阿里应用运维体系演变
以下是我在Velocity China 2016上讲的内容。
演讲全文:
大家好,我是毕玄,我今天分享内容的主题叫阿里应用运维体系的演变。在讲这个话题之前,我简单讲一下阿里和Velocity会议的缘份。我记不清楚是几年前,我们有同事在美国参加Velocity大会后,觉得这个会在性能、前端,还有运维这三个专业领域上讲的非常专业,做的非常好。所以当时我们有同事和Velocity的官方一起努力想把这个会引进到中国,我们觉得这是一场非常专业的会议。所以非常欢迎来参加Velocity大会的人,还有感谢在Velocity大会上演讲的人,好,下面开始我今天的演讲。
我先简单介绍一下我自己。我是2007年加入阿里巴巴集团,在阿里九年来,一直做的都是基础技术领域相关的东西。现在外部知道比较多的,比如阿里的服务框架、HSF、HBase、异地多活、混合云,还有调度以及系统相关的东西。
大概是在2013年我从原来的基础技术部门转向运维部门,在这个部门待了三年左右。就是在这三年里,我基本经历了阿里巴巴在应用运维这个领域,我们所尝试的一些方向性的演变。这些方向现在看来,多数在运维领域都是很明确的方向,比如最早期的脚本时代,这是最基础的一个阶段,在脚本化以后就是工具化,然后就是很火热的DevOPS,然后朝自动化、智能化演进。方向很明确,但是在每个不同阶段演进过程中有很多问题,所有公司在往这些方向演进的过程中,很容易碰到各种各样的挑战和各种各样的问题。我们觉得整个业界在走这个过程的时候,谈失败教训的比较少一点,做成功经验分享的比较多一点。但相对来讲,其实失败经验可能更值得大家学习,成功经验则因为每家公司的情况不同而会不一样。
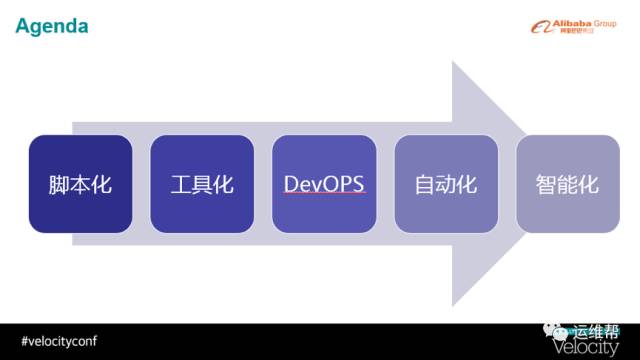 图3
图3
我简单讲一下阿里走过这几个方向的过程,并不代表阿里现在就是智能化,阿里同样是在不同的运维领域的不同阶段。我们可以看阿里在走整个过程中所碰到的一些问题。
阿里应用运个团队,首先要做所有日常运维的工作,像发布、扩容、重启、修改脚本等。另外就是环境的维护,比如操作系统升级这些也都是运维团队需要介入很多的。除了日常运维措施以外,阿里运维团队还会负责容量管理。一个典型的案例,比如每年的“双11”我们都会定一个指标,比如大家今年都知道阿里巴巴在今年“双11”17.5万笔的交易笔数峰值,其实我们在年初的时候,就会按照这个交易笔数去算,17.5万笔需要多少机器,每个应用需要怎么去分布?以前都是运维团队会介入,投入非常多的人力来计算怎么样去分布机器。所以容量管理会成为整个运维团队要花很大精力投入的一个方向。然后还有稳定性,所有运维团队都需要去做的。比如说我们需要看监控,我们需要接所有的报警,故障出来需要处理。上述是一个大概的范围,每家公司其实对运维团队的范围划分可能会不大一样。
脚本化,其实就是最早的阶段,所有的运维团队都干过。阿里大概是在2008年左右,我们会比较多的通过脚本化操作来做运维。那个时候我们会经常看到,运维同学会写一些单机的操作脚本,数量会有很多,而且还有一些批量操作的措施。这是最古老的时代,现在多数的运维团队可能已经跨过了这个时代,但是这个时代还有很多小的运维团队在开始的时候也都会经历。
这个阶段最容易出现最明显的问题就是,复杂的逻辑会非常难实现。这个我印象比较深刻,阿里为什么在这个阶段有很强的感受呢?我们在2008年到2009年年初左右的时候,我那个时候还不在运维团队,在中间件团队。当时我去看运维做发布,阿里那个时候大概在一个城市有两三个机房,我们就会看到发布的时候阿里当时有一个时间窗口,比如某天早上的一个小时内要完成所有的发布,那时候我们一个早上要完成100多个应用的发布,分布在两个机房,那时候因为没有发布系统,同学用批量脚本处理不同的机房,然后会看到运维同学打开很多不同的窗口。有时候会问一下运维同学,连他们自己也不知道这个应用现在发了哪几个机房,因为发的时候肯定不能全杀掉发,比如分一半,或者分更多批次,这个时候很容易忘哪些发过哪些没发过,哪些发布成功哪些没有成功。
我们现在再看那个阶段,我们就知道脚本化对我们来讲,虽然后面肯定还要有脚本,但是纯粹靠脚
本化完成运维操作的时代要过去了,而且是扛不住了。所以阿里开始各种各样新方法尝试的阶段,我们把这个阶段称为工具化时代。
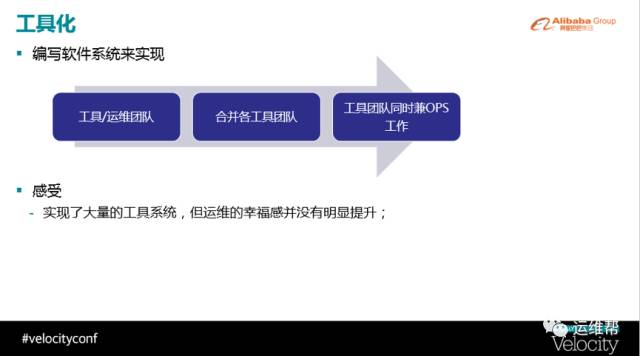 图4
图4
工具化的时代非常简单,思想就是通过软件的系统实现所有运维的复杂操作。复杂操作的背后仍可能是单机上的脚本操作,因为这对运维人员来讲是最容易维护的,如果全是程序化是非常难。所以这个时候的思想比较简单。
在工具化这个时代,我们尝试了非常多手段,怎么样让这个时代走的更好更顺畅。如果你的运维团队从一开始就以传统运维团队开始往前演进,估计碰到的问题会和阿里差不多。阿里最早觉得我要做运维系统,所以我们成立了一个工具团队,是专门做运维系统的,专门做软件层面的开发。同时还保留原来的运维团队,运维团队主要负责我刚刚讲的那一堆操作东西。这意味着工具团队不负责这些具体运维操作,只负责写系统。开始的时候这两个团队是分开的,然而在运转的过程中,我们就会很容易碰到下面这种情况:工具团队觉得我们自己做了很多工具,运维应该变得很幸福了;运维同学告诉你,其实我们生活没有变的很幸福,基本上跟以前差不多,甚至更惨了。
这个过程中,你很容易碰到这两个团队互相讲各自碰到的一些挑战和问题,包括各自认为自己做的好的部分,但是最终确实你能感受到的是,运维的这项工作好像没有被彻底改变掉,虽然有改变,比如以前可能是批量去一个黑屏窗口操作一堆的批量脚本,现在改变成了用一些有UI的系统,运维同学就是点点点,但是对运维同学来讲,并不一定是实质性的改变。另外,工具团队自己也会很容易出现成就感等等的问题,因为他们觉得,我明明做了很多东西,为什么运维团队的同学会不认可。
阿里在这个阶段大概走了有一年左右,因为当时差不多这两个团队都是我在带,后来我们觉得这个方式可能会有些问题。我们当时的判断是,之所以会出现上述现象有一个很大的原因,就是工具的质量不够高。比如说,为什么有些运维同学觉得有工具后,和以前相比并没有很大提升,甚至说更差,很大的原因是工具在运转的过程中出现这样那样的问题。当工具出问题的时候,运维同学会很难介入,这个时候会完全依赖工具团队来解决。这种情况往往让这些运维同学觉得,还不如手工操作好了,批量脚本完全可以搞定,出问题也能自己查。所以我们认为工具的质量是当时最大的问题。
以前阿里的组织结构决定了工具团队分散在很多不同的团队,比如网络有自己的运维团队,服务器有自己的运维等等,他们都是完全分开独立的。分开的情况下有一个问题,每个团队都会按照自己最熟悉的语言和架构建设自己的运维系统,所以也就导致最后运维系统不像我们的生产系统,生产系统可能有一个统一的架构固化,而这种运维级的系统出现的状况就则是百花齐放,什么都有,一出问题,各种语言各种架构的人都要出来了,所以整个体系的质量是非常难保证。总的来说我们认为工具质量是根本原因,其中工具团队的分散是主要因数之一。所以我们决定合并所有工具团队,把所有的工具团队合成一个团队,像一个软件研发部门来应对上述的运维问题,之后我们确实能够很好地的去应对各种质量的问题,包括建立起统一的运维系统体系。
 图5
图5
在这个阶段的过程中,我们的工具的质量确实在逐步提升,因为开始走统一化了,对架构与技术有更多的控制力了。但在完成这个阶段以后,我们仍然没有解决工具团队和运维团队分开的问题,所以我们后来决定尝试另外一种思路,干脆让工具团队自己做运维,比如工具团队认为我能把发布做好,就由工具团队把所有的发布工作全部承接,这样就变成一个团队的工作了,不存在更多的协调沟通问题。这个模式我们运转了一段时间,但我们觉得仍然有提升的空间。
在工具化这个阶段中,我们碰到的问题一方面是我刚才讲的那些,还有一个问题是推进落地。推进落地上,大家可能都知道,很多运维团队最早构建的时候,都是由偏系统操作的人才来构建的,而不是偏软件体系开发的人才来构建。所以这个体系会导致一个现象,那就是挫败感。因为写软件有些时候还是需要一定的时间,特别是你的软件要做到很高的成功率,要做到很好的质量,其实还是需要有时间积累的。所以在写这个软件的过程中,很容易出现挫败感,会导致你会觉得,我还不如不要写软件,用脚本好了。因为每个人都更相信自己可控的东西,不可控的东西会很难坚定的执行。所以,我们觉得在工具化的过程中,方向很容易被人接受,但是真的要坚定的走这条路,思想上是需要有转变的,而且需要有时间保障。比如运维团队中很容易出现一个现象,我可能一个星期全部都在处理线上问题,要么都在处理日常操作,处理活动需求等等,根本没有时间写软件,完全没有。所以这种情况下也不可能做工具化,也做不了。
软件质量是我们在这个过程中发现的最重要问题,阿里最早认为运维系统比较简单,我们后来在发展过程中,看到的第一个现象是成功率的问题,发现成功率和在线系统完全是两种思路,比如在线系统偏向于当系统出问题,后面系统有超时等各种各样问题的时候,我们使用尽可能让它失败掉。但是运维系统为了保证成功率,我们需要有失败的重试等等各种各样的策略,这个也是很高的要求。在成功率之后,我们逐渐碰到了像稳定性、性能这样的问题。因为我们的规模越来越大,比如我们同一天同一个时间段可能要完成非常多次的发布,一次发布后面可能对应上千台以上的机器,如何在这么短的时间内做到性能上的绝对保障,也是一个很大的挑战。
很简单,大家可以想一下每年的“双11”,“双11”零点就是一个时间点,肯定不能在那个时间点附件进行任何发布。但是有可能在那个时间点前的半个小时发现了一个紧急Bug,而且必须修复,这个时候对发布来讲就是个巨大考验,而且在阿里的发展历史上,确实碰到过一次这样的案例。所以我们越来越会觉得运维系统,除了成功率以外,在稳定性、性能这两个领域也面临巨大考验,它跟生产级的系统其实没有什么区别。
另外,我们在推动整个工具化的过程中,碰到另外一个问题是标准化,我们认为国外很多互联网公司在这点上做的相对较好,他们可能一成立的时候在运维体系上就会走标准化。比如一台机器上目录结构怎么样,日志放在哪里,端口是怎么样,可能全部都是标准,在公司一成立的时候,这个就已经是标准,这就决定了这个公司在以后不断演化的时候,他的运维系统是比较容易做的。但阿里是一个百花齐放的系统,那就意味着A业务和B业务的运维系统标准可能完全不一样,就是你连目录在哪儿都找不到,更不用说账号这些,所以导致运维系统非常难统一,必须面对多种环境做不一样的东西。所以标准化是我们在这个阶段中遇到的另外一个大问题,我觉得是阿里在后几年不断做运维系统过程中明白了一个道理,以前埋下的一个坑后面要花很多年的时间来填补。
因为工具化阶段化碰到的这么多问题,让阿里意识到我们工具化中欠缺了一个核心思想,即以软件体系构建整个运维体系,包括思想层面,即以一个软件工程师的思想来做运维体系。大家看这页幻灯片,《SRE:Google运维解密》这本书中提到的Google的SRE团队,他们可能是业界做的相对较好的运维团队,在这本书中,有几句很经典的话,我稍微摘录了一下。比如Google认为SRE是DevOPS模型在Google的最佳具体实践,DevOPS只是个思想,它不是一个可落地的东西,因为光讲思想是落地不了的,思想这个东西大家听完可能就结束了。关键是这个思想怎么被落地?Google认为,SRE就是DevOPS的最好展现。像SRE团队有一个核心思想,他会强调,我是一个软件工程师,所以我应该用软件的方法去应对重复劳动,这个是所有软件工程师刻在骨子里不会被改变的思想。因为软件工程师很难接受自己做一件重复的事情,重复做很多次,他基本上愿意花更多的时间做系统。
 图6
图6
另外我们可以从这本书里看到GoogleSRE团队在时间上有保障的。比如说SRE的团队必须花50%的精力在真正的开发工作中。很多团队其实也想做到这样,但关键是做不到,你可能也会说,我也希望我的团队50%做研发50%做运维。但是你会发现运维压力太大了,还是别做开发了。同样处于这个阶段,Google有明确的方案来做时间保障。比如说,他如果觉得超过50%,他会把这个压力转接给研发团队,自然会保证运维团队的时间分配。所以,正如Google的这本书里提到的,我们认为在SRE是DevOPS思想在Google落地的一个很好展现。
阿里也认为,DevOPS是我们的方向,DevOPS是我们更好的解决工具化的一个方案,就是一种思想。但关键是,我们怎么样才能把这个思想在阿里落地。所以阿里今年做了应该算很大的一次组织结构调整,我们决定把负责整个集团业务的应用运维团队拆掉,直接交还给所有的研发团队,我们的目标是日常的运维操作逐步让研发自己去做。但这是有前提的,比如说你要把日常的运维操作全部交给这个系统的研发人员去做,意味着需要有一套很高质量的运维系统。如果你没有这个系统研发估计就要崩溃了,所以这里面的挑战在于工具化的程度。但是因为交还给了研发团队,所以我们相信在这个阶段中,可以把我们在工具化这个阶段碰到的各种问题都解决掉。
另外,我们认为DevOPS思想落地有一个很大的问题,就是到底怎么落地的问题。在这个过程中我们觉得Docker是非常有效的让DevOPS强制落地的方案,Docker中有一个最典型的方案DockerFile。生产环境的一台机器的整个运行环境,可能不是研发独自搭出来的,最大的可能是研发搭了其中的一部分,然后运维给你搭了另外一部分。所以这个环境是由两个人共同搭出来的,也就是说,其实没有一个人能很清楚的描绘那个环境到底是什么,包括研发自己。所以在出问题时,问题排查就需要多方团队共同对信息,一起排查。但是因为DockerFile强制描述了这个应用运行的所有的环境信息,所以研发就会非常清楚所依赖的整个软件栈是怎么样,这个时候再出问题的时候会有极大的帮助。这是一个强制方案,所以可以让DevOPS更好的推进。
阿里现在仍然有很多东西在工具化这个阶段,但是自动化确实也有一些,我们也在朝这个方向演进。为什么以前让运维同学感觉到幸福感还不够?是因为工具很多时候还是要人点的。人点其实也是时间投入,而且可能是巨大的碎片化时间投入,会导致你工作很难持续。自动化意味着,怎么样让工具中人参与的多个环节直接演进到没有人参与,整个过程无人值守,这个实现起来其实非常难。
 图7
图7
比如说发布,发布是运维中最长的变更,一个发布动作怎么样能做到完全没有人?为什么很难?举个阿里的典型案例,发布完一台机器之后重启了,你怎么知道重启完的应用到底是正常还是不正常,这个判断标准挺难去确定的,现在业界有很多种方案去摸索,到底这个东西是正常还是不正常。这是一个很复杂的话题。更不要说网络设备的发布等等,更加复杂化了,因为你没有办法判断,而且一发就发上去了。所以怎么样朝无人值守演进是一个很难的方向。
另外,有些要做到无人值守,还会需要做到架构层面的支撑,比如阿里有机房级的流量一键切换的能力,最早的时候阿里在这个过程中,仍然有很多人工介入的部分,就是因为各个系统其实不具备这个能力,整个架构也不具备这个能力。所以我们为了做到这一点,整个架构层面都做了很多调整。
所以真的要做到自动化,我们认为这是运维中一个非常重大的里程碑,而且也非常难做到。我们碰到的主要问题是成功率,因为自动化意味着整个过程中显然成功率要做到非常高,因为只要一失败,就要有人介入,除此之外还需要架构的支撑能力。
智能化是现在很火的一个话题,很多场合都会讲智能运维。智能运维、智能化的前提显然是需要有大量的数据收集,如果没有足够的数据,足够的经验,因为运维的很多工作其实是经验,是很难做到自动化的,非常非常的难。所以智能化的前提是自动化,如果你连自动化都没有做好,智能化根本无从谈起。阿里运维还有很多故障的处理,故障到底出现在哪里,这都是非常难判断的。
我们现在的智能化运维只能做非常具体特征性的,比如我们尝试如果单个机房出现故障的时候,是不是可以做自动切换。但是可以看到这个面对的场景非常狭窄,而且会需要很强的特征匹配,所以这个就很难做了。
所以我们认为在智能化这个阶段,阿里有些领域在尝试,我们碰到的主要问题在数据的准确性。其实运维可能会收集很多数据,但是数据要做到精准,其实对技术能力有很高的要求。另外就是经验,所谓的经验,如果不是格式化的是很难被学习的,所以这也是一个很大的挑战。然后是特征层面,人工去提取的特征,就意味着那个特征会非常固定性,所以需要有机器学习的介入做特征的提取。所以,我们觉得先最好安心完成前面的工具化、自动化,在有大量数据的收集和大量经验的采集后,可以朝智能化这个方向去演进。
总的来讲,阿里经过这几年的摸索,我们觉得DevOPS显然是一个大的方向,但是这个方向要被落地,需要有机制的保障。比如说,Google的SRE之所以做的比较好,显然有机制级保障,就是整个公司对运维团队的机制保障。另外就是需要有有效的落地方法。然后自动化是运维领域中的巨大里程碑,智能化的前提就是刚刚讲的。这就是我今天的话题,谢谢大家!
原文 http://mp.weixin.qq.com/s/9uWlOzfryZHBXRRlWqUA9Q正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

