扒一扒HTTP的构成
HTTP全称为HyperText Transfer Protocol,从名字不难看出这是一种基于文本的网络协议,对于初学者来说比较友好,容易上手。各平台上的一些第三方库都对HTTP做了进一步的封装,让HTTP变得更加亲民,但往往拿来就用的技术,很容易忽视其背后隐藏的细节。今天一起来扒一扒HTTP到底是如何构成的。
初窥全貌
HTTP第一眼看上去非常简单,先来看看Request部分:

上图主要分为三部分:request line,header和body,中间的CRLF为换行符。如果能将我们平常发送的http请求对应到上述三个部分,就能形成初步的印象了。
我们以一个实际的http request例子,抓包来看一看详细的内部构造。假设我们的请求URL为:
http://www.baidu.com/res/static/thirdparty/connect.jpg?t=1480992153433
后续的分析都是以此请求为基础。
Request Line
Request Line的结构为:
Request-Line = Method SP Request-URI SP HTTP-Version CRLF
Method也就是我们平常谈论最多的POST和GET所处的部分(除了POST和GET,还有其他类型的Method)。
SP是个分隔符,我用Wireshark抓包看了下,就一个字节大小,值为0x20,对应ASCII码中的空格。
Request-URI我们就更熟悉了,上述请求对应为:/res/static/thirdparty/connect.jpg?t=1480992153.564331。这里值得注意的一点是:实际传输的时候Request-URI有两种可能的形式,一种是完整的absoluteURI,包含Schema和Host,另一种是abs_path,并没有包含Schema(http)和Host(mrpeak.cn)部分,Host部分被移交到了Header当中。所以平时我们抓包,有时看到的是完整的URI,有时则只有路径信息。
HTTP-Version也很直观,文本展示形式为:HTTP/1.1,代表我们当前使用的版本。
CRLF由两个字节组成。CR值为16进制的0x0D,对应ASCII中的回车键,LF值为0x0A,对应ASCII中的换行键,CRLF合起来就是我们平常所说的 /r/n 。
所以上述请求的Request-Line的文本展示:
GET空格 /res/static/thirdparty/connect.jpg?t=1480992153.564331 空格 HTTP/1.1 CRLF
Header
header其本质上是一些文本键值对,一个典型的例子如下图所示:
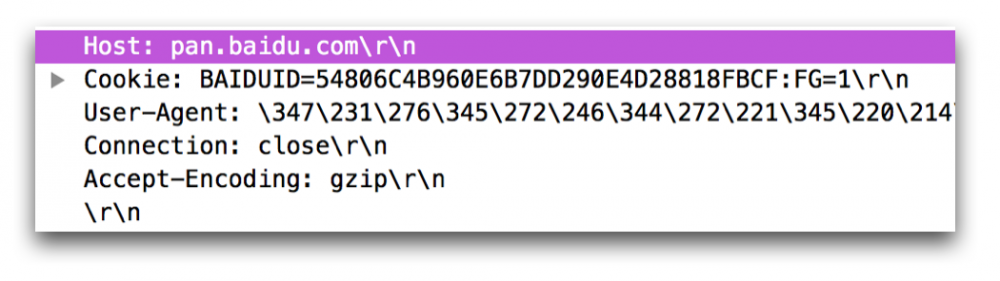
每个键值对的形式为: Key:空格 Value CRLF 。
上面讲述Request-URI的时候,缺失的Host就以键值对的形式存在于header中,比如,Host: pan.baidu.com。
将若干个上述格式的键值对组合起来,就成了我们HTTP请求的完整header。最后一个键值对之后再跟一个CRLF,就表示我们的header结束了。
HTTP本身定义了一些header key,另外也允许开发者添加自己的key,自定义的key一般以X开头,比如可以定义X-APP-VERSION来记录客户端的版本号。
Body
body里面包含请求的实际数据。
对于Method=GET的请求来说,body体是为空的,或者说不存在body体,Header最后的两个CRLF就标识着请求的结尾。我们一般调用请求的业务参数是通过Request Line当中的Request-URI来传递的,比如上述请求中的?t=1480992153.564331,也就是URI的query string部分。这部分同样是以键值对的形式存在,不过是位于Request Line当中。
对于Method=POST的请求来说,body体一般不为空,我们实际的业务数据都存放于body当中,数据在body体中是以何种形式存在,其实大有门道,后面再细说。至于Request-URI当中的query string部分,我们依然可以选择放置一部分数据在其中,但更普遍的做法是使用body体。
HTTP Response
response的结构和request结构大致相同,可以用下图表示:
不过是将Request Line换成了Status Line。
Status Line的结构如下:
Status-Line = HTTP-Version SP Status-Code SP Reason-Phrase CRLF
这里关键在于Status-Code的记忆,记住常见的Status-Code值,对于我们平时分析网络错误十分有帮助,不需要记住每个值的含义,只需理解每个类别的含义即可:
1xx: Informational - Request received, continuing process。 2xx: Success - The action was successfully received, understood, and accepted。 3xx: Redirection - Further action must be taken in order to complete the request。 4xx: Client Error - The request contains bad syntax or cannot be fulfilled。 5xx: Server Error - The server failed to fulfill an apparently valid request。
可以用来携带数据的部分
分析至此,我们可以总结一个http请求,哪些地方是可以用来携带业务数据的。
Request Line当中的Request-URI是一个选择,也是标准的GET请求用来传递数据的位置,一般以query string的格式存在于URI当中。一些浏览器或者Framework对于query string的长度会有一定的限制,所以此处不适宜于传递较大的数据。
Header也是一个选择,我们可以选择协议中的一些标准header key,比如Host,User-Agent等,将我们的业务数据存放其Value中。或者我们通过自定义key,比如上面提到的X-APP-VERSION,使用X-开头是业界默认的习惯,虽然 RFC 6648 当中建议大家不要再使用X-作为Prefix,但这一习惯今天依旧还在持续。
Body体是我们的第三个选择,POST请求可以根据Header中的Content-Type值,以不同的形式将数据保存在body体中。
一些隐藏的细节
可以看出http是一种基于文本解析的协议,上面提到的空格(0x20),换行(0x0D0A)都是HTTP用来做文本解析的辅助符号。
解析HTTP的text流程,其实也比较好理解。一个简化的流程大致是这样:当我们从TCP层拿到应用层的buffer之后,以CLRF(/r/n)为分割符,将整个buffer分成若干行,第一行自然是我们的Request Line,之后每一行代表一个Header,如果连续读到两个CLRF,则表示header结束,如果是Method=POST,读取Header中的Content-Length值,最后根据这个值读取固定长度的body体。这样就完成了我们上述三个主要部分的读取。当然,上述是个简化的流程,实际解析场景会更多一些。
我们再深入看下Request Line的解析
我们从TCP层拿到的实际上是一个字节流,要将字节流解析成我们能够阅读交流的形式,我们需要将字节码进行编码和解码。Request Line使用的编解码格式是US-ASCII,也就是我们平时接触的ASCII码中的一种。
Request Line通过ASCII码做还原之后,我们得到的是类似这样的结果:
GET /res/static/thirdparty/connect.jpg?a=1&b=2 HTTP/1.1
URI的解析也自有一套规范,我们需要特别注意的是query string部分。我们平时编写业务代码的时候,可能会在query string当中塞入自己的数据,这些数据可能是任意形式的字节流,而Request Line和URI的解析都依赖于一些特殊字符来做分割,比如空格,/,?等等,所以为了能正确,安全的解析整个Request Line和URI,我们需要对query string中的字节流做进一步的编码约束,只允许其中出现安全的ASCII码,这也是我们为什么需要UrlEncode的原因。
UrlEncode的过程也比较简单,它将字节流中的所有字节,对照ASCII码表分为,安全的ASCII码和不安全的ASCII码。安全的ASCII码不用做任何处理,不安全的ASCII码(比如空格0x20)则做进一步的编码处理,编码的思路也简单:用安全的ASCII码来代替不安全的ASCII码。比如空格(0x20)被编码成%20,由一个ASCII码(空格)变成了三个ASCII码(%,2,0)。对于原本就不是ASCII码的内容来说,比如中文,则先以UTF-8编码成字节流,再对照ASCII码做编码。比如中文字「高」,其UTF-8的表现形式为:/xE9/xAB/x98,再进一步做ASCII编码,最后UrlEncode的结果就为:%E9%AB%98。
由此可见,UrlEncode是出于URL安全解析的需要,Encode的结果是由%和一部分安全的ASCII码所组成。UrlEncode的缺点也比较明显,Encode非ASCII码的时候(比如中文),一个字节会被encode成3个字节,长度整整是原先的3倍,造成流量的浪费。
我见过有人使用base64来对query string做encode,这是把概念搞混淆了,至少base64 encode之后的=就不是一个URL安全的字符,=在UrlEncode之后对应%3d。
Header的解析
对于Header的解析可以先按CRLF分割成一个个的键值对,键值对里面的值,也就是我们所说的field content其实也有编码要求。 RFC 7230 中有阐述:
Historically, HTTP has allowed field content with text in the ISO-8859-1 charset [ISO-8859-1], supporting other charsets only through use of [RFC2047] encoding. In practice, most HTTP header field values use only a subset of the US-ASCII charset [USASCII]. Newly defined header fields SHOULD limit their field values to US-ASCII octets. A recipient SHOULD treat other octets in field content (obs-text) as opaque data.
简单来说,我们在实际使用当中使用ASCII码来限制field content。我们常用几个Field,诸如Host,User-Agent等,使用ASCII码字符也已绰绰有余,一般不会对值做进一步的encode处理。
Body的解析
body的解析是我们平时打交道最多的部分,不是说我们需要知道如何去解析body,而是要了解body体里的数据格式。
body的解析本身比较简单,从header中知道Content-Length之后,读取固定长度的字节流即完成了body的获取,关键的环节是获取之后,如何读取其中的数据并递交给应用层,所以HTTP协议本身并没有对Body中的内容编码做约束,而是把它交给协议的使用者去决定,我们甚至可以在body体里存放二进制流,对应的Content-Type为application/octet-stream。
我们来看看平时发送HTTP请求时,以AFNetworking为例,使用最频繁的几种Content-Type:
- multipart/form-data
- application/x-www-form-urlencoded
- application/json
当我们向Server发送数据的时候,需要和Server约定好所使用的Content-Type,客户端在发送Request的时候也要注意API的差别,以AFNetworking为例,发送json则使用:
AFJSONRequestSerializer* jsonSerializer = [AFJSONRequestSerializer serializer]; request = [jsonSerializer requestWithMethod:@"POST" URLString:requestUrl parameters:requestParams error:nil];
发送multipart/form-data:
request = [self.requestSerializer multipartFormRequestWithMethod:@"POST" URLString:requestUrl parameters:requestParams constructingBodyWithBlock:nil error:nil];
发送x-www-form-urlencoded:
request = [self.requestSerializer requestWithMethod:@"POST" URLString:requestUrl parameters:requestParams error:nil];
json不用多说,大家都非常熟悉的数据交换格式。multipart/form-data和x-www-form-urlencoded比较容易引起混淆。
在AFNetworking中有这样一段代码:
//AFURLRequestSerialization
if (![mutableRequest valueForHTTPHeaderField:@"Content-Type"]) {
[mutableRequest setValue:@"application/x-www-form-urlencoded" forHTTPHeaderField:@"Content-Type"];
}
可见当我们的Request没有设置Content-Type的时候,默认使用的就是application/x-www-form-urlencoded。这里的urlencoded和前面Request-URI中的urlencode是一回事,只不过encode的是body体当中的内容。
那我们什么时候用application/x-www-form-urlencoded,什么时候用multipart/form-data呢?
先来看下使用Content-Type为multipart/form-data时,我们的Request有什么变化,下图是使用mitmproxy抓包一个文件上传Request的headers示意图:
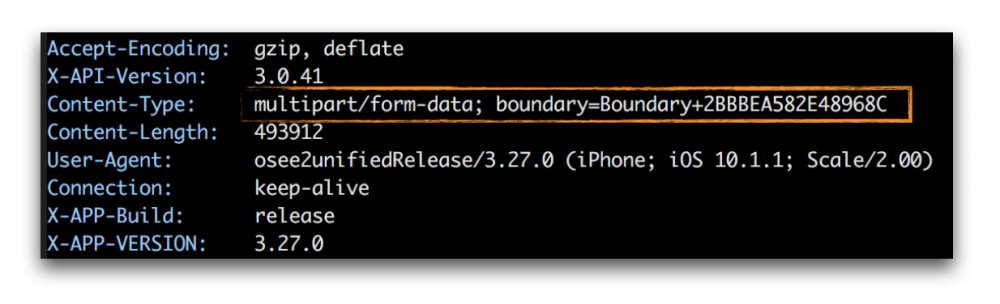
Content-Type的完整值为:multipart/form-data; boundary=Boundary+2BBBEA582E48968C。
multipart把body体分成多个块,多个块之间依赖于boundary值去做分割,所以生成的boundary要足够长,长到在字节流当中出现重复的概率几乎为0,否则就会导致错误的传输,AFNetworking中生成Boundary的方法如下:
static NSString * AFCreateMultipartFormBoundary() {
return [NSString stringWithFormat:@"Boundary+%08X%08X", arc4random(), arc4random()];
}
我们可以看下一个例子,如果使用multipart/form-data,body中具体的数据格式:
Boundary+2BBBEA582E48968C Content-Disposition: form-data; name="text1" text Boundary+2BBBEA582E48968C Content-Disposition: form-data; name="text2" another text
可以看到在body中多出了Boundary+2BBBEA582E48968C和Content-Disposition,这些会增加body的传输大小。
假设我们有一个大文件需要上传,如果使用application/x-www-form-urlencoded作为Content-Type,由于字节流当中存在非常多的非ASCII码,文件的长度会变至原本的2-3倍,所以此时multipart/form-data更合适。
假设我们只有少量的键值对需要上传,如果使用multipart/form-data作为Content-Type,由于boundary和Content-Disposition带来的额外流量,又显得得不偿失,所以此时使用application/x-www-form-urlencoded更为合适。
这也是为什么我们使用multipart/form-data作为文件类Request的Content-Type,而对于普通业务数据,则使用application/x-www-form-urlencoded或者application/json。
总结
上述的分析,更多的是站在客户端的角度去看的,实际HTTP协议的构成细节非常之多,需要旷日持久的深入学习和积累。功夫越深,坑越少 ;)
欢迎关注公众号:MrPeakTech

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

