独家对话NIPS 2016最佳论文作者:如何打造新型强化学习观
12 月 5 日,机器学习和计算神经科学的国际顶级会议第 30 届神经信息处理系统大会(NIPS 2016)在西班牙巴塞罗那开幕。本届大会最佳论文奖(Best Paper Award)获奖论文是《Value Iteration Networks》。
2016 NIPS 最佳论文《Value Iteration Networks》的作者,是加州大学伯克利分校 Aviv Tamar、吴翼(Yi Wu)等人。这篇论文介绍了一个能学习设计策略,而不是被动的完全遵循策略的神经网络。同时,这种新的强化学习观并不是基于模型的(model-free)。机器之心第一时间联系到最佳论文的作者之一吴翼(Yi Wu),让他为我们详细讲述 VIN 的特点、应用方式和他的研究心得。

与最佳论文作者吴翼的对话
机器之心:恭喜获奖!能谈谈你的研究方向和最近工作吗?
答:我自己的研究兴趣比较广泛,主要考虑的问题是如何能够在 AI 模型中更好的表达人的先验知识,并利用这些人的已有知识,让模型利用更少的数据,做出更好的推断。
我做过的项目包括概率编程语言(probabilistic programming language)以及概率推理(probabilistic inference),层次强化学习(hierachical reinforcement learning)。
除此之外,这个假期我在北京的今日头条实验室做了 3 个月实习,期间利用层次化模型处理了一些与自然语言处理(natural language processing)相关的问题。回到 Berkeley 之后我也和一些相关教授合作,继续利用层次化模型做一些和 NLP 有关的问题。
机器之心:请简单介绍一下《Value IterationNetwork》的主题及 VIN 网络应用的场景 。
答:VIN 的目的主要是解决深度强化学习泛化能力较弱的问题。
传统的深度强化学习(比如 deep Q-learning)目标一般是采用神经网络学习一个从状态(state)到决策(action)的直接映射。神经网络往往会记忆一些训练集中出现的场景。所以,即使模型在训练时表现很好,一旦我们换了一个与之前训练时完全不同的场景,传统深度强化学习方法就会表现的比较差。
在 VIN 中,我们提出,不光需要利用神经网络学习一个从状态到决策的直接映射,还要让网络学会如何在当前环境下做长远的规划(learn to plan),并利用长远的规划辅助神经网络做出更好的决策。
通俗点来说叫:授人以鱼不如授人以渔。不妨说大家生活在北京,那么要怎么才能让一个人学会认路呢?传统的方法就是通过日复一日的训练,让一个人每天都从天安门走到西直门,久而久之,你就知道了长安街周边区域大致应该怎么走,就不会迷路了。但是如果这个人被突然扔到了上海,并让他从静安寺走到外滩,这个人基本就蒙了。VIN 提出的 learning to plan 的意义就在于,让这个人在北京学认路的时候,同时学会看地图。虽然这个人到了上海之后不认识路,但是如果他会看地图,他可以在地图上规划出从静安寺到外滩的道路,然后只要他能知道自己现在处在地图上的什么位置以及周边道路的方向,那么利用地图提供的额外的规划信息,即使这个人是第一次到上海,他也能成功的从静安寺走到外滩。
在文章中,我们提出了一种特殊的网络结构(value iteration module),这种结构和经典的规划算法 value iteration 有着相同的数学表达形式。利用这种数学性质,VIN 将传统的规划算法(planning algorithm)嵌入了神经网络,使得网络具有长期规划的能力。
VIN 中所使用的特殊结构,value iteration module,在很多问题上都可以直接加入现有的强化学习框架,并用来改进很多现有模型的泛化能力。
机器之心:你跟从 Russell 教授学习带来了哪些启发?
答:Berkeley 有着全世界最好的 AI 研究氛围和学者,我很幸运能够在 Berkeley 学习和研究。
我的导师 Stuart Russell 教授对我的影响是最大的。他改变了很多我对的科研观点和习惯,让我不要急功近利。在我比较艰难的时间段里他也不停的鼓励我,也对我在很多方面给予了很大的支持,信任和帮助。
此外我第一篇关于概率编程语言的论文也非常幸运得到了 Rastislav Bodik 教授的指导和帮助,不过很不凑巧,在我博士第一年结束之后他就被挖到了华盛顿大学(University of Washington)。
在强化学习方面,我得到了 Pieter Abbeel 教授,Sergey Levine 教授,Aviv Tarmar 博士,还有他们组里的很多博士生的帮助。他们都是领域里最厉害的学者,让我学到了非常多的东西。
在自然语言处理方面,我在今日头条实验室实习的时候得到了李磊博士的很多指导,回到 Berkeley 后,我和 David Bamman 教授也有合作,他也是圈内顶尖的学者,也总能给我提出很有价值的建议和指导。
机器之心:获得 BestPaper 是意料之中的事情吗?有什么感想?答:大家知道消息的时候还是挺意外的,也很高兴。毕竟 best paper 是个很高的荣誉,这一次 NIPS 也有很多非常非常优秀的工作,能够被选中,大家都非常开心。
论文: Value Iteration Networks

摘要
在本研究中,我们介绍了价值迭代网络(value iteration network, VIN):一个完全可微分的神经网络,其中嵌入了「规划模块」。VIN 可以经过学习获得规划(planning)的能力,适用于预测涉及基于规划的推理结果,例如用于规划强化学习的策略。这种新方法的关键在于价值迭代算法的新型可微近似,它可以被表征为一个卷积神经网络,并以端到端的方式训练使用标准反向传播。我们在离散和连续的路径规划域和一个基于自然语言的搜索任务上评估了 VIN 产生的策略。实验证明,通过学习明确的规划计算,VIN 策略可以更好地泛化到未见过的新域。
引言
过去十年中,深度卷积神经网络(CNN)已经在物体识别、动作识别和语义分割等任务上革新了监督学习的方式。最近,CNN 被用到了需要视觉观测的强化学习(RL)任务中,如 Atari 游戏、机器人操作、和模拟学习(IL)。在这些任务中,一个神经网络(NN)被训练去表征一个策略——从系统状态的一个观测到一个行为的映射,其目的是表征一个拥有良好的长期行为的控制策略,通常被量化为成本随时间变化的一个序列的最小化。
强化学习(RL)中决策制定的连续性(quential nature)与一步决策(one-step decisionsin)监督学习有本质的不同,而且通常需要某种形式的规划。然而,大部分最近的深度强化学习研究中都用到了与监督学习任务中使用的标准网络十分相似的神经网络架构,通常由用于提取特征的 CNN 构成,CNN 的所有层都连在一起,能将特征映射到行动(action)的概率分布上。这样的网络具有内在的反应性,同时特别的一点是它缺乏明确的规划计算。序列问题中反应策略的成功要归功于该学习算法,它训练了一个反应策略去选择在其训练领域有良好长期结果的行动。
为了理解为什么一个策略(policy)中的规划(planning)是一个重要的要素,可以参考一下图 1(左)中网格世界的导航任务,其中的 agent 能观测其域的地图,并且被要求在某些障碍之间导航到目标位置。有人希望训练一个策略后能解决带有不同的障碍配置的该问题的其他几个实例,该策略能泛化到解决一个不同的、看不见的域,如图 1(右)显示。然而,根据我们的实验显示,虽然标准的基于 CNN 的网络能被轻易训练去解决这类地图的一个集合,它们却无法很好的泛化到这个集合之外的新任务中,因为它们不理解该行为的基于目标的形式。这个观察结果显示被反应策略(reactive policy)学习的计算不同于规划(planning),它需要解决的是一个新任务。
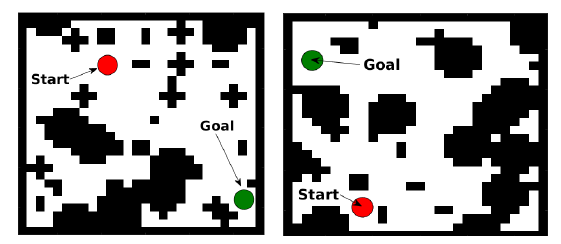
图 1:一个网格世界域的两个实例。任务在障碍之间移动到全局。
在这个研究中,我们提出了一个基于神经网络的策略(policy),它能有效地去学习规划(plan),我们的模型,termeda 值迭代网络(VIN),有一个可微分的「规划程序」,被植入了该神经网络结构。我们方法的关键是观测到经典值迭代(VI)规划算法可能由一个 特定类型的 CNN 表征。通过将这样一个 VI 网络模块植入到一个标准的前馈分类网络中,我们就获得了一个能学习一个规划计算的神经网络模型。这个 VI 模块是可微分的,而且整个网络能被训练去使用一个标准的反向传播。这就让我们的策略简单到能训练使用标准的强化学习和模拟学习算法,并且直接与神经网络整合,用于感知和控制。
我们的方法不同于基于模型的强化学习,后者需要系统识别以将观测映射到动力学模型中,然后产生解决策略。在强化学习的许多应用中,包括机器人操纵和移动场景中,进行准确的系统识别是极其困难的,同时建模错误会严重降低策略的表现。在这样的领域中,人们通常会选择无模型方法。由于 VIN 仅是神经网络策略,它可以进行无模型训练,不需要进行明确的系统识别。此外,通过训练网络端到端可以减轻 VIN 中的建模误差的影响。
我们证明了 VIN 可以有效应用于标准的强化学习和模拟学习算法中的各种问题,其中包括需要视觉感知,连续控制,以及在 WebNav 挑战中的基于自然语言的决策问题。在训练之后,策略学习将观察映射到与任务相关的规划计算中,随后基于结果生成动作预测的计划。正如我们所展示的结果,这种方式可以更好地为新的,未经训练的任务形式的实例归纳出更好的策略。
结论和展望
强大的和可扩展的强化学习方法为深度学习开启了一系列新的问题。然而,最近很少有新的研究探索如何建立在不确定环境下规划策略的架构,目前的强化学习理论和基准很少探究经过训练的策略的通用性质。本研究通过更好地概括策略表示的方法,朝着这个方向迈出了一步。
我们提出的 VIN 方法学习与解决任务相关的大致策略并计算规划,同时,我们已经在实验中证明,这样的计算方式在不同种类任务中具有更好的适用性,从简单的适用性价值迭代的网格世界,到连续控制,甚至到维基百科链接的导航。在未来的研究中,我们计划向基于模拟或最优线性控制学习的方向开发不同的计算规划方式,并将它们与反应策略相结合,从而为任务和运动规划拓展新的强化学习解决方案。
以下是最佳论文《Value Iteration Networks》相关的演讲幻灯片介绍,演讲者为该论文的第一作者、 Berkeley AI Research Lab (BAIR) 博士后 Aviv Tamar。
 P1-6:介绍
P1-6:介绍
对于自动化机器人的目标(比如命令机器人打开冰箱给你拿牛奶瓶),用强化学习可以吗?深度强化学习从高维的视觉输入中学习策略,学习执行动作,但它理解这些策略和动作吗?可以简单测试一下:泛化到一个网格世界中。
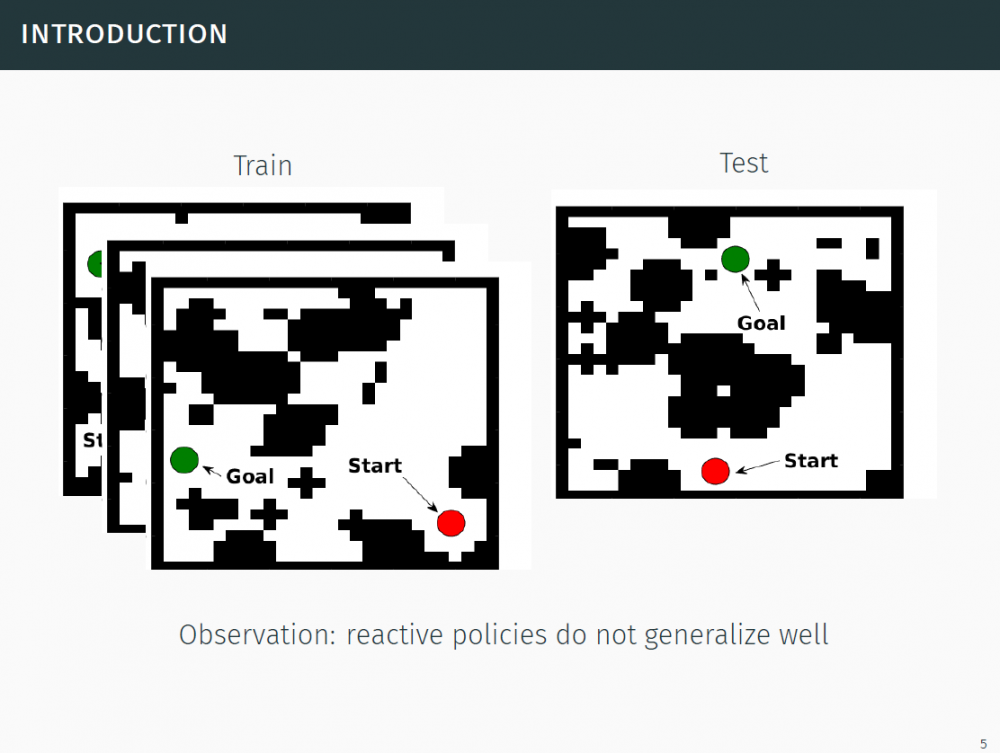
P7-10:观察:反应性策略(reactive policies)的泛化效果并不好。
为什么反应性策略的泛化效果不好呢?
一个序列任务需要一个规划计算(planning computation)
强化学习绕过了它——而是学习一个映射(比如,状态→Q 值,状态→带有高返回(return)的动作,状态→带有高优势(advantage)的动作,状态→专家动作,[状态]→[基于规划的项])
Q/返回/优势:在训练域(training domains)上的规划
新任务:需要重新规划(re-plan)
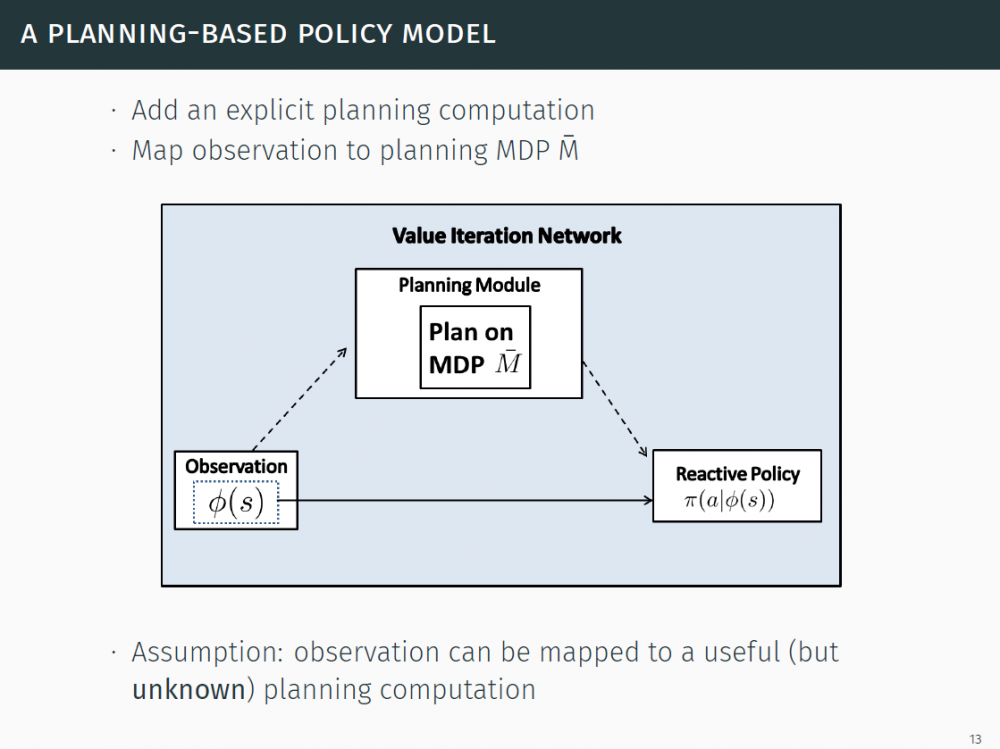
P11:在这项成果中,我们可以学习规划和能够泛化到未见过的任务的策略。
P12-14:背景
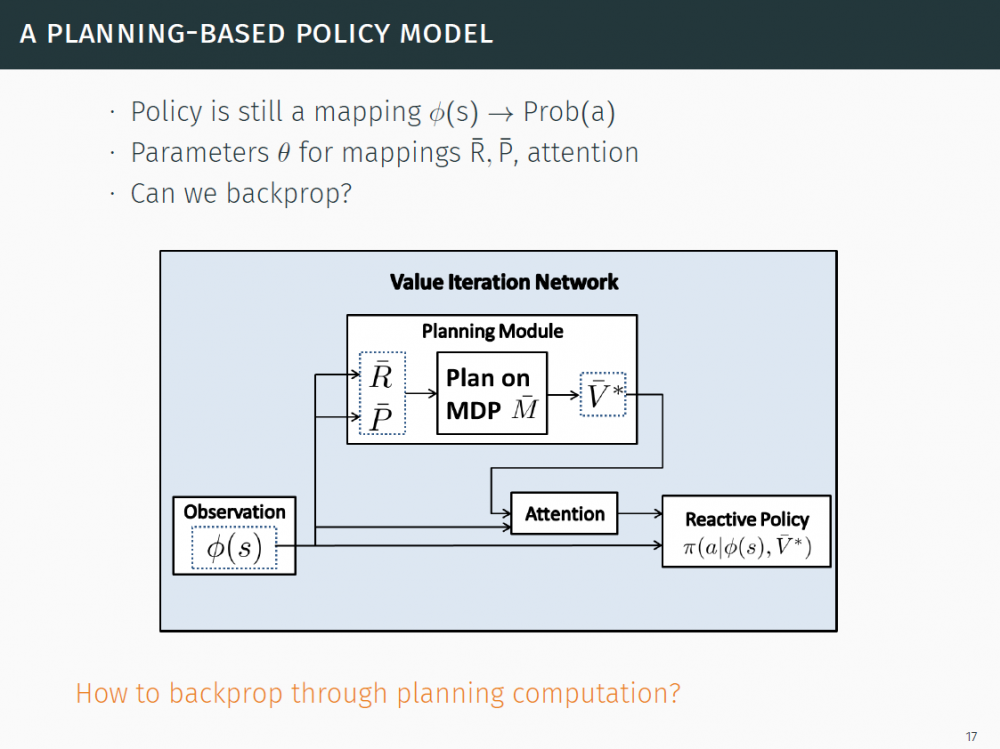
P16-21:一种基于规划的策略模型
从一个反应性策略开始
加入一个明确的规划计算
将观察(observation)映射到规划 MDP
假设:观察可被映射到一个有用的(但未知的)规划计算
神经网络将观察映射成奖励和转变(transitions)
然后,学习这些
怎么去使用这种规划计算?
事实 1 :值函数 = 关于规划的足够信息
思路 1:作为特征向量加入反应性策略
事实 2:动作预测可以仅需要 V-*的子集
类似于注意模型,对学习非常有效
策略仍然是一个映射 g ϕ(s) → Prob(a)
映射 R-、P-、注意的参数 θ
我们可以反向传播吗?
反向传播怎么通过规划计算?
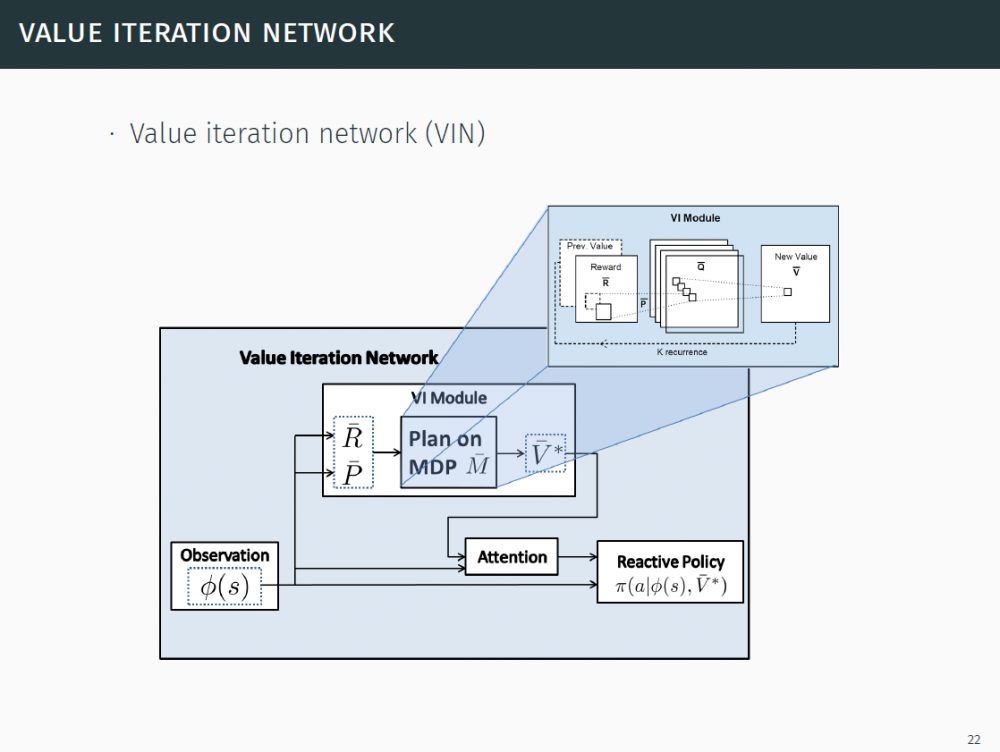
P22-23:价值迭代=卷积网络
P24-27:价值迭代网络(VIN)
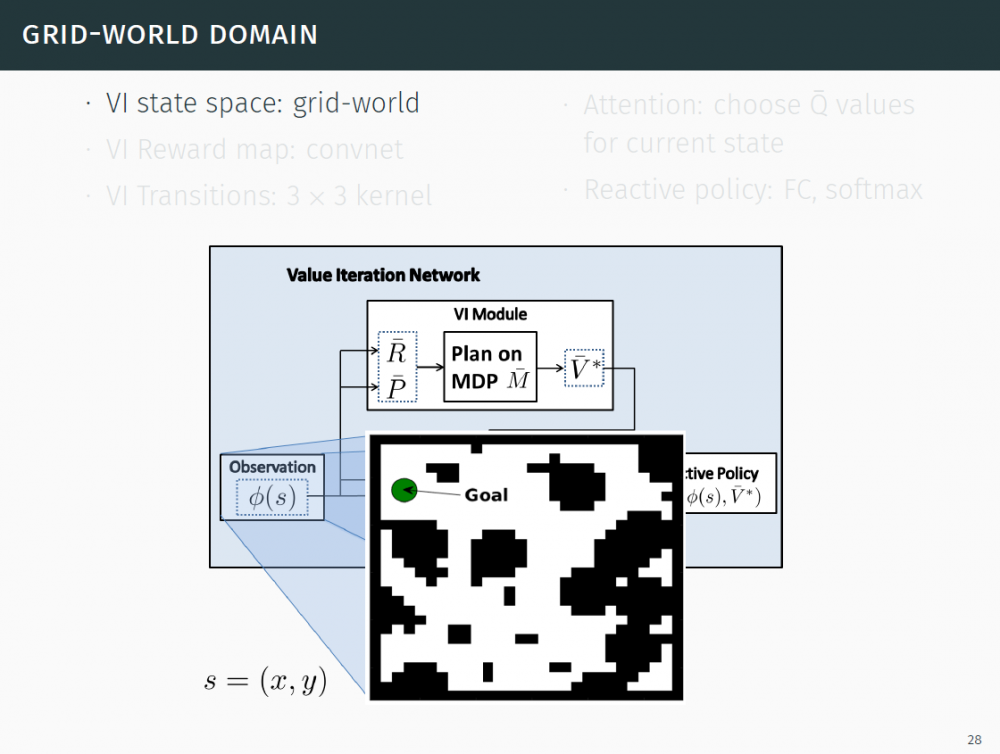
P28-29:实验
问题:
1.VIN 能学习规划计算吗?
2.VIN 能够比反应策略泛化得更好吗?

P30-46:网格世界域

P47-51:火星导航域
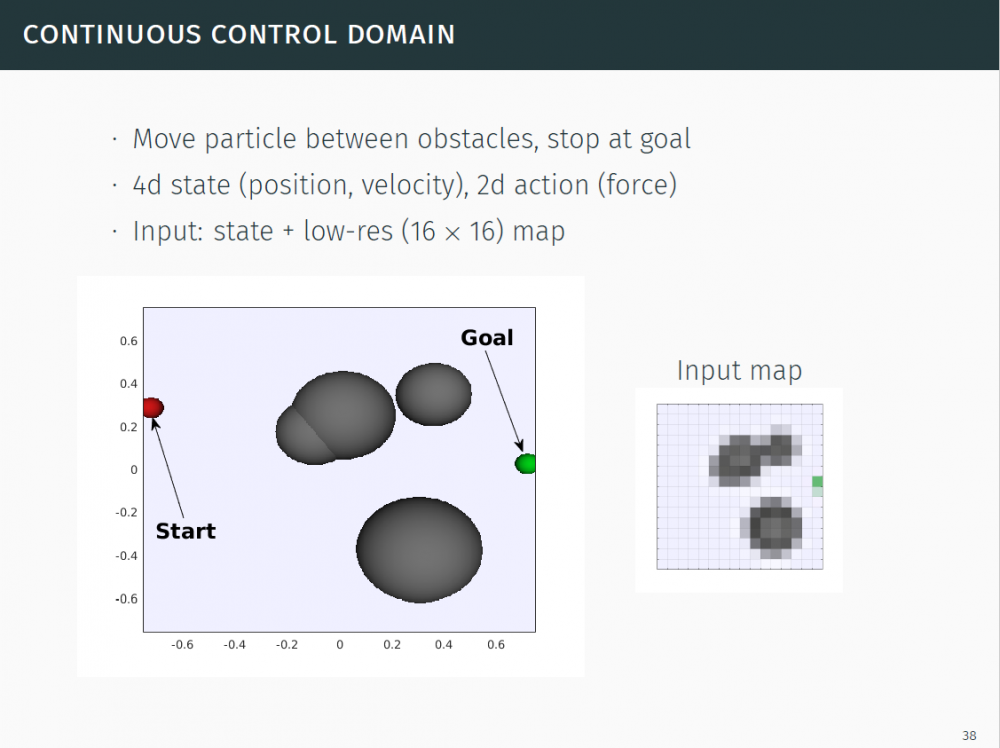
P52-59:连续控制域
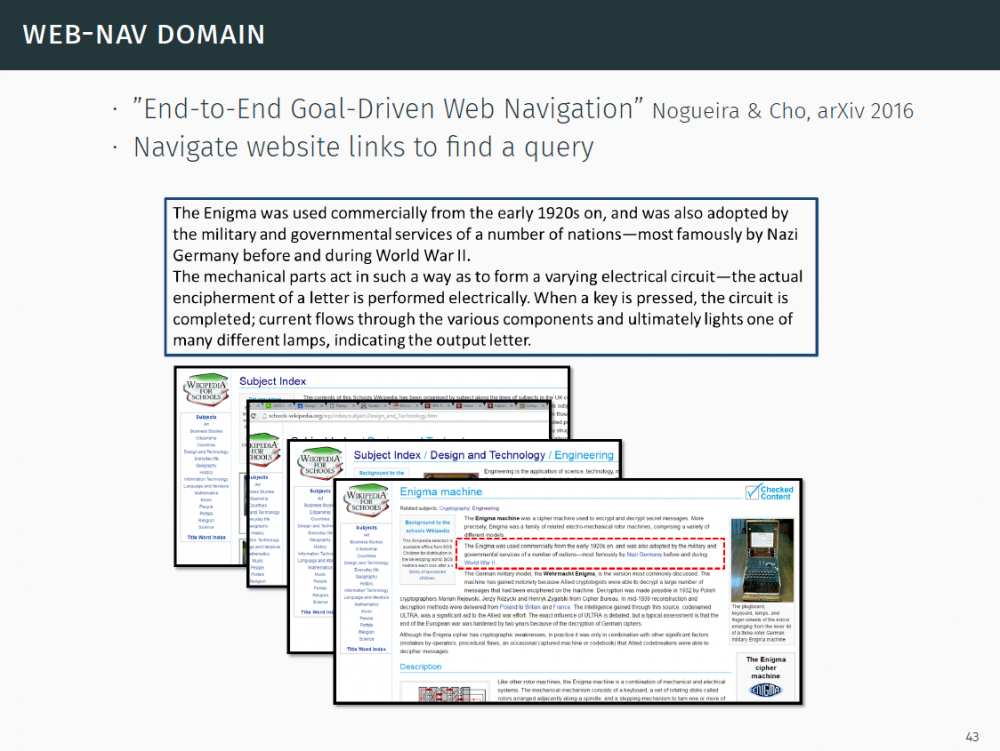
P60-72:网页导航域:基于语言的搜索

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

