Flink流处理之迭代任务
前面我们分析过Flink对迭代在流图中的特殊处理,使得迭代中的反馈环得以转化为普通的DAG模型。这一篇我们将剖析运行时的流处理迭代任务的执行机制。这里涉及到两个任务类:
- StreamIterationHead:迭代头任务,它借助于反馈阻塞队列从迭代尾部接收参与下一次迭代的反馈数据。
- StreamIterationTail:迭代尾任务,它借助于阻塞队列作为反馈信道将下一次需要迭代的数据反馈给迭代头。
对于迭代流处理而言,随着任务(task)最终被并行化执行,它们的子任务(sub task,这些任务在计算节点中的实例)的并行度要求一致,并且迭代头的子任务与迭代尾的子任务必须成对且处于同一个CoLocationGroup中执行,这些都反映了流处理的迭代任务的特殊性,可以认为是一种并发与并行兼具的模式。
StreamIterationHead和StreamIterationTail之间的交互依赖于阻塞队列代理(BlockingQueueBroker)。Flink设计了一种称之为Broker的数据结构,专门用于对迭代进行并发控制,而BlockingQueueBroker是Broker针对BlockingQueue类型的特定实现。因为Broker内部的核心数据结构就是ConcurrentMap<String, BlockingQueue<V>>类型,所以BlockingQueueBroker对应的类型即为:ConcurrentMap<String, BlockingQueue<BlockingQueue>>其图示如下:
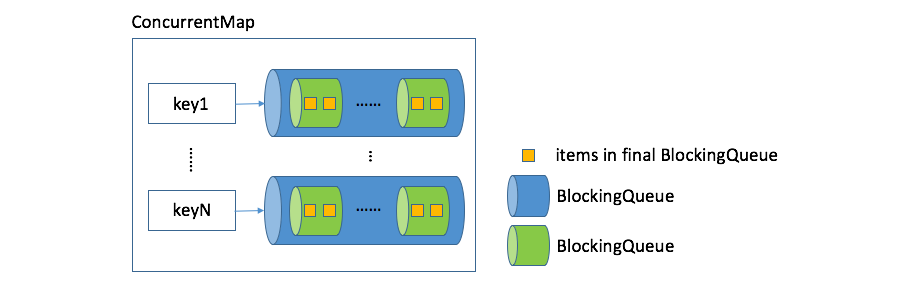
迭代头任务跟迭代尾任务之间真正交互的数据结构是容量为1的阻塞队列:
final BlockingQueue<StreamRecord<OUT>> dataChannel = new ArrayBlockingQueue<StreamRecord<OUT>>(1);
它会被加入到BlockingQueueBroker内部的ConcurrentMap中去,对应的键是brokerID。brokerID生成规则如下:
public static String createBrokerIdString(JobID jid, String iterationID, int subtaskIndex) {
return jid + "-" + iterationID + "-" + subtaskIndex;
}
BlockingQueueBroker是单例的,因为对应的迭代头子任务和迭代尾子任务会生成相同的brokerID,所以两者在同一个JVM中会基于相同的dataChannel进行通信。dataChannel由迭代头创建并递交给BlockingQueueBroker:
BlockingQueueBroker.INSTANCE.handIn(brokerID, dataChannel);
由迭代尾获取:
BlockingQueue<StreamRecord<IN>> dataChannel =
(BlockingQueue<StreamRecord<IN>>) BlockingQueueBroker.INSTANCE.get(brokerID);
数据交换是基于dataChannel的,由迭代尾负责生产:
publicvoidcollect(StreamRecord<IN> record){
try {
if (shouldWait) {
dataChannel.offer(record, iterationWaitTime, TimeUnit.MILLISECONDS);
} else {
dataChannel.put(record);
}
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
由迭代头负责消费:
while (running) {
StreamRecord<OUT> nextRecord = shouldWait ?
dataChannel.poll(iterationWaitTime, TimeUnit.MILLISECONDS) :
dataChannel.take();
if (nextRecord != null) {
for (RecordWriterOutput<OUT> output : outputs) {
output.collect(nextRecord);
}
} else {
// done
break;
}
}
因此,迭代头跟迭代尾的子任务之间通过反馈信道进行迭代数据处理的大致机制如下图:
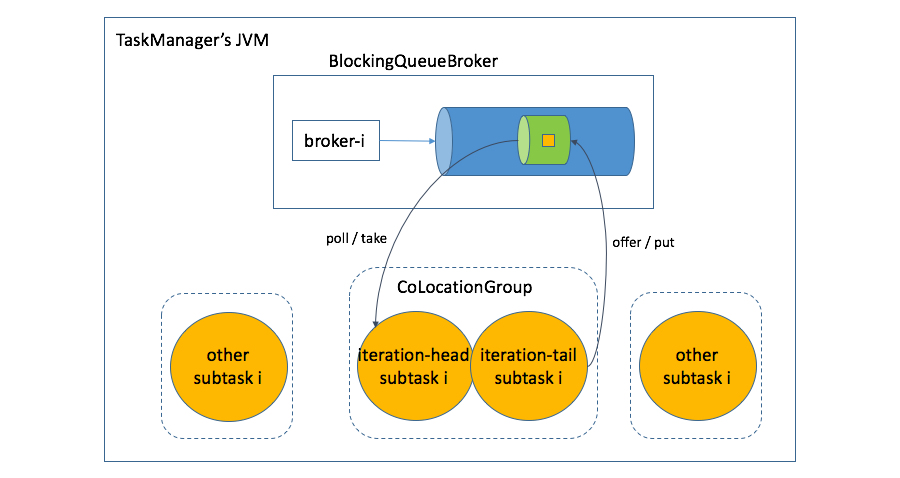
相信分析到这里,我们应该明白了为什么迭代头和迭代尾的并行度必须一致,且处于相同的CoLocationGroup中。Flink在执行拓扑中巧妙地化解了反馈环,从而使其适应于DAG计算模型,但却在同一个TaskManager的迭代头和迭代尾对应的子任务中借助于阻塞队列的生产者和消费者模型重塑了反馈“环”。
微信扫码关注公众号:Apache_Flink

QQ扫码关注QQ群:Apache Flink学习交流群(123414680)
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

