【读薄《编程珠玑》】贰 啊哈!算法
这篇文章是[《读薄<编程珠玑>》系列博客][1]的第 贰 篇,在这篇文章中,作者提出了三个问题,并且给出了相应的解决方案,本文阐述了这三个问题以及解决方案,并且对课后习题进行了分析。
问题集合
-
0x00: 给定一个最多包含40亿个随机排列的32位整数的顺序文件,找出一个不在文件中的32位整数(在文件中至少缺失一个这样的数)。在具有足够内存的情况下,如何解决该问题?如果有几个外部的『临时』文件可用,但是仅有几百字节的内存,又该如何解决该问题?
-
0x01: 将一个 n 元一维向量向左旋转 i 个位置。例如,当 n=8, i=3 时,向量 abcdefg 旋转为 defgabc。简单的代码使用一个 n 元的中间向量在 n 步内完成该工作。你能否仅适用数十个额外字节的存储空间,在正比于 n 的时间内完成向量的旋转?
-
0x02: 给定一个英语字典,找出其中的所有变位词的集合。例如,『pots』、『stop』、『tops』互为变位词,因为每个单词都能通过改变其他单词中的字母顺序来获得。
-
0x03:考虑查找给定输入单词的所有变位词问题。仅给定单词和词典的情况下,如何解决该问题?如果有一些时间和空间可以在响应任何查询之前预先处理字典,又会如何?
-
0x04:给定包含 4,300,000,000 个 32 位证书的顺序文件,如何找出一个至少出现两次的整数?
-
0x05:前面涉及了两个需要经敲代码来实现的向量旋转算法。将其分别作为独立的程序实现。在每个程序中,i 和 n 的最大公约数如何出现?
-
0x06:几位读者指出,既然所有的三个旋转算法需要执行的运行时间都正比于 n,杂技算法的运行速度显然是求逆算法的两倍。杂技算法对数组中的每个元素仅存储和读取一次,而求逆算法需要两次。在实际的计算机上实验以比较两者的速度差异,特别注意内存引用位置附近的问题。
-
0x07:向量旋转算法将向量 ab 变为 ba。如何将向量 abc 变为 cba?(这对交换非相邻内存块的问题进行了建模)
-
0x08:20世纪70年代末期,贝尔实验室开发出了『用户操作的电话号码簿辅助程序』,该程序允许雇员使用标准的按键电话在公司电话号码簿中查找号码。

要查找该系统设计者的名字 Mike Lesk,可以按『LESK*M*』(也就是『5375*6*』),随后,系统会输出他的电话号码。这样的服务现在随处可见。该系统中出现的一个问题是,不同的名字有可能具有相同的按键编码。在 Lesk 的系统中发生这种情况时,系统会询问用户更多的信息。给定一个大的名字文件时(例如标准的大城市电话号码簿),如何定位这些『错误匹配』呢?(当 LESK 在这种规模的电话号码簿上做实验时,他发现错误匹配的概率仅仅是0.2%)如何实现一个以名字的按键编码为参数,并返回所有可能的匹配名字的函数?
-
0x09:在20世纪60年代早期,Vic Vyssotsky 与一个程序员一起工作,该程序员需要转置一个存储在磁带上的4000*4000的矩阵(每条记录的格式相同,为数十个字节)。他的同事最初提出的程序需要运行50个小时。Vyssotsky 如何将运行时间减少到半小时呢?
-
0x10:给定一个 n 元实数集合、一个实数 t 和一个整数 k,如何快速确定是否存在一个 k 元子集,其元素之和不超过 k ?
-
0x11:顺序搜索和二分搜索代表了搜索时间和预处理时间之间的折中。处理一个 n 元表格时,需要执行多少次二分搜索才能弥补对表进行排序所消耗的预处理时间?
方案集合
0x00
该问题的解思想在于: 二分法 。
首先,将40亿个数字遍历一遍,分为 2 组,第一位为 1 的一组,为 0 的一组(假设只缺少一个数字),则数量少的一组必定有缺少的数,然后对该组再次进行分组,如此进行下去直到找到该缺少的数字。
如果有足够的空间使用第一章中介绍的位向量也是可以的。
0x01
解法1:思想在于向量中的元素移动后的最终位置其实是确定的,我们需要的是一个临时变量,存放着该元素移动后的位置,然后把对应的元素放到相应位置即可
解法2:思想在于旋转向量的问题其实就是将该向量分为了两部分 ab,然后变成 ba 的过程。其中 a 为向量的前 i 个元素,将 ab 变为 ba 过程是这样的:首先对 a 求逆得到 a’,然后对 b 求逆得到 b’,最后对 (a’b’) 求逆,所得到的结果就是 ba,过程如下:
reverse(0, i-1); /* cbadefgh */ reverse(i, n-1); /* cbahgfed */ reverse(0, n-1); /* defghabc */
0x02
对于该问题,我们可以标识字典中的每一个词,使用基于排序的标识,按照字母表的顺序来对出现的字母进行排序,例如,”deposit” 的标识为 “deiopst”。改进后的标识,我们可以使用类似 “e1h1l1o2” 来标识 “hello”。
0x03
如果仅给单词和词典,我们需要对字典中的单词进行依次算标识,然后进行比较;
如果有一些时间和空间可以预先处理字典,我们可以先计算出每个单词的标识然后建立 (标识, 单词) 对然后方便查找(或者直接排序)
0x04
思路同 0x00,先扫描一遍,把第一位是 「0」和「1」的数字放到两个文件中,数量多的一个对第二位数字再分组,以此类推,最后一定能找出一个数字。
0x05
第一个算法的实现(杂耍算法)
/* 求最大公约数 */
int gcd(int a, int b){
return b==0?a:gcd(b, a%b);
}
/* 第一个算法 */
int a1(int *start, int *end, int i){
int len = end - start;
int g = gcd(len, i);
for(int index = 0; index < g; index++){
int t = *(start+index);
int next = index;
while((next+i)%len != index){
*(start+next) = *(start+(next+i)%len);
next = (next+i)%len;
}
*(start+next) = t;
}
return 0;
}
第二个算法的实现(交换算法)
/* 第二个算法 */
void rangeswap( int *a, int i, int j, int m){
//交换 a[i...i+m] 和 a[j...j+m]
for(int index = 0; index < m; index++){
int temp = a[i + index];
a[i + index] = a[j + index];
a[j + index] = temp;
}
}
void a2( int *a, int shift ){
if(shift == 0 || shift == num)
return;
int n = shift;
int j = num - shift;
int i = shift;
while(i != j ){
if(i > j){
rangeswap(a, n-i, n, j);
i -= j;
}
else{
rangeswap(a, n-i, n+j-i, i);
j -= i;
}
}
rangeswap(a, n-i, n, i);
}
第三个算法的实现(求逆算法)
/* 第三个算法 */
void reverse(int m, int n){
int mid = (m+n)/2;
int temp;
for(int i = m, j=n; i <= mid; i++, j--){
temp = a[i];
a[i] = a[j];
a[j] = temp;
}
}
void a3(int* a, int i){
reverse(0, i-1);
reverse(i, num-1);
reverse(0, num-1);
}
0x06
把上述三种算法分别运行,向量长度为1,000,000,旋转长度为 1 - 50,作图如下:(横坐标为旋转长度,纵坐标为运行时间,单位为毫秒)
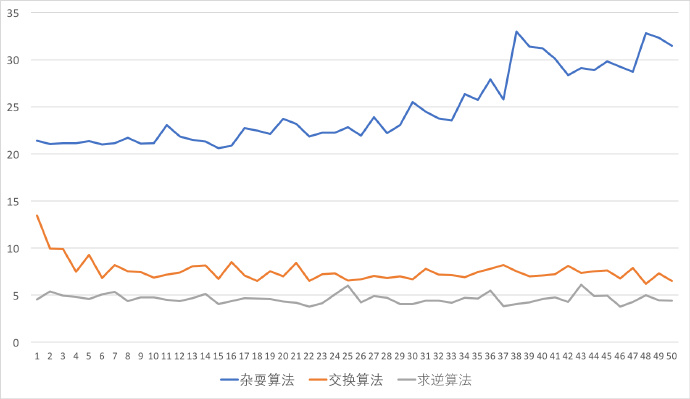
测试代码如下:
int main(int argc, const char * argv[]) {
ofstream oFile;
oFile.open("/Users/jason/data.csv", ios::out | ios::trunc);
for(int i = 1; i <= 50; i++){
oFile << i << ',';
}
oFile << endl;
/*算法一运行时间统计(向量长度1000000,旋转距离1-50)*/
for(int i = 1; i <=50; i++){
init();
clock_t start, finish;
double totaltime;
start = clock();
a1(a, a+num, i);
finish = clock();
totaltime = (double)(finish-start)/CLOCKS_PER_SEC;
oFile << totaltime*1000 << ',';
}
oFile << endl;
/*算法二运行时间统计(向量长度1000000,旋转距离1-50)*/
for(int i = 1; i <= 50; i++){
init();
clock_t start, finish;
double totaltime;
start = clock();
a2(a, i);
finish = clock();
totaltime = (double)(finish-start)/CLOCKS_PER_SEC;
oFile << totaltime*1000 << ',';
}
oFile << endl;
/*算法三运行时间统计(向量长度1000000,旋转距离1-50)*/
for(int i = 1; i <= 50; i++){
init();
clock_t start, finish;
double totaltime;
start = clock();
a3(a, i);
finish = clock();
totaltime = (double)(finish-start)/CLOCKS_PER_SEC;
oFile << totaltime*1000 << ',';
}
oFile << endl;
oFile.close();
return 0;
}
0x07
分别对 a, b, c 求逆,得到 a’, b’, c’,再对 (a’b’c’) 求逆,得到 cba
0x08
首先计算出所有名字的标识,例(『LESK*M*』的标识是『5375*6*』),然后对所有标识进行排序,查找时使用二分搜索2(答案中说实际中往往使用散列表或数据库系统)
0x09
(作者给的答案)
为了转置矩阵,Vyssotsky 为每条记录插入列号和行号,然后调用系统的磁带排序程序先按列排序,再按行排序,最后使用另一个程序删除列号和行号
0x10
我能想到的方法是:对这个集合进行排序,然后算出前 k 位的和与 t 进行比较
0x11
TODO
本文的版权归作者罗远航 所有,采用 Attribution-NonCommercial 3.0 License 。任何人可以进行转载、分享,但不可在未经允许的情况下用于商业用途;转载请注明出处。感谢配合!
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

