python利用beautifulsoup+selenium自动翻页抓取网页内容
一、背景
记录一次周末在家速成的爬虫实现之旅。受人之托,想要把这个页面 http://baike.baidu.com/starrank?fr=lemmaxianhua 的明星排行榜爬取下来。用chrome打开一看,其实就1000条记录。然后“右键菜单”->“检查”,看下网页的结构,也不是特别复杂。所以我目测只要用 python 自带的 urllib2 库打开网页,获取html代码,再交给 BeautifulSoup 库解析html代码,应该就可以快速搞定。
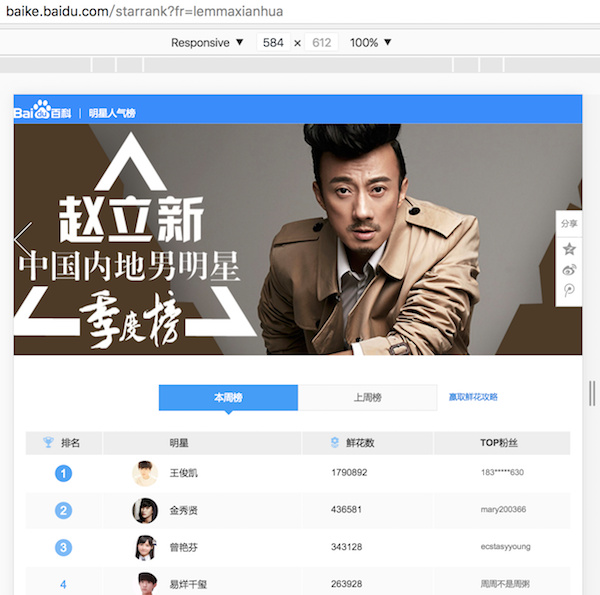
但仔细一看, 点击下一页,网页的url没有任何变化 ,只是用js去加载了新的数据,然后动态地改变了table里面的数据。这可和本菜菜以前爬的页面可不一样,所以这次要想办法 模拟翻页,然后重新读取新的html代码,再去解析 。
实现翻页可以有两种办法, 第一种是分析js的实现来模拟翻页。 翻页操作实际上js向后台发出了请求,这里肯定是带着跳转的目的页码请求了后台,然后拿到新数据后重新渲染了html的表格部分。这种方法会更加高效,但难度也会更大一些。因为如果你已经能够模拟请求了,那其实相当于你连人家的服务器接口都已经知道了,那么进一步分析下响应就可以拿到结果了,这甚至不需要再去分析html代码了是不是? 第二种比较简单暴力,也是我这里用的方法,那就是模拟点击网页中的下一页按钮,然后重新读取html代码来解析。
二、思路
在前面已经说了,这里把思路流程化:
- 1.打开网页
- 2.读取当前页面的html代码,解析列表里面的明星名字
- 3. 模拟 点击“下一页”
- 4.重复第2步的工作,直到页面里没有“下一页”的按钮
在这里打开网页和读取网页的html代码,是通过 selenium 实现的; 解析html代码,是通过 beautifulsoup 实现的。
三、实现
1.准备工作,安装依赖库
- 安装beautifulsoup
在下用的是mac,所以直接easy_install命令行安装。
sudo easy_install beautifulsoup4 easy_install lxml easy_install html5lib
- 安装selenium
还是用easy_install命令装。
sudo easy_install selenium
这里selenium版本已经到了3.0.2,想要用这个版本的selenium去打开一个网页,需要用到对应的driver。于是下面我还需要安装一个driver。
- 安装chromedirver
我这里用的是homebrew安装的chromediver,安装完成后 大家记得找到chromediver的安装目录 ,我们在下面去写代码的时候会用到的。
brew install chromedirver
注意:mac下有很多软件管理包,除了我的安装方法,用 pip 之类的去安装,或者直接去官网下载安装程序,都是可以的。但是一定要安装上面的3个程序才行。这里我突然有个想法,要是python也有像gradle一样的构建管理工具多好,讲真,今天我安装这几个依赖的library花的时间比写代码还多呢。。
2.分析网页
简单贴一段我要爬的网页的部分html代码,里面我用//写了点注释:
<div class="tables-container" style="height: 1417px">
// 本周排行榜,这是我要抓的内容
<div class="ranking-table cur" data-cat="thisWeek">
<table>
<thead>
<tr>
<th style="padding-left: 30px; width: 101px"><img src="http://baike.bdimg.com/static/wiki-activity/starRanking/resource/img/trophy-blue_05c0f47.png"> 排名</th>
<th style="padding-left: 115px; width: 226px">明星</th>
<th style="padding-left: 50px; width: 175px"><img src="http://baike.bdimg.com/static/wiki-activity/starRanking/resource/img/flower-blue_31b8b3b.png"> 鲜花数</th>
<th style="padding-left: 80px; width: 154px">TOP粉丝</th>
</tr>
</thead>
<tbody class="list-container">
<tr>
<td class="star-index star-index-0"><i>1</i></td>
// 这个td标签,star-name的css class是我要抓的内容
<td class="star-name"><a href="/subview/3938672/10939278.htm" target="_blank"><img src="https://imgsa.baidu.com/baike/whcrop%3D100%2C100/sign=b5ae35ac11d8bc3ec65d5088edfb9b2f/8d5494eef01f3a29f4da55589125bc315c607c12.jpg">王俊凯</a></td>
<td class="star-score">
<span>1790892</span>
<a href="javascript:;" class="star-score-sendFlower" data-lemmaid="75850">送花<i></i></a>
</td>
<td class="star-fans">
<p><i>1</i>183*****630</p>
<p><i>2</i>185*****759</p>
<p><i>3</i>wx526298988</p>
</td>
</tr>
...此处省略巨量代码...
</tbody>
</table>
// 这里是本周排行榜分页的html代码,可以看到一页20个明星,共有50页
<div class="ranking-pager wgt_horPager wgt_horPager_tpl_noEllipsis" nslog="area" nslog-type="20100105">
<a href="javascript:;" class="pTag first disabled">首页</a>
<span class="separator disabled"></span>
<a href="javascript:;" class="pTag prev disabled"><em><</em>上一页</a>
<span class="separator disabled"></span>
<a href="javascript:;" class="pTag cur">1</a>
<a href="javascript:;" class="pTag" p-index="2">2</a>
<a href="javascript:;" class="pTag" p-index="3">3</a>
<a href="javascript:;" class="pTag" p-index="4">4</a>
<a href="javascript:;" class="pTag" p-index="5">5</a>
<span class="separator"></span>
// 这里就是要模拟点击的下一页按钮
<a href="javascript:;" class="pTag next" p-index="2">下一页<em>></em></a>
<span class="separator"></span>
<a href="javascript:;" class="pTag last" p-index="50">尾页</a></div>
</div>
// 下面开始就是“上周排行榜”,html结构和上面完全类似
<div class="ranking-table" data-cat="lastWeek">
<table>
</table>
...此处再次省略巨量代码...
3.完整代码
import sys
import urllib2
import time
from bs4 import BeautifulSoup
from selenium import webdriver
reload(sys)
sys.setdefaultencoding('utf8') # 设置编码
url = 'http://baike.baidu.com/starrank?fr=lemmaxianhua'
driver = webdriver.Chrome('/usr/local/Cellar/chromedriver/2.20/bin/chromedriver') # 创建一个driver用于打开网页,记得找到brew安装的chromedriver的位置,在创建driver的时候指定这个位置
driver.get(url) # 打开网页
name_counter = 1
page = 0;
while page < 50: # 共50页,这里是手工指定的
soup = BeautifulSoup(driver.page_source, "html.parser")
current_names = soup.select('div.ranking-table') # 选择器用ranking-table css class,可以取出包含本周、上周的两个table的div标签
for current_name_list in current_names:
# print current_name_list['data-cat']
if current_name_list['data-cat'] == 'thisWeek': # 这次我只想抓取本周,如果想抓上周,改一下这里为lastWeek即可
names = current_name_list.select('td.star-name > a') # beautifulsoup选择器语法
counter = 0;
for star_name in names:
counter = counter + 1;
print star_name.text # 明星的名字是a标签里面的文本,虽然a标签下面除了文本还有一个与文本同级别的img标签,但是.text输出的只是文本而已
name_counter = name_counter + 1;
driver.find_element_by_xpath("//a[contains(text(),'下一页')]").click() # selenium的xpath用法,找到包含“下一页”的a标签去点击
page = page + 1
time.sleep(2) # 睡2秒让网页加载完再去读它的html代码
print name_counter # 共爬取得明星的名字数量
driver.quit()
四、小结
这里只是简单记录一次稍微复杂点的网页爬取的实现思路,关于selenium和beatifulsoup,还有很多的用法,我还没仔细看过。下面是一些参考资料,以后有机会还要多学习一下。
- Python爬虫利器二之Beautiful Soup的用法
- Beautiful Soup 4.4.0 文档 :其实bs支持不同语言,这次写python就是因为代码少,但是安装依赖确实是麻烦。
- selenium官网 :selenium其实有官方的IDE,也支持不同的语言。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

