C/C++协程库libco:微信怎样漂亮地完成异步化改造
编者按
如今,微信拥有月活跃用户8亿。
不可否认,当今的微信后台拥有着强大的并发能力。
不过, 正如罗马并非一日建成;微信的技术也曾经略显稚嫩。
微信诞生于2011年1月,当年用户规模为0.1亿左右;2013年11月,微信月活跃用户数达到3.55亿,一跃成为亚洲地区拥有最大用户群体的移动终端即时通讯软件。
面对如此体量的提升,微信后台也曾遭遇棘手的窘境;令人赞叹的是技术人及时地做出了漂亮的应对。
这背后有着怎样的技术故事?
此时此刻,你在微信手机端发出的请求,是怎样被后台消化和处理的?
这次,InfoQ聚焦微信后台解决方案之协程库libco。
该项目在保留后台敏捷的同步风格同时,提高了系统的并发能力,节省了大量的服务器成本;自2013年起稳定运行于微信的数万台机器之上。
本文源自InfoQ对Leiffy的采访和《揭秘:微信如何用libco支撑8亿用户》的整理。
微信后端遇到了问题
早期微信后台因为业务需求复杂多变、产品要求快速迭代等需求,大部分模块都采用了半同步半异步模型。接入层为异步模型,业务逻辑层则是同步的多进程或多线程模型,业务逻辑的 并发能力只有 几十到几百。
随着微信业务的增长,直到2013年中,微信后台机器规模已达到1万多台,涉及数百个后台模块,RPC调用每分钟数十亿。在如此庞大复杂的系统规模下,每个模块很容易受到后端服务或者网络抖动的影响。因此我们急需对微信后台进行异步化的改造。
异步化改造方案的考量
当时我们有两种选择:
- A 线程异步化:把所有服务改造成异步模型,等同于从框架到业务逻辑代码的彻底改造
- B 协程异步化:对业务逻辑非侵入的异步化改造,即只修该少量框架代码
两者相比,工作量和风险系数的差异显而易见。虽然A方案 服务器端多线程异步处理 是常见做法,对提高并发能力这个原始目标非常奏效;但是对于微信后台如此复杂的系统,这过于耗时耗力且风险巨大。
无论是异步模型还是同步模型,都需要保存异步状态。所以两者在技术细节的相同点是,两个方案,都是需要维护当前请求的状态。在A异步模型中方案,当请求需要被异步执行时,需要主动把请求相关数据保存起来,再等待状态机的下一次调度执行;而在B协程模型方案中,异步状态的保存与恢复是自动的,协程恢复执行的时候就是上一次退出时的上下文。
因此,B协程方案不需要显式地维护异步状态:一方面在编程上可以更简单和直接;另一方面协程中只需要保存少量的寄存器。 因此在复杂系统上,协程服务的性能可能比纯异步模型更优。
综合以上考虑,最终我们选择了B方案,通过协程的方式对微信后台上百个模块进行了异步化改造。
接管历史遗留的同步风格API
方案敲定之后,接下来做的就是实现异步化的同时尽可能地少做代码修改。
通常而言,一个常规的网络后台服务需要connect、write、read等系列步骤,如果使用同步风格的API对网络进行调用,整个服务线程会因为等待网络交互而挂起,这就会造成等待并占用资源。原来的这种情况很明显地影响到了系统的并发性能,但是当初这样的选择是因为对应的 同步编程风格具有其独特的优势:代码逻辑清晰、易于编写并且支持业务快速迭代敏捷开发。
我们的改造方案需要消除同步风格API的缺点,但是同时还希望保持同步编程的优点。
最后在不修改线上已有的业务逻辑代码的情况下,我们的libco框架创新地接管了网络调用接口(Hook)。 把协程的让出与恢复作为异步网络IO中的一次事件注册与回调。 当业务处理遇到同步网络请求的时候,libco层会把本次网络请求 注册为异步事件 ,当前的协程让出CPU占用,CPU交给其它协程执行。在网络事件发生或者超时的时候,libco会自动的恢复协程执行。
libco的架构
libco架构从设计的时候就已经确立下来了,最近的在GitHub上一次较大更新主要是功能上的更新。(注:libco为开源项目,源码同步更新,可移步: https://github.com/tencent/libco )。
libco框架有三层:分别是协程接口层、系统函数Hook层以及事件驱动层。
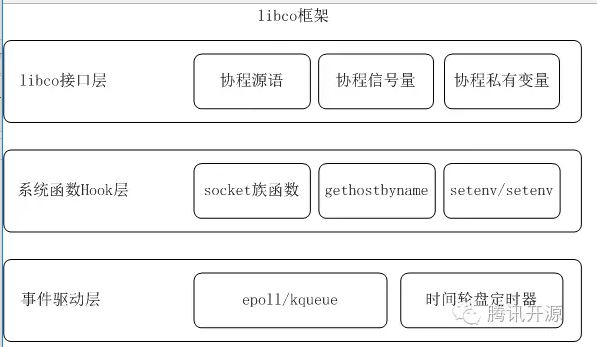
协程接口层实现了协程的基本源语。co_create、co_resume等简单接口负责协程创建于恢复。co_cond_signal类接口可以在协程间创建一个协程信号量,可用于协程间的同步通信。
系统函数Hook层负责主要负责系统中同步API到异步执行的转换。对于常用的同步网络接口,Hook层会把本次网络请求注册为异步事件,然后等待事件驱动层的唤醒执行。
事件驱动层实现了一个简单高效的异步网路框架,里面包含了异步网络框架所需要的事件与超时回调。对于来源于同步系统函数Hook层的请求,事件注册与回调实质上是协程的让出与恢复执行。
相比线程,选择协程意味着?
比起线程,对于很多人而言,协程的应用并不是那么轻车熟路。
线程和协程的相同点是什么?
我们可以简单认为协程是一种用户态线程,它与线程一样拥有独立的寄存器上下文以及运行栈,对程序员最直观的效果就是,代码可以在协程里面正常的运作,就像在线程里面一样。但是线程和协程还是有区别的,我们需要重点关注是运行栈管理模式与协程调度策略。关于这两点的具体执行,在本文后续部分会谈及。
那两者的不同点呢?
协程的创建与调度相比线程要轻量得多,而且协程间的通信与同步是可以无锁的,任一时刻都可以保证只有本协程在操作线程内的资源。
我们的方案是使用协程,但这意味着面临以下挑战:
- 业界协程在C/C++环境下没有大规模应用的经验;
- 如何处理同步风格的API调用,如Socket、mysqlclient等;
- 如何控制协程调度;
- 如何处理已有全局变量、线程私有变量的使用;
下面我们来探讨如何攻克这四个挑战。
挑战之一:前所未有的大规模应用C/C++协程
实际上,协程这个概念的确很早就提出来了,但是确是因为最近几年在某些语言中(如lua、go等)被广泛的应用而逐渐的被大家所熟知。但是真正用于C/C++语言的、并且是大规模生产的着实不多。
而这个libco框架中,除了协程切换时寄存器保存与恢复使用了汇编代码,其它代码实现都是用C/C++语言编写的。
那为什么我们选择了C/C++语言?
当前微信后台绝大部分服务都基于C++,原因是微信最早的后台开发团队从邮箱延续而来,邮箱团队一直使用C++作为后台主流开发语言,而且C++能满足微信后台对性能和稳定性的要求。
我们的C++后台服务框架增加了协程支持之后,高并发和快速开发的矛盾解决了。开发者绝大部分情况下只需要关注并发数的配置,不需要关注协程本身。其他语言我们也会在一些工具里面尝试,但是对于整个微信后台而言,C++仍是我们未来长期的主流语言。
挑战之二:保留同步风格的API
这里的做法我们在上文中提到了处理同步风格的API的思路方法:大部分同步风格的API我们都通过Hook的方法来接管了,libco会在恰当的时机调度协程恢复执行。
怎样防止协程库调度器被阻塞?
libco的系统函数Hook层主要处理同步API到异步执行的转换,我们当前的hook层只处理了主要的同步网络接口,对于这些接口,同步调用会被异步执行,不会导致系统的线程阻塞。当然,我们还有少量未Hook的同步接口,这些接口的调用可能会导致协程调度器阻塞等待。
与线程类似,当我们操作跨线程数据的时候,需要使用线程安全级别的函数。而在协程环境下,也是有协程安全的代码约束。在微信后台,我们约束了不能使用导致协程阻塞的函数,比如pthread_mutex、sleep类函数(可以用 poll(NULL, 0, timeout) 代替)等。而对于已有系统的改造,就需要审核已有代码是否符合协程安全规范。
挑战之三:调度千万级协程
调度策略方面,我们可以看下Linux的进程调度,从早期的O(1)到目前CFS完全公平调度,经过了很复杂的演进过程,而协程调度事实上也是可以参考进程调度方法的,比如说你可以定义一种调度策略,使得协程在不同的线程间切换,但是这样做会带来昂贵的切换代价。在进程/线程上面,后台服务通常已经做了足够多的工作,使得多核资源得到充分使用,所以协程的定位应该是在这个基础上发挥最大的性能。
libco的协程调度策略很简洁,单个协程限定在固定的线程内部,仅在网络IO阻塞等待时候切出,在网络IO事件触发时候切回,也就是说在这个层面上面可以认为协程就是有限状态机,在事件驱动的线程里面工作,相信后台开发的同学会一下子就明白了。
那怎么实现千万级别呢?
libco默认是每一个协程独享一个运行栈,在协程创建的时候,从堆内存分配一个固定大小的内存作为该协程的运行栈。如果我们用一个协程处理前端的一个接入连接,那对于一个海量接入服务来说,我们的服务的并发上限就很容易受限于内存。
所以量级的问题就转换成了怎样高效使用内存的问题。
为了解决这个问题,libco采用的是共享栈模式。(传统运行栈管理有stackfull和stackless两种模式) 简单来讲,是若干个协程共享同一个运行栈。
同一个共享栈下的协程间切换的时候,需要把当前的运行栈内容拷贝到协程的私有内存中。为了减少这种内存拷贝次数,共享栈的内存拷贝只发生在不同协程间的切换。当共享栈的占用者一直没有改变的时候,则不需要拷贝运行栈。
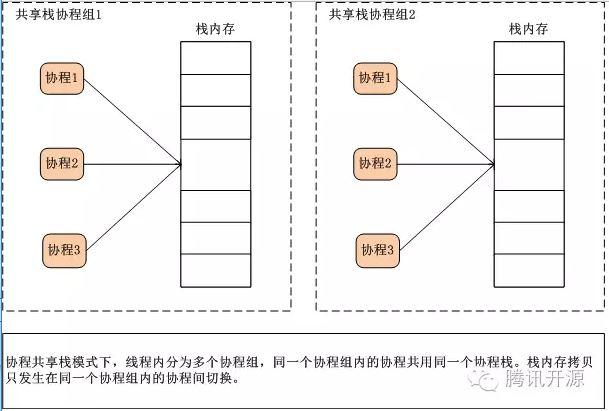
再具体一点讲讲共享栈的原理:libco默认模式(stackfull) 满足大部分的业务场景,每个协程独占128k栈空间,只需1G内存就可以支持万级协程。 而共享栈是libco新增的一个特性,可以支持单机千万协程,应对海量连接特殊场景。实现原理上,共享栈模式在传统的stackfull和stackless两种模式之间做了个微创新,用户可以自定义分配若干个共享栈内存,协程创建时指定使用哪一个共享栈。
不同协程之间的切换、 如何主动退出一个正在执行的协程?我们把共享同一块栈内存的多个协程称为协程组,协程组内不同协程之间切换需要把栈内存拷贝到协程的私有空间,而协程组内同一个协程的让出与恢复执行则不需要拷贝栈内存,可以认为共享栈的栈内存是“写时拷贝”的。
共享栈下的协程切换与退出,与普通协程模式的API一致,co_yield与co_resume,libco底层会实现共享栈的模式下的按需拷贝栈内存。
挑战之四:全局变量 VS私有变量
在stackfull模式下面,局部变量的地址是一直不变的;而stackless模式下面,只要协程被切出,那么局部变量的地址就失效了,这是开发者需要注意的地方。
libco默认的栈模式是每一个协程独享运行栈的,在这个模式下,开发者需要注意栈内存的使用,尽量避免 char buf[128 * 1024] 这种超大栈变量的申请,当栈使用大小超过本协程栈大小的时候,就可能导致栈溢出的core。
而在共享栈模式下,虽然在协程创建的时候可以映射到一个比较大的栈内存上面,但是当本协程需要让出给其它协程执行的时候,已使用栈的拷贝保存开销也是有的,因此最好也是尽量减少大的局部变量使用。更多的,共享栈模式下,因为是多个协程共享了同一个栈空间,因此,用户需要注意协程内的局部栈变量地址不可以跨协程传递。
协程私有变量的使用场景与线程私有变量类似,协程私有变量是全局可见的,不同的协程会对同一个协程变量保存自己的副本。开发者可以通过我们的API宏声明协程私有变量,在使用上无特别需要注意的地方。
多进程程序改造为多线程程序时候,我们可以用__thread来对全局变量进行快速修改,而在协程环境下,我们创造了协程变量ROUTINE_VAR,极大简化了协程的改造工作量。
关于协程私有变量,因为协程实质上是线程内串行执行的,所以当我们定义了一个线程私有变量的时候,可能会有重入的问题。比如我们定义了一个__thread的线程私有变量,原本是希望每一个执行逻辑独享这个变量的。但当我们的执行环境迁移到协程了之后,同一个线程私有变量,可能会有多个协程会操作它,这就导致了变量冲入的问题。为此,我们在做libco异步化改造的时候,把大部分的线程私有变量改成了协程级私有变量。协程私有变量具有这样的特性:当代码运行在多线程非协程环境下时,该变量是线程私有的;当代码运行在协程环境的时候,此变量是协程私有的。底层的协程私有变量会自动完成运行环境的判断并正确返回所需的值。
协程私有变量对于现有环境同步到异步化改造起了举足轻重的作用,同时我们定义了一个非常简单方便的方法定义协程私有变量,简单到只需一行声明代码即可。
简而言之
一句话总结libco库的原理,在协程里面用同步风格编写代码,实际运作是事件驱动的有限状态机,由上层的进程/线程负责多核资源的使用。
最终效果,大功告成
我们曾把一个状态机驱动的纯异步代理服务改成了基于libco协程的服务,在性能上比之前提升了10%到20%,并且,在基于协程的同步模型下,我们很简单的就实现了批量请求的功能。
正如当时所愿,我们使用libco对微信后台上百个模块进行了协程异步化改造,在整个的改造过程中,业务逻辑代码基本没有改变,修改只是在框架层代码。我们所做的是把原先在线程内执行的业务逻辑转到了协程上执行。改造的工作主要是复核系统中线程私有变量、全局变量、线程锁的使用,确保在协程切换的时候不会数据错乱或者重入。
至今,微信后台绝大部分服务都已是多进程或多线程协程模型,并发能力相比之前有了质的提升,而在这过程中应运而生的libco也成为了微信后台框架的基石。
作者简介
李方源, 微信高级工程师,目前负责微信后台基础框架及优化,致力于高性能、高可用的大规模分布式系统设计及研发,先后参与微信后台协程化改造项目、微信后台框架重构等项目。
libco为开源项目,源码同步更新,可移步: https://github.com/tencent /libco
拓展阅读: 揭秘:微信如何用libco支撑8亿用户?
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

