线上故障处理
前些天看到caoz一篇文章 出了bug怎么办 提到bug修复问题,之后airbnb的朱赟发了 当工程师收到了 Bug Report ,都谈到了bug修复的问题。互联网行业面对的用户量较大,程序中可能有的bug最后都会在线上出现;如果bug的影响范围变大,则会演变成线上故障,造成较大范围的业务影响。
前段时间在团队内整理了一份线上事故处理的流程,修改后在这里分享。
1. 故障信息获取源
1.1 系统&业务报警
这个是获取故障最常用的手段。
一般的系统正常运营过程中都会有一定的指标监控。如:在系统层面某种报错出现的次数,系统常规指标,如可用内存,JVM GC,连接池等信息;业务指标,如业务的曲线异于基准线。
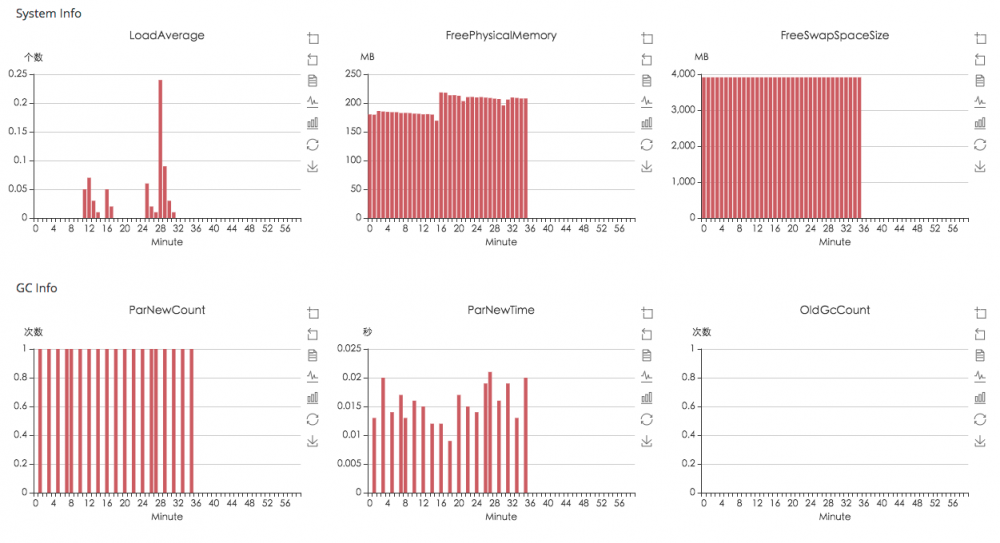
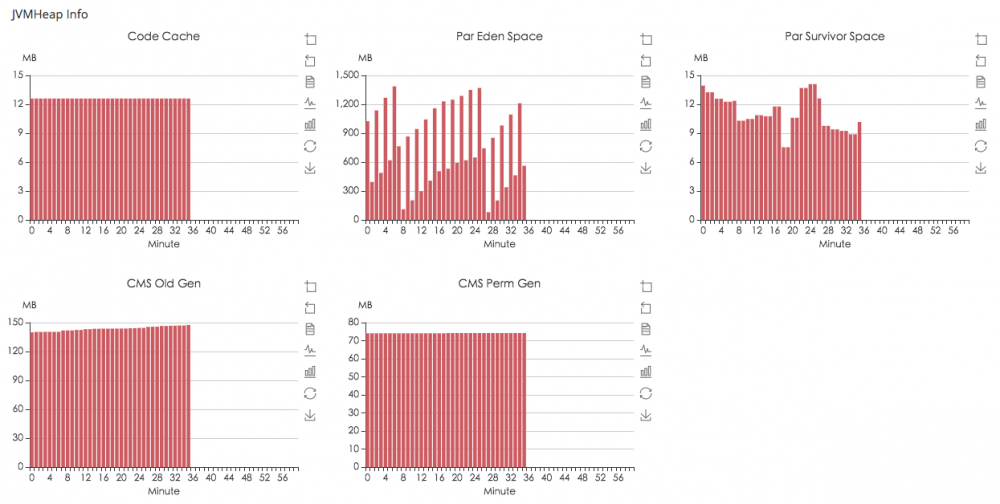
如配置一些基本的业务曲线:
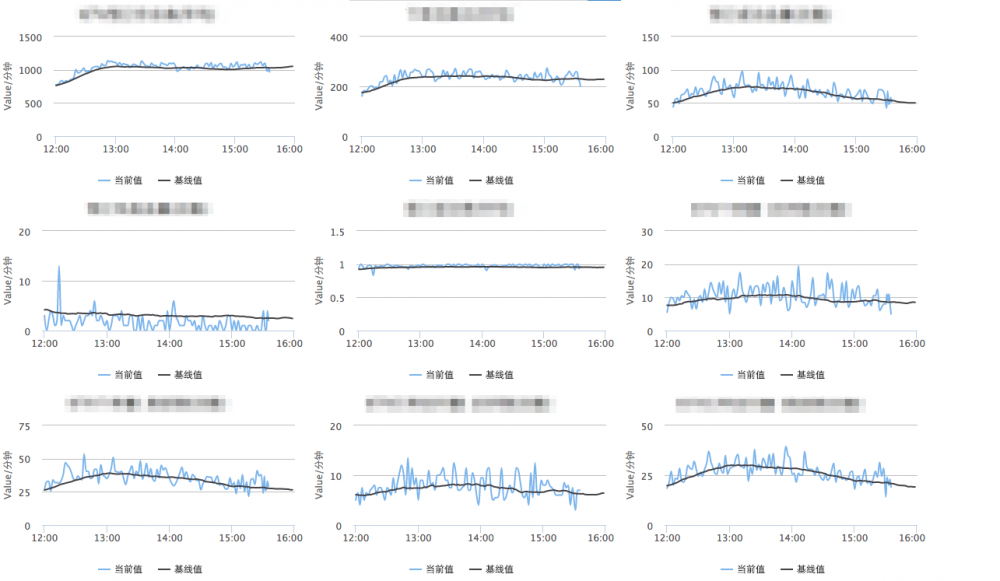
当业务曲线发生异常抖动的时候,就可以主动报警,可以实时的开发
这种报错出现之后比用户反馈的要好排查,因为这种bug影响范围较大,可重现的。
1.2 用户反馈
这里的用户主要是公司的客服人员,一般客服人员会手机普通用户的问题,并做分类统计,如果发现某种现象比较集中,就很可能是系统出现故障。
一般当系统&业务监控不够全面的时候会部分依赖用户反馈来发现系统问题。
2 处理流程
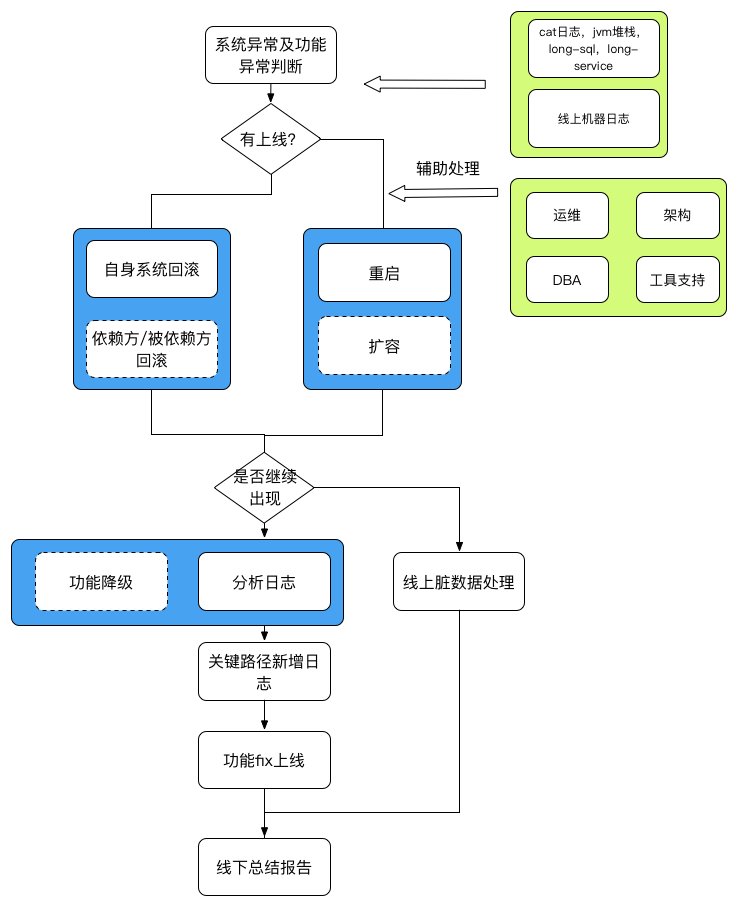
2.1 判断影响范围
收到故障报告之后需要迅速判断故障的影响范围,系统/业务报警类的故障影响范围都会比较大,很多时候都会是事故;用户反馈的bug,因为情况复杂,比如设备问题、网络问题、用户操作逻辑等,而且因为用户并非专业人员所以用户的现场数据难以收集全面,所以针对这类bug的影响范围就难以判断。
针对第二种bug的影响范围判断,需要根据已有的用户描述现象以及相关后台数据,判断用户是在什么情况下出现这种bug;特别需要检查后台数据是否大量类似数据,以辅助判断bug是否为大范围影响,是否已经达到事故的影响范围。
2.2 回滚,重启,扩容
这个是线上处理最常用也是最管用的三种方法。
根据我的工作经验,线上近80%的故障是因为新上线导致的,所以遇到线上问题的时候,如果短期内有项目上线,如果该故障影响范围较大,需要优先考虑将项目回滚或者将新功能的入口关闭以降低风险。
还有一些故障是系统运行到一段时间后系统自身的连接池,内存等耗尽,为了尽快解决问题需要马上重启;不过为了后续继续分析问题,一般会留一台线上机器尸体做后续分析。
还有一些问题是线上流量突然增大,如运营活动上线,这时候需要联合运维一起判断,该如何扩容来解决问题。一般的扩容方式是增加线上机器,增大数据库连接池,增加数据库读库等方式。
2.4 降级/临时方案
事故出现之后,首先要考虑的就是消除线上现象,这时候需要一些降级方案或者临时方案,可以让系统继续运行,不影响后续用户的正常使用。
比如用户进入一个native的列表页,这个列表页频繁的crash,可以app已经发版了,已经较大范围的影响了用户,这时候如果有个h5的页面可以替换,直接在服务端决定使用哪种页面,就可以有效消除故障。
降级/临时方案一般是通过削减非必要功能来保证核心功能的正常运行,比如h5页面替代native之后,通过降低体验可以让用户继续使用功能。
3 故障后处理
经过以上处理之后,线上故障基本消除了,但有些故障需要深入分析之后才能根除;还有些故障修复之后,但会有些脏数据已经写入,需要针对这些脏数据针对性的修复。有些在虽然消除了线上出错,但还需要继续对代码进行调整以消除bug。
一般事故后处理主要包括以下内容:
-
线上脏数据处理,挽回可挽回的损失
一些事故会造成实质性的经济损失,其中部分经济损失可以通过技术手段挽回。比如在给商家结算打钱的时候多打了,这部分钱可以通过正常反结算方式追回;或者一些用户在未付款的情况下购买商品成功了,针对这部分订单可以通过取消订单的方式挽回。
-
测试环境复现bug,分析事故原因
尽量在测试环境复现bug,这样可以仔细分析bug的根本原因,一般代码逻辑导致的bug在测试环境都可以复现。但一些bug只会在特定情况下才会程序出现,比如流量达到一定阈值之后,会触发JVM的GC问题等;针对这种问题优先分析线上日志信息及系统监控信息,分析线上留下的机器实体,之后再试图在测试环境复现。
-
修复及优化措施
代码逻辑bug的修复,通过正常的业务测试正常上线即可。针对上面系统问题导致的,可以灰度上线一台机器以验证是否解决了问题。
-
事故报告
不再详述。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

