OpenSL ES 那些事
背景简介
OpenSL ES是一种针对嵌入式系统特别优化过的硬件音频加速API,无授权费并且可以跨平台使用。它提供的高性能、标准化、低延迟的特性实现为嵌入式媒体开发提供了标准,嵌入式开发者在开发本地音频应用也将变得更为简便,利用该API能够实现软/硬件音频性能的直接跨平台部署,降低了执行难度,促进高级音频市场的发展。
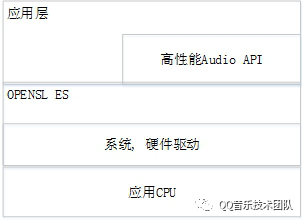
OpenSL ES的框架图
硬件实现:

软件实现:
Android应用中的音频录入会有延迟,而声音输出至扬声器之前也会耽误一些时间。在大多数基于ARM和x86的设备上,经过测量,音频RTL可能会延迟到300毫秒,大多是采用面向音频的Android方法开发的应用。用户群无法接受这种延迟范围,预期延迟必须低于100毫秒,在大多数情况下,低于20毫秒才是最理想的RTL。还需要考虑是音频处理延迟和缓冲区队列的总数。
与其他API一样,OpenSL ES的工作原理是采用回调机制。在OpenSL ES中,回调仅用于通知应用,新缓冲区可以排队(用于回放或录制)。在其他API中,回调还可以处理指向有待填充或使用的音频缓冲区的指示器。但在OpenSL ES中,更具选择,可以实施API以便回调以信令机制的形式运行,从而将所有处理维持在音频处理线程上。这样在收到分配的信号后,将包含为所需的缓冲区排队。
OpenSL ES使用流程
之前调研电视K歌期间有方案涉及到获取麦克风的音频数据,但是利用系统的AudioRecord进行数据采集有一定延时, 虽然5.0以后google针对音频做了一定的优化,延迟稍微改善,但是效果还是差强人意。所以为了更好的返听效果,OpenSL ES是最合适的,主要原因是以下三点。
-
OpenSL ES使用的缓冲区队列机制,使其在Android媒体框架中更加高效。
-
如果手机支持低延迟特性那么就需要要使用OpenSL ES了(google原文:Low-latency audio is only supported when using Android’s implementation of the OpenSL ES? API and the Android NDK.)
-
由于该实施为原生代码,所以它可以提供更高的性能,因为原生代码不会受制于Java或Dalvik VM开销
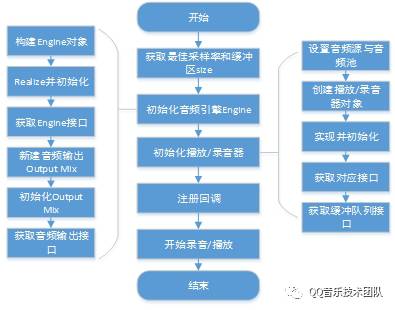
因此这种方法有助于基于Android的音频开发。以下是OpenSL ES的初始化流程图。
在OpenSL ES中所有的操作都是通过接口来完成,和java的接口类似,接口提供底层的方法调用。常用的接口有以下几种:
-
SLObjectItf :对象接口
-
SLEngineItf :引擎接口
-
SLPlayItf:播放接口
-
SLBufferQueueItf :缓冲队列接口
-
SLVolumeItf : 声量接口
以下分为四个部分:初始化,音频数据采集,音频数据传输,音频数据播放。
初始化
初始化主要包括,OpenSL ES引擎初始化,录音/播放器初始化。
OpenSL ES引擎初始化
OpenSL ES引擎初始化主要的点在于新建引擎对象连接JNI与底层交互,设置引擎的采样参数,包括采样平率,采样帧大小,采样声道以及采样深度,并且初始化音频数据的缓冲区队列。需要注意的是本次实验中使用的发送端与服务端的采样参数需要设置相同。
SLresult result;
memset(&engine, 0, sizeof(engine));
//设置采样参数
engine.fastPathSampleRate_ = static_cast<SLmilliHertz>(sampleRate) * 1000;
engine.fastPathFramesPerBuf_ = static_cast<uint32_t>(framesPerBuf);
engine.sampleChannels_ = AUDIO_SAMPLE_CHANNELS;
engine.bitsPerSample_ = SL_PCMSAMPLEFORMAT_FIXED_16;
//新建对象
result = slCreateEngine(&engine.slEngineObj_, 0, NULL, 0, NULL, NULL);
SLASSERT(result);
//初始化
result = (*engine.slEngineObj_)->Realize(engine.slEngineObj_, SL_BOOLEAN_FALSE);
SLASSERT(result);
//获取引擎接口,这样可以利用引擎构建其他对象
result = (*engine.slEngineObj_)->GetInterface(engine.slEngineObj_, SL_IID_ENGINE, &engine.slEngineItf_);
SLASSERT(result);
// 计算推荐的最快的音频缓冲区大小
// 低延迟需要以下两点
// 缓冲区尽量小 (adjust it here) AND
// 接收录音器的缓冲数据后 并且在播放之前 尽量减少数据缓冲时间
// 调整缓冲区大小以适应你的要求[before it busts]
bufSize = engine.fastPathFramesPerBuf_ * engine.sampleChannels_
* engine.bitsPerSample_;
bufSize = (bufSize + 7) >> 3; // bits --> byte
engine.bufCount_ = BUF_COUNT;
engine.bufs_ = allocateSampleBufs(engine.bufCount_, bufSize);
assert(engine.bufs_);
//空闲的缓冲区以及接收缓冲区
engine.freeBufQueue_ = new AudioQueue (engine.bufCount_);
engine.recBufQueue_ = new AudioQueue (engine.bufCount_);
assert(engine.freeBufQueue_ && engine.recBufQueue_);
for(uint32_t i=0; i<engine.bufCount_; i++) {
engine.freeBufQueue_->push(&engine.bufs_[i]);
}
其中新建了引擎对象slEngineObj之后是不可使用的,需要Realize之后才能通过该对象获取到引擎接口,引擎接口可以用来获取后续要用到的播放,录音接口。fastPathFramesPerBuf是每一个buffer缓冲区的采样点数,而整个bufsize的大小是所有声道采样点数的两倍,因为采样深度是16bit,也就是2个字节。freeBufQueue是指空闲的buffer队列,主要是提供空的采样数组。recBufQueue是接收缓冲队列,主要是用来存储已采集到的音频数据,同样也是播放数据的来源。引擎初始化完毕之后会初始化freeBufQueue,初始化了16个空的大小为480字节的数组。至此音频引擎的初始化结束。
OpenSL ES Recorder初始化
录音器的初始化主要是设置声源,设置采集数据格式,获取采样缓冲队列与配置接口等,代码如下:
sampleInfo_ = *sampleFormat;
SLAndroidDataFormat_PCM_EX format_pcm;
ConvertToSLSampleFormat(&format_pcm, &sampleInfo_);
//设置声源
SLDataLocator_IODevice loc_dev = {SL_DATALOCATOR_IODEVICE,SL_IODEVICE_AUDIOINPUT,
SL_DEFAULTDEVICEID_AUDIOINPUT,NULL };
SLDataSource audioSrc = {&loc_dev, NULL };
//设置音频数据池
SLDataLocator_AndroidSimpleBufferQueue loc_bq = {
SL_DATALOCATOR_ANDROIDSIMPLEBUFFERQUEUE,
DEVICE_SHADOW_BUFFER_QUEUE_LEN };
SLDataSink audioSnk = {&loc_bq, &format_pcm};
//创建Recorder需要 RECORD_AUDIO 权限
const SLInterfaceID id[2] = {SL_IID_ANDROIDSIMPLEBUFFERQUEUE,
SL_IID_ANDROIDCONFIGURATION };
const SLboolean req[2] = {SL_BOOLEAN_TRUE, SL_BOOLEAN_TRUE};
result = (*slEngine)->CreateAudioRecorder(slEngine,&recObjectItf_,&audioSrc,
&audioSnk,sizeof(id)/sizeof(id[0]),id, req);
//配置语音识别的预设值
SLAndroidConfigurationItf inputConfig;
result = (*recObjectItf_)->GetInterface(recObjectItf_,SL_IID_ANDROIDCONFIGURATION,&inputConfig);
if (SL_RESULT_SUCCESS == result) {
SLuint32 presetValue = SL_ANDROID_RECORDING_PRESET_VOICE_RECOGNITION;
(*inputConfig)->SetConfiguration(inputConfig,SL_ANDROID_KEY_RECORDING_PRESET,
&presetValue,sizeof(SLuint32));
}
//实现录音对象
result = (*recObjectItf_)->Realize(recObjectItf_, SL_BOOLEAN_FALSE);
//获取录音接口
result = (*recObjectItf_)->GetInterface(recObjectItf_,
SL_IID_RECORD, &recItf_);
//获取录音队列接口
result = (*recObjectItf_)->GetInterface(recObjectItf_,
SL_IID_ANDROIDSIMPLEBUFFERQUEUE, &recBufQueueItf_);
//注册录音队列回调
result = (*recBufQueueItf_)->RegisterCallback(recBufQueueItf_,
bqRecorderCallback, this);
//初始化音频采集中转队列
devShadowQueue_ = new AudioQueue(DEVICE_SHADOW_BUFFER_QUEUE_LEN);
首先是定义了声源数据SLDataSource,它包含两个成员,DataLocator数据定位器以及数据格式,数据格式一般采用较为常见的PCM数据,数据定位器一般是指声音采集之后的存储位置,分为四种midi缓冲区队列位置,缓冲区队列位置,输入/输出设备位置,和内存位置。本次验证我们使用PCM数据,并且为了能更高效的操作采集数据,采用缓冲区队列的存储位置。
紧接着就是音频数据池的初始化,音频数据池指的是数据输出,主要设置Recorder需要将音频数据的输出位置以及输出格式。
在初始化完录音对象recObjectItf,获取到录音接口recItf,后续开始录音需要用到该接口。recBufQueueItf 是录音队列的接口,通过该接口来注册缓冲队列的回调接口。
OpenSL ES Player初始化
Player的初始化与Recorder类似,主要是设置声源,设置采集数据格式,获取采样缓冲队列与配置接口等,代码如下:
sampleInfo_ = *sampleFormat;
//初始化OutputMix,用来输出声音数据
result = (*slEngine)->CreateOutputMix(slEngine, &outputMixObjectItf_,
0, NULL, NULL);
//实现OutputMix
result = (*outputMixObjectItf_)->Realize(outputMixObjectItf_, SL_BOOLEAN_FALSE);
//配置声源数据
SLDataLocator_AndroidSimpleBufferQueue loc_bufq = {
SL_DATALOCATOR_ANDROIDSIMPLEBUFFERQUEUE,
DEVICE_SHADOW_BUFFER_QUEUE_LEN };
SLAndroidDataFormat_PCM_EX format_pcm;
ConvertToSLSampleFormat(&format_pcm, &sampleInfo_);
SLDataSource audioSrc = {&loc_bufq, &format_pcm};
//配置音频数据输出池
SLDataLocator_OutputMix loc_outmix = {SL_DATALOCATOR_OUTPUTMIX, outputMixObjectItf_};
SLDataSink audioSnk = {&loc_outmix, NULL};
/* 初始化Player */
SLInterfaceID ids[2] = { SL_IID_BUFFERQUEUE, SL_IID_VOLUME};
SLboolean req[2] = {SL_BOOLEAN_TRUE, SL_BOOLEAN_TRUE};
result = (*slEngine)->CreateAudioPlayer(slEngine, &playerObjectItf_, &audioSrc, &audioSnk,sizeof(ids)/sizeof(ids[0]), ids, req);
//实现player
result = (*playerObjectItf_)->Realize(playerObjectItf_, SL_BOOLEAN_FALSE);
SLASSERT(result);
//获取Player接口
result = (*playerObjectItf_)->GetInterface(playerObjectItf_, SL_IID_PLAY, &playItf_);
//获取音量接口
result = (*playerObjectItf_)->GetInterface(playerObjectItf_, SL_IID_VOLUME, &volumeItf_);
//获取缓冲队列接口
result=(*playerObjectItf_)->GetInterface(playerObjectItf_,SL_IID_BUFFERQUEUE,&playBufferQueueItf_);
//注册缓冲接口回调
result=(*playBufferQueueItf_)->RegisterCallback(playBufferQueueItf_, bqPlayerCallback, this);
相比较Recorder的初始化,其中多了一个OutputMix的初始化,OutputMix主要是用来将数据输出到扬声器中,因此可以认为称是输出混频对象接口的初始化。
最终获取到的playBufferQueueItf是播放缓冲队列的接口,可以认为该队列与Recorder中的recBufQueueItf 的数据来源是一致的,其实就是采集数据缓冲队列中的数据通过Socket传到playBufferQueueItf供Player来实现播放。
音频数据采集
音频数据采集主要过程是初始化缓冲队列,录音的启动设置,最后是开始录音,流程图如下:
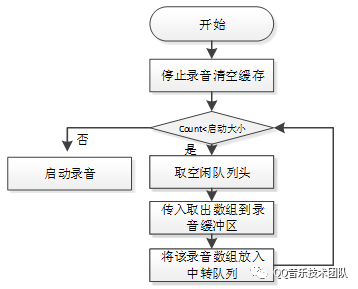
启动大小设置的是2,在启动录音之前先将2个录音数组放入录音内存空间,开始之后录音数据会采集到这两个数组中,当录音数组填满之后会触发上文Recorder中设置的回调,在回调中取出已经录好的声音数据,并且通过Socket发送出去。
sample_buf *dataBuf = NULL;//采集到的音频数据数组
devShadowQueue_->front(&dataBuf);//取出已采集的数组
devShadowQueue_->pop();//删掉头部
dataBuf->size_ = dataBuf->cap_;//只在数组满了之后回调,所以size可以设置为最大长度
sendUdpMessage(dataBuf);//利用UDP发送
sample_buf* freeBuf;
while (freeQueue_->front(&freeBuf) && devShadowQueue_->push(freeBuf)) {
freeQueue_->pop();//删掉已使用的空闲数组
SLresult result = (*bq)->Enqueue(bq, freeBuf->buf_, freeBuf->cap_);//继续下一次采集
sample_buf *vienBuf = allocateOneSampleBufs(getBufSize());
freeQueue_->push(vienBuf);//添加新的空闲数组
}
以上就是回调中的代码,首先devShadowQueue取出已采集的音频数据,将其发送出去,并且继续下一次采集,这里使用while循环是为了将尽可能多的数组放入采集缓冲区中,保证提供空闲数组(用来存储麦克风采集的数据)的连续性。
音频数据传输
这里的传输分为发送与接收,其中发送相对简单,因为此时网络已经建立连接,直接调用发送就好。
void sendUdpMessage(sample_buf *dataBuf){
sendto(client_socket_fd, dataBuf->buf_, dataBuf->size_, 0,
(struct sockaddr *) &server_addr, sizeof(server_addr));
}
接收部分主要是将接收到的数据放入播放缓冲区,最好在开始播放之前预存一定的声音数据到播放缓冲区,避免播放时候拿不到的数据情况。
sample_buf *vien_buf = sampleBufs(BUF_SIZE);
if( recvfrom( server_socket_fd, vien_buf->buf_, BUF_SIZE, 0, (struct sockaddr*) &client_addr, &client_addr_length) == -1){
exit(1);
}
if (getAudioPlayer() != NULL) {
getRecBufQueue()->push(vien_buf);
if (count_buf++ == 3) {
getAudioPlayer()->PlayAudioBuffers(PLAY_KICKSTART_BUFFER_COUNT);
}
}
其中getRecBufQueue获取到的是播放缓冲区的队列,在存入三个数组之后通知Player开始可以播放了。
音频数据播放
在接受完需要的缓冲数据之后开始启动播放,这里调用的PlayAudioBuffers方法就是开启播放的方法。
sample_buf *buf = NULL;
if(!playQueue_->front(&buf)) {
uint32_t totalBufCount;
callback_(ctx_, ENGINE_SERVICE_MSG_RETRIEVE_DUMP_BUFS,
&totalBufCount);
break;
}
if(!devShadowQueue_->push(buf)) {
break; // PlayerBufferQueue满了!!
}
(*playBufferQueueItf_)->Enqueue(playBufferQueueItf_,buf->buf_, buf->size_);
playQueue_->pop(); //删除已经播放的数组
playQueue是播放队列,如果为空的话表示没有缓冲数据,这里回调到用的地方做错误处理,若是成功取出,那么先将其存入中转队列,并且将其传入调用播放的方法中开启播放,最后在播放队列中删除该已经播放的数组,在播放完成之后会进入Player播放队列注册的回调中。
sample_buf *buf;
if(!devShadowQueue_->front(&buf)) {
if(callback_) {
uint32_t count;
callback_(ctx_, ENGINE_SERVICE_MSG_RETRIEVE_DUMP_BUFS, &count);
}
return;
}
devShadowQueue_->pop();
buf->size_ = 0;
if(playQueue_->front(&buf) && devShadowQueue_->push(buf)) {
(*bq)->Enqueue(bq, buf->buf_, buf->size_);
playQueue_->pop();
} else{
sample_buf *buf_temp = new sample_buf;
buf_temp->buf_ = new uint8_t [BUF_SIZE];
buf_temp->size_ = BUF_SIZE;
buf_temp->cap_ = BUF_SIZE;
(*bq)->Enqueue(bq, buf_temp->buf_ , BUF_SIZE);
devShadowQueue_->push(buf_temp);
}
回调中首先是拿出中转队列devShadowQueue中的已播放数据,若是有则正常删除,并且从播放队列playQueue中继续取出播放数组,同时放入中转队列devShadowQueue中,devShadowQueue作用有两个,一个是确保播放的连续性,还有是播放数据的临时存放点。若是当前网络延迟接收不到播放数据的时候,就会出现播放队列取不出数据的情况,这里目前是传入空的数组,体验上会发现是声音有一定时间的卡顿,这里的逻辑后续还要继续优化,如何有效控制声音卡顿也将会大大改善用户体验。
本次分享主要是将JNI层的声音采集,传输以及播放过程做相应介绍,若是大家有更好的优化建议,欢迎指教。
正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

