36大数据专稿,原文作者:Nikhil Buduma 本文由1号店-欧显东编译向36大数据投稿,并授权36大数据独家发布。转载必须获得本站及作者的同意,拒绝任何不标明作者及来源的转载!
对许多机器学习研究者来说,自动编码(Autoencoders)是一个非常激动人心的无监督学习方法,他们取得的进展已经超过了数十年的研究人员研究的手选编码特征。
假设您正在处理一个很酷的图像处理项目,和你的目标是建立一个算法,分析当时的情感。在256×256像素灰度图像作为输入,然后输出了一个表情作为结果。例如,如果你通过下面的图片,你期望算法的标签是“快乐”。

在我们满意这种方法之前这看起来非常不错,但是让我们退一步想想这到底意味着什么。256×256像素灰度图像对应一个输入矢量的65000尺寸。换句话说,我们正在试图解决一个在65000维空间的问题。这不是一件特别容易的事,即使对一个电脑来说。不仅是大型输入,存储,移动和计算,而且也产生一些相当不容易处理的干扰。
让我们大致了解一下随着维数的增加导致机器学习问题的难度。根据C.J. Stone 在1982年的一项研究显示,所花费的时间(特别是非参数回归)模型适合您的数据在最佳比例是m ^ { – p /(2 p + d)},m是数据点的数量,数据的维数d,p是一个参数,取决于模型我们使用(具体地说,我们假定回归函数p次可微的)。简而言之,这个关系意味着我们需要更多的训练例子成倍地增加我们的输入维数。
通过考虑Gutierrez-Osuna所研究的一个简单的例子我们可以观察这个图形。我们的学习算法将划分特征空间统一进入一个箱子作为我们所有的训练示例。然后我们在每个箱子中分配一个标签根据在箱子中找到的主类。最后,对于每一个我们要分类的新样本,我们只需要找出落入的标签样本和原来的标签。
在我们的问题中,我们首先选择一个单一特征(一维输入)并把空间分成3个简单的箱子,如下图:

可以理解的是,我们注意到有太多的重叠类,所以我们决定添加另一个特性来提高分离性。但是我们注意到,如果我们保持相同数量的样本,我们得到一个二维散点图这真的看起来是非常稀疏的,也真的很难确定任何有意义的关系如果不增加样本的数量。如果我们进行三维输入,那么它会变得更糟。现在我们试图填补更多3 ^ { 3 } = 27箱与相同数量的例子。散点图几乎是空白。
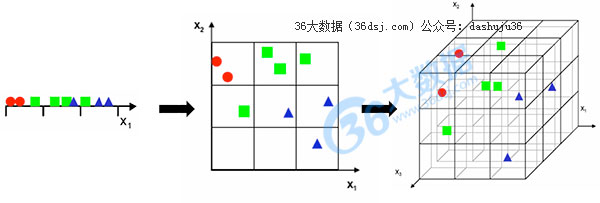
重要的是,这不是一个很容易地可以通过更有效的计算或改善硬件来解决的问题。对许多机器学习者来说,收集培训样本是最耗时的部分,所以这结果迫使我们要谨慎选择分析。如果我们能够输入一些足够小的维度,也许我们可以把一个不可行的问题变成一个可行的问题。
回到最初的判别的面部表情问题,很明显我们不需要65000维度对一个图像进行分类。具体地说,我们的大脑会自动快速地通过有一些关键特征检测情感。例如,人的嘴唇的曲线,在一定程度上的额头上出现了皱纹,和他的眼睛的形状都能帮助我们确定照片中的人是否“快乐”。事实证明,这些特征可以方便地通过观察总结各种面部的相对定位要点、以及它们之间的距离。
 显然,这允许我们能够显著减少输入的维数(从65000到60),但也有一些限制。手选择的特征可以年复一年的去研究优化的效果。对于很多问题,特征是不容易选择的。例如,选择广义识别的对象特点这是很难的,算法需要分辨从面孔,从汽车等等。那么从我们的输入信息维度我们该如何提取?这是机器学习的一个领域,称为无监督学习。在下一节中,我们将讨论自动编码(autoencoder),杰弗里•辛顿开创的基于神经网络的一种无监督学习技术。我们将简要讨论自动编码(autoencoder)是如何工作并且如何与传统的线性方法的差距。例如对计算机视觉的主成分分析(PCA)和潜在语义分析(LSA)的自然语言处理。
显然,这允许我们能够显著减少输入的维数(从65000到60),但也有一些限制。手选择的特征可以年复一年的去研究优化的效果。对于很多问题,特征是不容易选择的。例如,选择广义识别的对象特点这是很难的,算法需要分辨从面孔,从汽车等等。那么从我们的输入信息维度我们该如何提取?这是机器学习的一个领域,称为无监督学习。在下一节中,我们将讨论自动编码(autoencoder),杰弗里•辛顿开创的基于神经网络的一种无监督学习技术。我们将简要讨论自动编码(autoencoder)是如何工作并且如何与传统的线性方法的差距。例如对计算机视觉的主成分分析(PCA)和潜在语义分析(LSA)的自然语言处理。
自动编码(Autoencoder)的简要概述
自动编码(autoencoder)是一种无监督的机器学习技术,利用神经网络产生的低维来代表高维输入。传统上,依靠线性降维方法,如主成分分析(PCA),找到最大方差在高维数据的方向。通过选择只有那些有最大方差的轴,主成分分析(PCA)的目的是捕获包含的大部分信息输入的方向,所以我们可以尽可能用最小数量的维度。主成分分析(PCA)的线性度然而限制了可以提取的特征维度。但是自动编码(Autoencoders)用固有的非线性神经网络克服了这些限制。
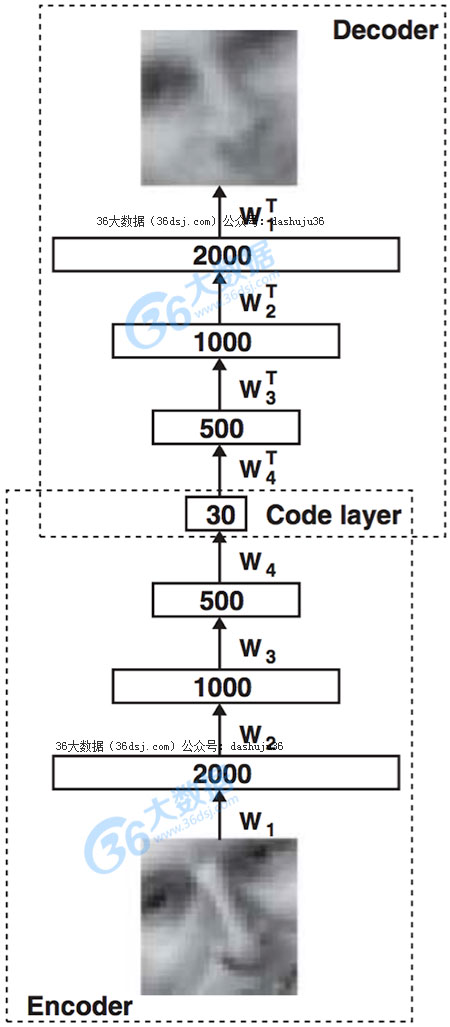
自动编码(autoencoder)的基本结构
自动编码(autoencoder)由两个主要部分组成,编码器网络和译码器网络。编码器网络在训练和部署的时候被使用,而译码器网络只是在训练的时候使用。编码器网络的目的是找到一个给定的输入的压缩表示。在这个例子中,我们从2000 个维度的输入中生成了30个维度。译码器网络的目的只是一个编码器网络的反射,是重建原始输入尽可能密切。使用它在训练的目的是为了迫使自动编码(autoencoder)选择最丰富特征的压缩。尽可能靠近原始输入。
所以自动编码(autoencoder)如何与线性竞争对手比较?让我们看看一些由Hinton and Salakhutdinov在2006年首次亮相的实验。首先,,我们看看自动编码(autoencoders)如何可以重建原来的输出与使用30维度主成分分析(PCA)相比。
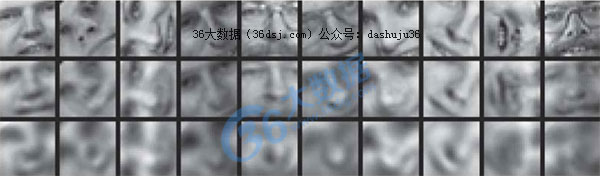
自动编码(autoencoder)(中间)和PCA(底部)原始图像输入(上)
从上图可以看出,自动编码(autoencoder)明显优于PCA输出,,这是一个非常理想的结果。我们可以探索自动编码(autoencoders)是否可以显著提高我们的数据集通过比较二维可分性准则。这个由一个二维的自动编码(autoencoder)生成的PCA的数据集。

比较二维可分性的准则生成的自动编码(autoencoder)(右)和PCA(左)数据集
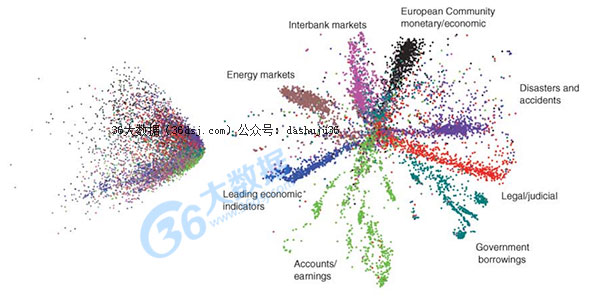
最后,我们更大幅度的改进,当我们把自动编码(autoencoder)对照无监督学习技术自然语言(LSA)。
结论:
自动编码(Autoencoders)无监督学习对于每一个主要的机器学习任务是一个非常令人兴奋的新方法,他们已经取得的进展超过了数十年的研究人员通过手选特征来研究的进展,我们讨论了很多,但我们仍然只在冰山的一角。在接下来的博客文章,我将进入更深度探讨自动编码(autoencoders)是如何工作的?如何有效地训练他们?和其他有效的优化(如稀疏)。如果你有兴趣,喜欢的话请给我写信在nkbuduma@gmail.com。我很兴奋能听到新的视野。
原文标题:Deep Learning, The Curse of Dimensionality, and Autoencoders
End.














![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

