外卖排序系统特征生产框架
背景
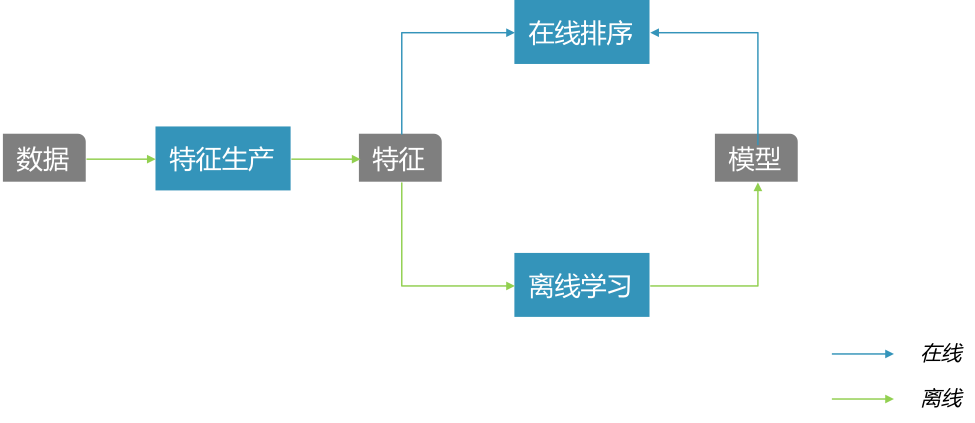
图1 外卖排序系统框架
外卖的排序策略是由机器学习模型驱动的,模型迭代效率制约着策略优化效果。如上图所示,在排序系统里,特征是最为基础的部分:有了特征之后,我们离线训练出模型,然后将特征和模型一起推送给线上排序服务使用。特征生产Pipeline对于策略迭代的效率起着至关重要的作用。经过实践中的积累和提炼,我们整理出一套通用的特征生产框架,大大节省开发量,提高策略迭代效率。
外卖排序系统使用GBDT(Gradient Boosting Decision Tree)树模型,比较复杂。受限于计算能力,除了上下文特征(如时间、地域、终端类型、距离等)之外,目前使用的主要是一些宽泛的统计特征,比如商家销量、商家单均价、用户的品类偏好等。这些特征的生产流程包括:离线的统计、离线到在线的同步、在线的加载等。
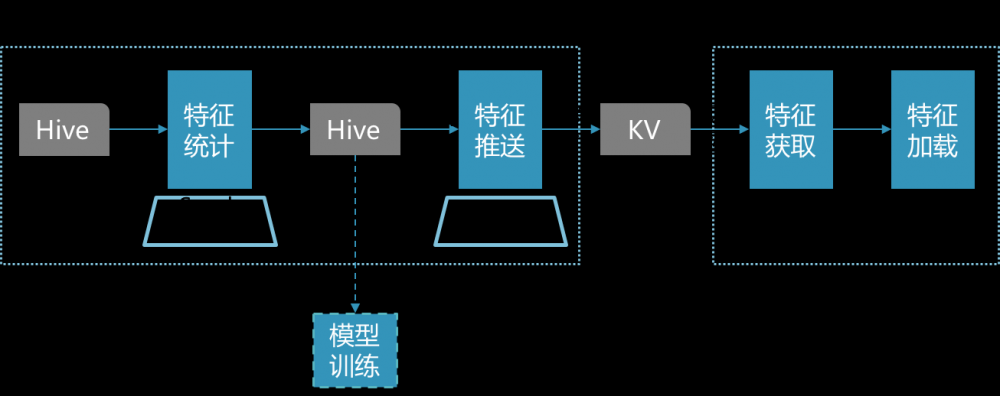
图2 特征生产流程
如上图,目前外卖排序的特征生产流程主要有:
-
特征统计:基于基础数据表(如曝光表、点击表、订单表等),统计若干时段内特定维度的总量、分布等,如商家月均销量、用户不同品类下单占比。统计结果存储于Hive表。这部分工作,简单的可基于ETL,复杂的可基于Spark。产出的特征可供离线训练和线上预测, 本文主要围绕线上展开 。
-
特征推送:Hive表里的数据需要存入KV,以便线上实时使用。这一步,首先要将Hive表里的记录映射成POJO类(称为 Domain 类),然后将其序列化,最后将序列化串存入KV。这部分工作比较单一,基于MapReduce实现。
-
特征获取:在线服务根据需求,从KV中取出数据,并反序列化为Domain对象。
-
特征加载:针对模型所需特征列表,取得对应的Domain对象。这步通过调用特征获取实现。
前两步为离线操作,后两步为在线操作。特征同步由离线推送和在线获取共同完成。离线生产流程是一个周期性的Pipeline,目前是以天为周期。
为此,我们设计了一套通用的框架,基于此框架,只需要简单的配置和少量代码开发,就可以新增一组特征。下文将详细介绍框架的各个部分。
特征统计
排序模型用到的特征大部分是统计特征。有些特征比较简单,如商家的月均销量、商家单均价等,可用ETL统计(GROUP BY + SUM/AVG);有些特征稍微复杂,如用户的品类偏好(在不同品类上的占比)、用户的下单额分布(不同金额区段的占比),用ETL就比较繁琐。针对后一种情况,我们开发了一套Spark程序来统计。我们发现,这种统计需求可以规约成一种范式:针对某些 统计对象 (用户、商家)的一些 维度 (品类、下单额),基于某些 度量值 (点击、下单)做 统计 (比例/总和)。
同一对象,可统计不同维度;同一维度,有不同的度量角度;同一度量角度,有不同的统计方式。如下图:
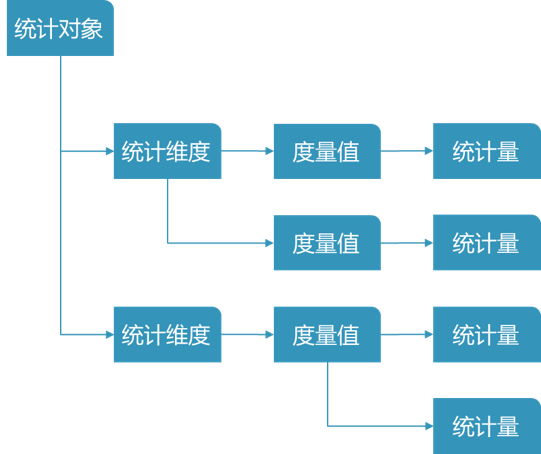
图3 特征统计范式
例如,对于用户点击品类偏好、用户下单品类偏好、用户下单额分布、用户下单总额等特征,可做范式分解:
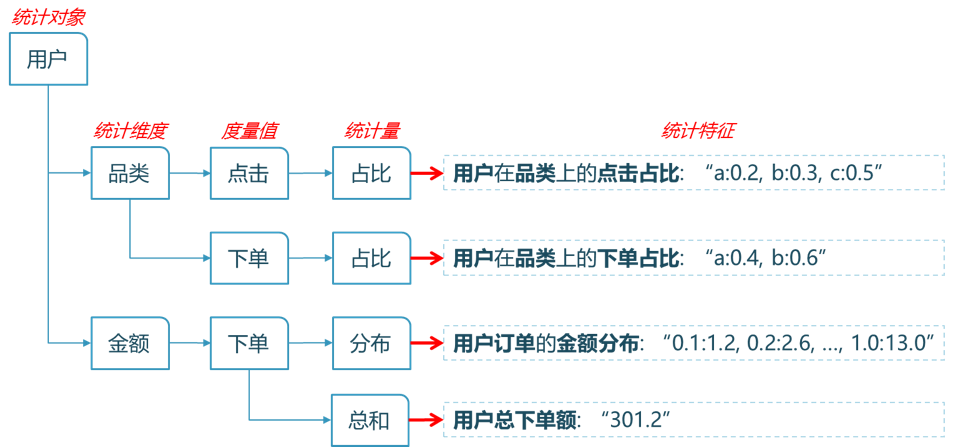
图4 特征统计范式示例
其中,
-
统计对象、统计维度、度量值对应于Hive表中的字段(维度一般来自维度表,度量值一般来自事实表,主要是曝光、点击、下单)。为了增加灵活性,我们还允许对原始Hive字段做加工,加工后的值作为统计维度、度量值(加工的接口我们分别称为维度算子和度量算子)。
-
统计量基于度量值做的一些聚合操作,如累加、求均值、拼接、求占比、算分位点(分布)。前两者输出一个数值,后三者输出形如"Key1:Value1,Key2:Value2"的KeyValue列表。
另外,统计通常是在一定时间窗口内进行的,由于不同时期的数据价值不同(新数据比老数据更有价值),我们引入了 时间衰减 ,对老数据降权。
基于以上考虑,整个统计流程可以分解为(基于Spark):
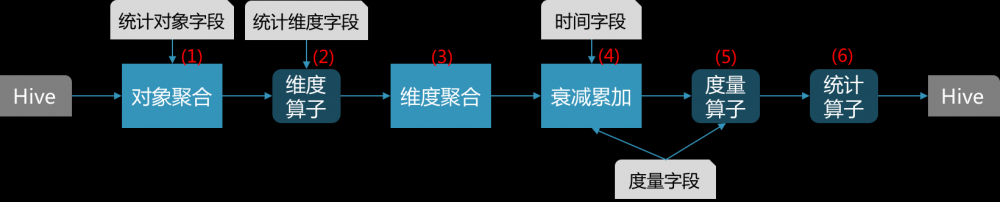
图5 特征统计流程
-
按统计对象字段做聚合(GROUP BY)。统计对象字段由配置给定。对于外卖排序主要为uuid、poi_id。这一步可能会有数据倾斜,需要更多优化。
-
计算维度。支持维度算子,可以对原始维度字段做处理,如对金额字段做分段处理,以分段后的金额作为维度。
-
按统计维度聚合(GROUP BY)。这是在对象聚合的基础上做的二次聚合。维度字段由配置给定,可以有多个字段,表示交叉特征统计,如不同时段的品类偏好,维度字段为:时段、品类。
-
时间衰减并累加。衰减各个时间的度量值,并把所有时间的度量值累加,作为加权后的度量值。时间字段和度量字段由配置给定。时间字段主要为日期,度量字段主要为曝光、点击、下单。经过维度聚合后,度量值都在特定维度值对应的记录集上做累加,每个维度对应一个度量值,维度和度量值是一个KeyValue的映射关系。
-
计算度量值。度量字段也可以通过度量算子做进一步处理,算子得到的结果作为度量值。也可以有多个字段,如点击和曝光字段,配合除法算子,可以得到点击率作为度量值。
-
计算统计量。经过对象和维度聚合后,对象、维度、度量值建立了二级映射关系:对象维度度量值,相当于一个二维Map:Map<对象, Map<维度, 度量值>>。统计量是对Map<维度, 度量值>做一个聚合操作。每个统计量对应输出Hive表中的一个字段。现在主要支持如下几种算子:
-
累加:对该维度的所有度量值求和;
-
求均值:该维度所有取值情况对应的度量值的均值;
-
拼接:把Map<维度, 度量值>序列化为"Key1:Value1, Key2:Value2"形式,以便以字符串的形式存储于一个输出字段内。为了防止序列化串太长,可通过配置设定只保留度量值最大的top N;
-
求占比:该维度所有取值情况对应的度量值占度量值总和的比重,即Map<维度, 度量值/Sum(度量值)>。然后再做拼接输出;
-
算分位点:有时候想直到某些维度的分布情况,比如用户下单金额的分布以考察用户的消费能力。分位点可以作为分布的一种简单而有效的表示方法。该算子输出每个分位点的维度值,形如"分位点1:维度值1, 分位点2:维度值2"。此时,度量值只是用来算比值。
维度算子、 度量算子 、 统计算子 都可以通过扩展接口的方式实现自定义。
如下是统计用户点击品类偏好、用户下单品类偏好、用户下单额分布的配置文件和Hive表示例([Toml] [1] 格式)
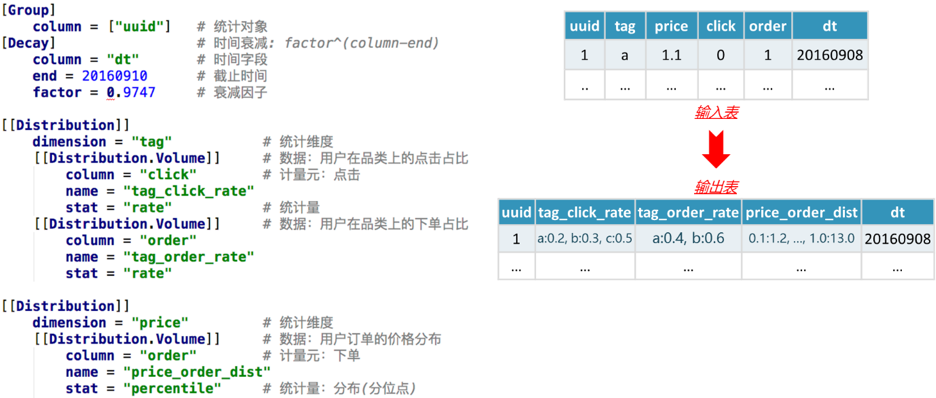
图6 特征统计配置示例
相对于ETL,这套Spark统计框架更为简单清晰,还可以同时统计多个相关的特征。通过简单的配置就可以实现特征的统计,开发量比较小。
特征同步
离线统计得到的特征存储在Hive表中,出于性能的考虑,不能在线上直接访问。我们需要把特征从Hive中推送到更为高效的KV数据库中,线上服务再从KV中获取。整个同步过程可以分为如下步骤:

图7 特征推送流程
-
ORM:将Hive表中的每行记录映射为Domain对象(类似于[Hibernate] [2] 的功能)
-
序列化:将Domain对象序列化,然后存储到KV中。一个Domain类包含一组相关的、可同时在一个任务中统计的特征数据。每个Domain对象都有一个key值来作为自己唯一的标志—实现key()接口。同时,由于不同类型的Domain都会存储在一起,我们还需要为每种类型的Domain设定一个Key值前缀prefix以示区别。因此,KV中的Key是Domain.prefix + Domain.key,Value是序列化串。我们支持json和protostuff两种序列化方式。
-
反序列化:在线服务根据key和Domain.prefix从KV中得到序列化串,并反序列化为Domain对象。
前两步为离线操作,第三步为在线操作(在预测代码中被调用)。
我们针对Hive开发了一套ORM库(见图8),主要基于Java反射,除了支持基本类型(int/long/float/double/String等),还支持POJO类型和集合类型(List/Map)。因为ETL不支持json拼接,为了兼容基于ETL统计的特征数据,我们的POJO以及集合类型是基于自定义的规范做编解码。针对Spark统计的特征数据,后续我们可以支持json格式的编解码。
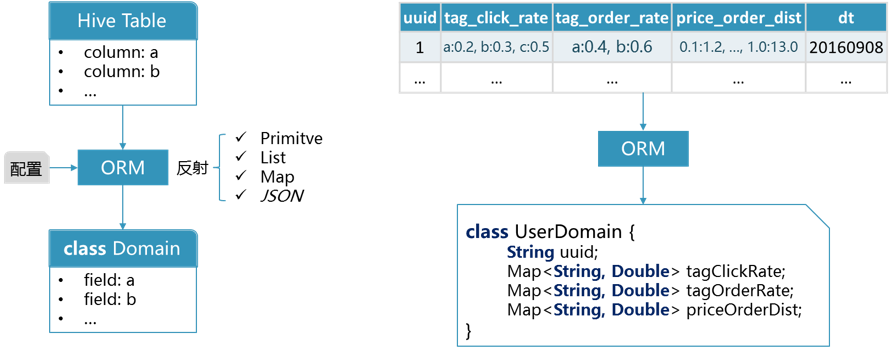
图8 Hive ORM示意
特征序列化和反序列我们统一封装为通用的 KvService :负责序列化与反序列,以及读写KV。如下图:
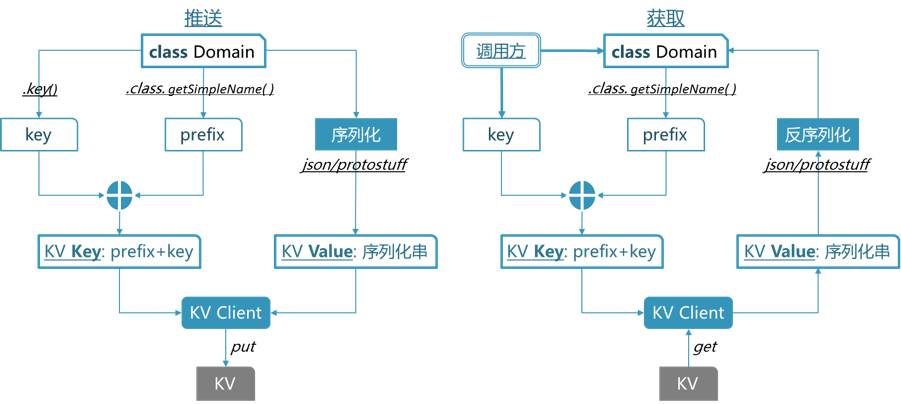
图9 KvService
对于新特征,只需要定义一个Domain类,并实现接口key()即可,KvService自动完成Key值的拼接(以Domain的类名作为Key的prefix),序列化和反序列化,读写KV。
我们通过周期性的离线MapReduce任务,读取Hive表的记录,并调用KvService的put接口,将特征数据推送到KV中。由于KvService能够统一处理各种Domain类型,MapReduce任务也是通用的,无需为每个特征单独开发。
对于特征同步,只需要开发Domain类,并做少量配置,开发量也很小。目前,我们为了代码的可读性,采用Domain这种强类型的方式来定义特征,如果可以弱化这种需求的话,还可以做更多的框架优化,省去Domain类开发这部分工作。
特征加载
通过前面几步,我们已经准备好特征数据,并存储于KV中。线上有诸多模型在运行,不同模型需要不同的特征数据。特征加载这一步主要解决怎么高效便捷地为模型提供相应的特征数据。
离线得到的只是一些原始特征,在线还可能需要基于原始特征做更多的处理,得到高阶特征。比如离线得到了商家和用户的下单金额分布,在线我们可能需要基于这两个分布计算一个匹配度,以表征该商家是否在用户消费能力的承受范围之内。
我们把在线特征抽象为一个特征算子: FeatureOperator 。类似的,一个特征算子包含了一组相关的在线特征,且可能依赖一组相关的离线特征。它除了封装了在线特征的计算过程,还通过两个Java Annotation声明该特征算子产出的特征清单(@ Features )和所需要的数据清单(@ Fetchers )。所有的数据获取都是由 DataFetcher 调用 KvService 的get接口实现,拿到的 Domain 对象统一存储在 DataPortal 对象中以便后续使用。
服务启动时,会自动扫描所有的FeatureOperator的Annotation(@Features、@Fetchers),拿到对应的特征清单和数据清单,从而建立起映射关系:FeatureFeatureOperatorDataFetcher。而每个模型通过配置文件给定其所需要的特征清单,这样就建立起模型到特征的映射关系(如图9):
Model → Feature → FeatureOperator → DataFetcher
不同的在线特征可能会依赖相同的离线特征,也就是FeatureOperatorDataFetcher是多对多的关系。为了避免重复从KV读取相同的数据以造成性能浪费,离线特征的获取和在线特征的抽取被划分成两步:先汇总所有离线特征需求,统一获取离线特征;得到离线特征后,再进行在线特征的抽取。这样,我们也可以在离线特征加载阶段采用并发以减少网络IO延时。整个流程如图10所示:
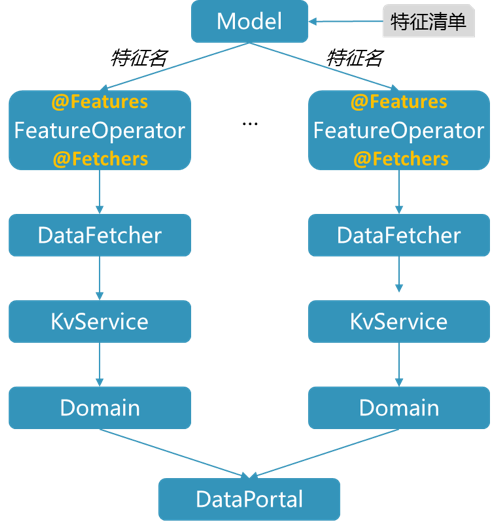
图10 模型和特征数据的映射关系
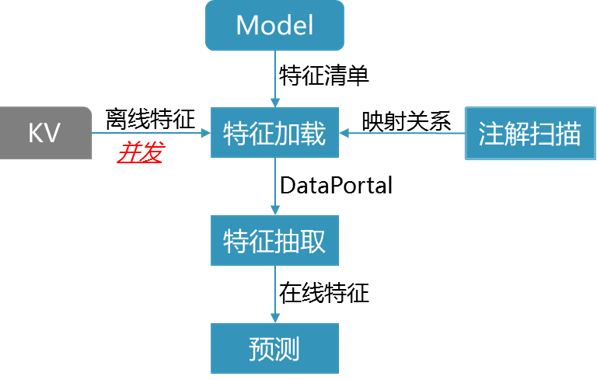
图11 特征加载流程
对于新特征,我们需要实现对应的FeatureOperator、DataFetcher。DataFetcher主要封装了Domain和DataPortal的关系。类似的,如果我们不需要以强类型的方式来保证代码的业务可读性,也可以通过优化框架省去DataFetcher和DataPortal的定制开发。
总结
我们在合理抽象特征生产过程的各个环节后,设计了一套较为通用的框架,只需要少量的代码开发(主要是自定义一些算子)以及一些配置,就可以很方便地生产一组特征,有效地提高了策略迭代效率。
参考文献
- TPML .
- Hibernate ORM .
不想错过技术博客更新?想给文章评论、和作者互动?第一时间获取技术沙龙信息?
请关注我们的官方微信公众号“美团点评技术团队”。现在就拿出手机,扫一扫:

正文到此结束
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

