事务隔离(一):ANSI SQL事务隔离级别,限制及扩展
一般的数据库教科书上都会介绍,事务有ACID四个特性,分别是atomicity, consistency, isolation和duriablity。本文主要讨论是事务的isolation特性,即隔离性。
谈到事务的隔离性,一般是指ANSI SQL标准下的四种隔离级别,即Read Uncommitted, Read Committed, Repeatable Read和Serialibility。但ANSI SQL的事务隔离级别的标准存在以下限制:
- 没有提及写操作的隔离性
- ANSI SQL的标准比较老,对于采用多版本并发控制实现隔离性的级别不能够很好的描述
本文主要在分析ANSI SQL标准下的事务隔离级别之后,讨论其限制,以及扩展,全文的组织架构如下:
- ANSI SQL标准下的事务隔离级别
- ANSI SQL标准的限制及其扩展
本文收录在 papers项目 ,papers项目旨在学习和总结分布式系统相关的论文。
ANSI SQL标准下的事务隔离级别
在数据库中,多个事务往往是并发执行的,事务之间可能会存在干扰,从而导致数据不正确的问题。为了保证事务之间执行不互相干扰,最简单的方案则是串行的执行一个个事务,但这会降低吞吐量。为此,ANSI SQL标准引入事务隔离级别,描述了并发事务的各种干扰级别,使得应用程序可以在吞吐量和正确性上做决策,不同的事务隔离级别保证不同程度的正确性,一般而言,事务隔离级别越低,吞吐量越高,正确性越低。
ANSI SQL的隔离级别主要是从解决应用程序出现的各种干扰现象中,而设计出来的,其隔离级别主要是为了解决以下三种现象:
- 脏读 (P1)
- 不可重复读 (P2)
- 幻读 (P3)
首先,来看脏读P1的发生的时序:
事务T1写了数据X,事务T2读了数据X,事务T1回滚,此时,事务T2读取到的是脏数据
其次,来看不可重复读P2发生的时序:
事务T1读了数据X,事务T2写了数据X,事务T2提交,事务T1再次读数据X,两次读到的数据X不一样
最后,来看幻读P3发生的时序
事务T1读了满足X>=m且X<=n的数据,事务T2插入一条数据,满足条件X>=m且x<=n,事务T2提交,事务T1再次读满足X>=m且X<=n的数据,两次读到的数据不一样
用稍微形式化的语言描述上述现象发生的时序,假设W1(X)表示事务T1修改了数据项X,而R2(X),表示事务T2读了数据项X;W1(P)表示事务T1修改了满足谓词条件P的数据项,而R2(P),表示事务T2读了满足谓词条件P的数据项。C1表示事务T1提交,A1表示事务T1回滚。
脏读P1
W1(X)…R2(X)…A1…R2(X)
不可重复读P2
R1(X)…W2(X)…C2…R1(X)
幻读P3
R1(P)…W2(P)…C2…R1(P)
针对三种现象,ANSI SQL标准设定了四种事务隔离级别,如下:
- Read Uncommitted:有可能发生P1,P2和P3
- Read Committed:不可能发生P1,有可能发生P2和P3
- Repeatable Read:不可能发生P1,P2,有可能发生P3
- Serializable:不可能发生P1,P2和P3
整个事务个隔离级别,与杜绝的现象的对应关系如下图:
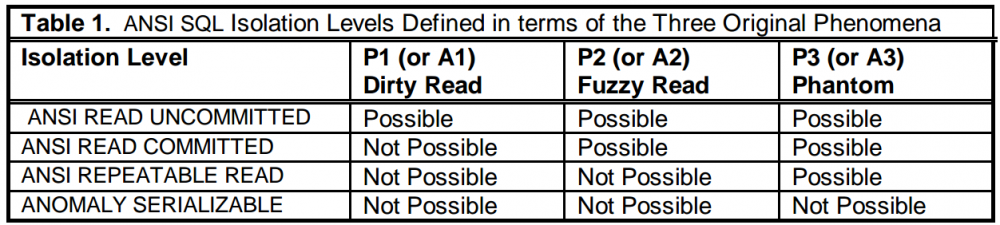
值得一提的是,在Serializable下,不可能发生P1,P2和P3,但并不表明,不发生P1,P2和P3就一定是在Serializable。真正的在Serializable是指事务并发执行下得到的结果,与各个事务串行执行下的某个结果相同。
ANSI SQL标准的限制及其扩展
如上文提到,ANSI SQL有如下限制:
- 没有提及写操作的隔离性
- ANSI SQL的标准比较老,对于采用多版本并发控制实现隔离性的级别不能够很好的描述
对于第一点,没有提及写操作的隔离性,有如下现象
脏写P0
事务T1修改X,事务T2修改X,事务T1回滚,此时不知回滚到什么值
举个例子说明,假设事务T1修改X前,X=100,事务T1要把修改成10,事务T2要把X修改成20,如下:
X=100 W1X(10) W2X(20) A1
事务T1回滚时,如果选择回滚到X=20,那么如果事务T2再回滚时,无法回滚到最原先的100;如果回滚到X=100,那么事务T2提交时,就无法知道写入的是X=20,在这种场景下,是无解的。
因此,对于写一定是要隔离的,否则,无法保证事务的正确性。所以,对于所有的ANSI SQL标准下的隔离级别,需要增强到都满足P0不发生的级别。
对于写操作,还存在写丢失问题,发生在如下场景
写丢失P4
事务T1读数据X,事务T2读数据X,事务T2修改数据X,事务T1修改数据X,最终写入的数据是脏数据
举个例子,假如原先X=100,事务T1对X加5,事务T2对X减1,预期的结果应该是100+5-1=104,而如果在写丢失的情况下,则如下
T1 T2
R(X=100)
R(X=100)
W(X=99)
W(X=104)
如上场景,最终写入到数据库时,X=104,这属于数据不一致,是应该杜绝的。
写丢失在现象在ANSI SQL的Read Committed级别可能发生,但是Repeatable Read级别不可能发生。为此,引入Cursor Stability隔离级别,保证不会发生P4。但是,P4不会在Repeatable级别发生,因为P2禁止了事务T1读X后,事务T2写X的场景。因此,Cursor Stability的隔离级别处于Read Committed和Repeatable Read之间。
现有的工业界产品,如MySQL等,大多都会采用MVCC等多版本并发控制来达到某种隔离性,而在ANSI SQL标准中,是没有考虑多版本的,因此,有必要讨论多版本并发控制下的隔离级别与现有的ANSI SQL标准下的隔离级别的不同。
先简单的介绍下一种多版本并发控制的思路,即Basic Time Ordering,其流程如下:
- 事务T1开始时,先申请一个时间戳,记做Start-Timestamp
- 事务T1的读不会阻塞,因为,它会读其Start-Timestamp之前的版本,其他事务在Start-Timestamp之后的修改,对该事务是不可见的
- 事务T1本身的修改,包括更新,插入和删除,都会保存在事务的上下文中,方便事务本身重复读取修改过的数据
- 当事务T1要提交时,它会获取一个Commit-Timestamp,此Commit-Timestamp要保证比现有的所有其他事务的Start-Timestmap和Commit-Timestmap要大,如果存在其他事务Commit-Timestamp在事务T1的[Start-Timestamp, Commit-Timestamp]之内,且该事务修改了事务T1修改的数据,那么,事务T1会被终止,否则,事务提交
可以看出,步骤4中保证了P4写丢失现象不会在Basic Time Ordering中发生,把Basic Time Ordering达到的隔离级别称为Snapshot级别。由于会读取Start-TimeStamp之前提交的记录,因此,Snapshot肯定是满足Read Committed。
接下来,要讨论的是Snapshot和Repeatable Read之间的关系:
Snapshot读取的是某个时间点前的快照,因此,也不会出现不可重复读的现象,所以,从这个角度来说Snapshot的隔离级别要大于Repeatable Read,但考虑以下场景:
R1(X)…R2(Y)…W1(Y)…W2(X)…C1…C2
这种场景在Repeatable Read级别是被禁止的,因为T2读了数据Y之后,T1修改Y并提交了,会导致不可重复读。而对于Snapshot是可能发生这种场景的,以X+Y要满足条件大于0为例,说明Snapshot下可能违反此约束,如下
两个事务开始之前X=1,Y=2,时间戳为10000 事务T1开始,申请时间戳为10001,R1(X)=1 事务T2开始,申请时间戳为10003,R2(Y)=2 事务T1,W1(Y)=0 事务T2,W2(X)=0 事务T1提交,发现X+Y=1+0,满足约束 事务T2提交,发现X+Y=0+2,满足约束
虽然事务T1和事务T2都认为满足约束,但是两个事务都执行完成后,约束不满足。
因此,在这个现象上,Snapshot的隔离级别要小于Repeatable Read。故,Snapshot的隔离级别既不大于Repeatable Read,也不小于Repeatable Read。
总结
事务隔离级别是比较有意思的话题,现阶段也有一些技术来实现各种隔离级别,接下来的一些文章会讨论实现事务隔离级别的技术,以及工业界产品中使用的技术,如下:
- Two Phase Locking
- Basic Time Ordering
- Multi-version Concurrentcy Control
- Optimistic Concurrency Control
- MySQL,Oracle,Spanner等产品是使用何种技术来做事务隔离的
PS:
本博客更新会在第一时间推送到微信公众号,欢迎大家关注。

正文到此结束
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

