。总之,业务系统中的各子系统之间关系均采用到的主流技术来实现构建,那么如何完成发现A子系统的应用代码问题是通过B并对C造成问题的根源呢?
APM(Application Performance Management)的性能监测分析可以做到这一点,以云智慧透视宝为例,APM不仅能够在复杂系统中追踪服务及代码层级性能瓶颈,还能自动发现全局应用拓扑,做到端对端的应用分析概览,失误监控与分析,SQL脚本性能分析、代码堆栈抓取以及事务深度追踪等,帮助开发等部门提升工作效率。
透视宝APM监控架构思路
APM数据采集架构设计
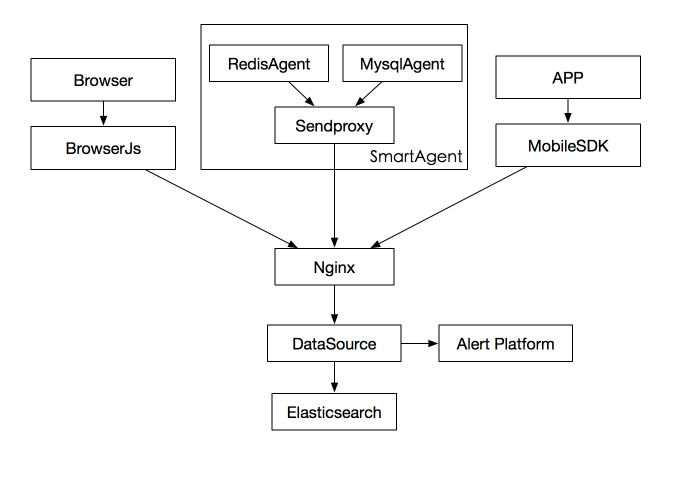
应用监控结构思路
透视宝的数据采集使用Sendproxy为SmartAgent的调度器,所有SmartAgent的数据都经过Sendproxy进行统一调度发送,推送到统一的大数据日志分析平台。
其主要优势在于
1) 发送队列保证各插件数据发送的稳定性;
2) 可以作为代理,部署在可联外网的主机中,保证局域网非联网环境的数据发送;
APM部署调试
1、 客户端简易安装
登录透视宝网站后台控制面板,在配置页面下载对应操作系统的Smart Agent,进行Smart Agent的安装和启动。
[root@sjm6-3G-qatest01-30 smart_agent]# ./SmartAgent.sh start
Starting SmartAgent daemon: SmartAgent
Restarting SmartAgent SendProxy daemon: bin/SendProxy
No Server (/apps/smart_agent/plugins/SendProxy/bin/SendProxy) running
Starting SmartAgent SendProxy daemon: bin/SendProxy
OK
OK
备注:
1、SendProxy: 通过SendProxy发送的数据。
2、 注册JavaAagent的应用监控服务
要监控Java应用,您需要在“插件管理”页面中安装并开启Java插件。
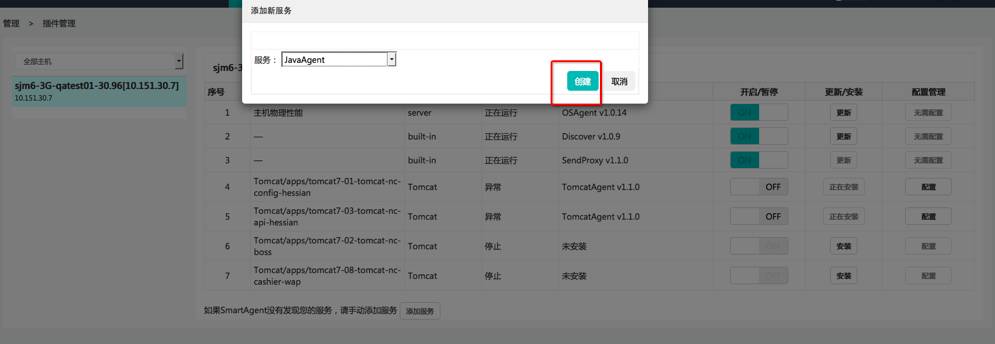
3、提供JavaAagent的部署
点击“安装”按钮安装JavaAgent 插件,安装时自动将JavaAgent下载到SmartAgent安装目录的smart_agent/plugins下,下载完成后开启插件。安装Java插件后,您还可以在Java插件conf目录中的app.conf文件中配置与数据采集相关的参数。
#/apps/smart_agent/plugins/Java_1459929876X1002x0
if [ "$1" = "start" -o "$1" = "run" ]; then
export JAVA_OPTS="$JAVA_OPTS
-Xbootclasspath/p:/apps/smart_agent/plugins/Java_1459929876X1002x0/conf
-javaagent:/apps/smart_agent/plugins/Java_1459929876X1002x0/lib/CAgent-1.0.0.
jar=/apps/smart_agent/plugins/Java_1459929876X1002x0"
fi
添加到TOMCAT的Catalina.sh的启动文件,见下图:
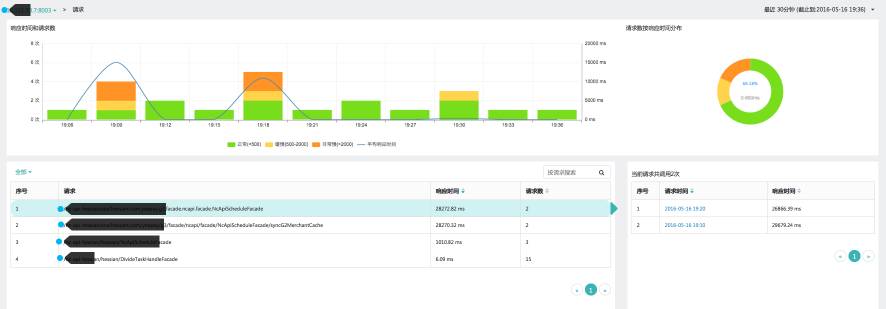
4、透视宝APM监控分析后台管理效果
配置需要大致两分钟,之后就可以在“应用”模块中查看数据,下面就是内网测试机部署的环境效果分析:


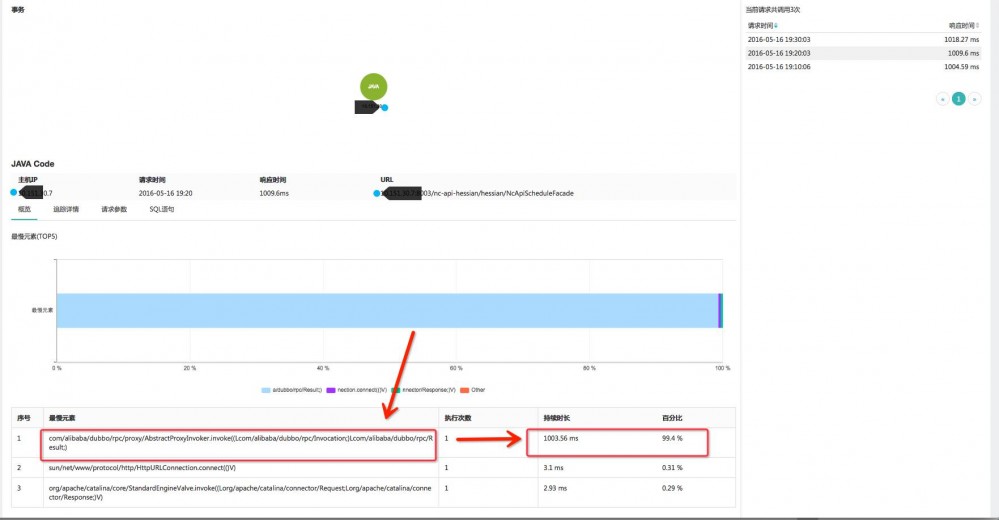
5、APM监控实时发现异常堆栈事务
通过透视宝,可以实时定位到异常堆栈事务的最缓慢元素,帮助开发人员快速解决代码问题,确保业务的正常运行。
感谢Chuck对文章存在的问题提出细致的改进意见。
感谢云智慧透视宝首席架构师Neeke提供的帮助和技术支持。
感谢NC小伙伴们的环境支持。

正文到此结束
- 本文标签: 测试 事故 安全 PaaS 时间 开源 http IO 定制 科技 网站 redis 需求 开发 主机 plugin root tar cat 数据 代码 操作系统 运营 ORM web 产品 调试 IaaS 参数 src Service java tomcat 互联网 UI API REST lib 调度器 目录 自动化 压力 配置 SOA 插件 Connection 下载 id 云 db 线程 安装 管理 消息队列 企业 文章 应用架构 classpath 数据库 sql 大数据 App dubbo 生命 MQ
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

