LinkedIn的即时消息:在一台机器上支持几十万条长连接
本文翻译自: Instant Messaging at LinkedIn: Scaling to Hundreds of Thousands of Persistent Connections on One Machine ,已获得原网站授权。作者 Akhilesh Gupta ,合作者 Cliff Snyder 。
最近我们介绍了 LinkedIn的即时通信 ,最后提到了分型指标和读回复。为了实现这些功能,我们需要有办法通过长连接来把数据从服务器端推送到手机或网页客户端,而不是许多当代应用所采取的标准的请求-响应模式。在这篇文章中会描述在我们收到了消息、分型指标和读回复之后,如何立刻把它们发往客户端。内容会包含我们是如何使用Play框架和Akka Actor Model来管理长连接、由服务器主动发送事件的。我们也会分享一些在生产环境中我们是如何在服务器上做负载测试,来管理数十万条并发长连接的,还有一些心得。最后,我们会分享在整个过程中我们用到的各种优化方法。
服务器发送事件
服务器发送事件( Server-sent events ,SSE)是一种客户端服务器之间的通信技术,具体是在客户端向服务器建立起了一条普通的HTTP连接之后,服务器在有事件发生时就通过这条连接向客户端推送持续的数据流,而不需要客户端不断地发出后续的请求。客户端要用到 EventSource接口 来以文本或事件流的形式不断地接收服务器发送的事件或数据块,而不必关闭连接。所有的现代网页浏览器都支持EventSource接口,iOS和安卓上也都有现成的库支持。
在我们最早实现的版本中,我们选择了基于Websockets的SSE技术,因为它可以基于传统的HTTP工作,而且我们也希望我们采用的协议可以最大的兼容LinkedIn的广大会员们,他们会从各式各样的网络来访问我们的网站。基于这样的理念, Websockets 是一种可以实现双向的、全双工通信的技术,可以把它作为协议的候选,我们也会在合适的时候升级成它。
Play框架和服务器发送的消息
我们LinkedIn的服务器端程序使用了 Play框架 。Play是一个开源的、轻量级的、完全异步的框架,可用于开发Java和Scala程序。它本身自带了对EventSource和Websockets的支持。为了能以可扩展的方式维护数十万条SSE长连接,我们把 Play和Akka结合 起来用了。Akka可以让我们改进抽象模型,并用 Actor Model 来为每个服务器建立起来的连接分配一个Actor。
// Client A connects to the server and is assigned connectionIdA
public Result listen() {
return ok(EventSource.whenConnected(eventSource -> {
String connectionId = UUID.randomUUID().toString();
// construct an Akka Actor with the new EventSource connection identified by a random connection identifier
Akka.system().actorOf(
ClientConnectionActor.props(connectionId, eventSource),
connectionId);
}));
}
上面的这段代码演示了如何使用 Play的EventSource API 来在程序控制器中接受并建立一条连接,再将它置于一个Akka Actor的管理之下。这样Actor就开始负责管理这个连接的整个生命周期,在有事件发生时把数据发送给客户端就被简化成了把消息发送给Akka Actor。
// User B sends a message to User A
// We identify the Actor which manages the connection on which User A is connected (connectionIdA)
ActorSelection actorSelection = Akka.system().actorSelection("akka://application/user/" + connectionIdA);
// Send B's message to A's Actor
actorSelection.tell(new ClientMessage(data), ActorRef.noSender());
请注意唯一与这条连接交互的地方就是向管理着这条连接的Akka Actor发送一条消息。这很重要,因此才能使Akka具有异步、非阻塞、高性能和为分布式系统而设计的特性。相应地,Akka Actor处理它收到的消息的方式就是转发给它管理的EventSource连接。
public class ClientConnectionActor extends UntypedActor {
public static Props props(String connectionId, EventSource eventSource) {
return Props.create(ClientConnectionActor.class, () -> new ClientConnectionActor(connectionId, eventSource));
}
public void onReceive(Object msg) throws Exception {
if (msg instanceof ClientMessage) {
eventSource.send(event(Json.toJson(clientMessage)));
}
}
}
就是这样了。用Play框架和Akka Actor Model来管理并发的EventSource连接就是这么简单。
但是在系统上规模之后这也能工作得很好吗?读读下面的内容就知道答案了。
使用真实生产环境流量做压力测试
所有的系统最终都是要用真实生产流量来考验一下的,可真实生产流量又不是那么容易复制的,因为大家可以用来模拟做压力测试的工具并不多。但我们在部署到真实生产环境之前,又是如何用真实的生产流量来做测试的呢?在这一点上我们用到了一种叫“暗地启动”的技术,在我们下一篇文章中会详细讨论一下。
为了让这篇文章只关注自己的主题,让我们假设我们已经可以在我们的服务器集群中产生真实的生产压力了。那么测试系统极限的一个有效方法就是把导向一个单一节点的压力不断加大,以此让整个生产集群在承受极大压力时所该暴露的问题极早暴露出来。
通过这样的办法以及其它的辅助手段,我们发现了系统的几处限制。下面几节就讲讲我们是如何通过几处简单的优化,让单台服务器最终可以支撑数十万条连接的。
限制一:一个Socket上的处于待定状态的连接的最大数量
在一些最早的压力测试中我们就常碰到一个奇怪的问题,我们没办法同时建立很多个连接,大概128个就到上限了。请注意服务器是可以很轻松地处理几千个并发连接的,但我们却做不到向连接池中同时加入多于128条连接。在真实的生产环境中,这大概相当于有128个会员同时在向同一个服务器初始化连接。
做了一番研究之后,我们发现了下面这个内核参数:
net.core.somaxconn
这个内核参数的意思就是程序准备接受的处于等待建立连接状态的最大TCP连接数量。如果在队列满的时候来了一条连接建立请求,请求会直接被拒绝掉。在许多的主流操作系统上这个值都默认是128。
在“/etc/sysctl.conf”文件中把这个值改大之后,就解决了在我们的Linux服务器上的“拒绝连接”问题了。
请注意Netty 4.x版本及以上在初始化Java ServerSocket 时,会自动从操作系统中取到这个值并直接使用。不过,如果你也想在应用程序的级别配置它,你可以在Play程序的 配置 参数中这样设置:
play.server.netty.option.backlog=1024
限制二:JVM线程数量
在让比较大的生产流量第一次压向我们的服务器之后,没过几个小时我们就收到了告警,负载均衡器开始没办法连上一部分服务器了。做了进一步调查之后,我们在服务器日志中发现了下面这些内容:
java.lang.OutOfMemoryError: unable to create new native thread
下面关于我们服务器上JVM线程数量的图也证实了我们当时出现了线程泄露,内存也快耗尽了。
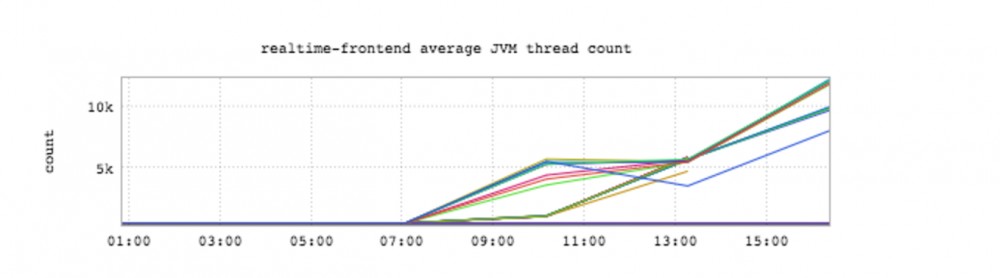
我们把JVM进程的线程状态打出来查看了一下,发现了许多处于如下状态的睡眠线程:
"Hashed wheel timer #11327" #27780 prio=5 os_prio=0 tid=0x00007f73a8bba000 nid=0x27f4 sleeping[0x00007f7329d23000] java.lang.Thread.State: TIMED_WAITING (sleeping)
at java.lang.Thread.sleep(Native Method)
at org.jboss.netty.util.HashedWheelTimer$Worker.waitForNextTick(HashedWheelTimer.java:445)
at org.jboss.netty.util.HashedWheelTimer$Worker.run(HashedWheelTimer.java:364)
at org.jboss.netty.util.ThreadRenamingRunnable.run(ThreadRenamingRunnable.java:108)
at java.lang.Thread.run(Thread.java:745)
经过进一步调查,我们发现原因是LinkedIn对Play框架的实现中对于Netty的空闲超时机制的支持有个BUG,而本来的Play框架代码中对每条进来的连接都会相应地创建一个新的 HashedWheelTimer 实例。这个 补丁 非常清晰地说明了这个BUG的原因。
如果你也碰上了JVM线程限制的问题,那很有可能在你的代码中也会有一些需要解决的线程泄露问题。但是,如果你发现其实你的所有线程都在干活,而且干的也是你期望的活,那有没有办法改改系统,允许你创建更多线程,接受更多连接呢?
一如既往,答案还是非常有趣的。要讨论有限的内存与在JVM中可以创建的线程数之间的关系,这是个有趣的话题。一个线程的栈大小决定了可以用来做静态内存分配的内存量。这样,理论上的最大线程数量就是一个进程的用户地址空间大小除以线程的栈大小。不过,实际上JVM也会把内存用于堆上的动态分配。在用一个小Java程序做了一些简单实验之后,我们证实了如果堆分配的内存多,那栈可以用的内存就少。这样,线程数量的限制会随着堆大小的增加而减少。
结论就是,如果你想增加线程数量限制,你可以减少每个线程使用的栈大小(-Xss),也可以减少分配给堆的内存(-Xms,-Xmx)。
限制三:临时端口耗尽
事实上我们倒没有真的达到这个限制,但我们还是想把它写在这里,因为当大家想在一台服务器上支持几十万条连接时通常都会达到这个限制。每当负载均衡器连上一个服务器节点时,它都会占用一个 临时端口 。在这个连接的生命周期内,这个端口都会与它相关联,因此叫它“临时的”。当连接被终止之后,临时端口就会被释放,可以重复使用。可是长连接并不象普通的HTTP连接一样会终止,所以在负载均衡器上的可用临时端口池就会最终被耗尽。这时候的状态就是没有办法再建立新连接了,因为所有操作系统可以用来建立新连接的端口号都已经用掉了。在较新的负载均衡器上解决临时端口耗尽问题的方法有很多,但那些内容就不在本文范围之内了。
很幸运我们每台负载均衡器都可以支持高达25万条连接。不过,但你达到这个限制的时候,要和管理你的负载均衡器的团队一起合作,来提高负载均衡器与你的服务器节点之间的开放连接的数量限制。
限制四:文件描述符
当我们在数据中心中搭建起来了16台服务器,并且可以处理很可观的生产流量之后,我们决定测试一下每台服务器所能承受的长连接数量的限制。具体的测试方法是一次关掉几台服务器,这样负载均衡器就会把越来越多的流量导到剩下的服务器上了。这样的测试产生了下面这张美妙的图,表示了每台服务器上我们的服务器进程所使用的文件描述符数量,我们内部给它起了个花名:“毛毛虫图”。
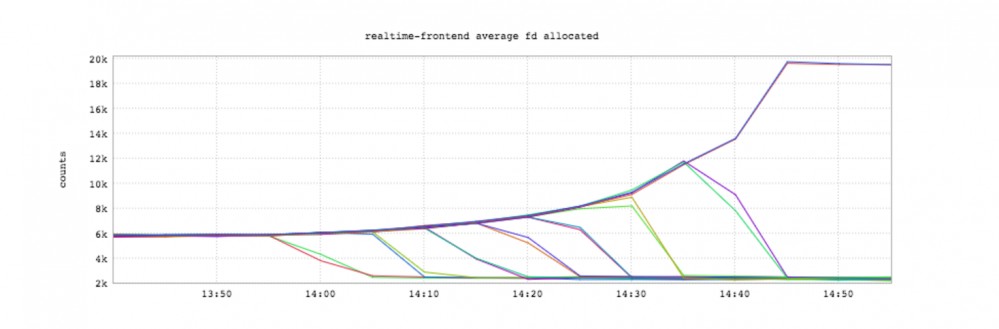
文件描述符在Unix一类操作系统中都是一种抽象的句柄,与其它不同的是它是用来访问网络Socket的。不出意外,每台服务器上支撑的持久连接越多,那所需要分配的文件描述符也越多。你可以看到,当16台服务器只剩2台时,它们每一台都用到了2万个文件描述符。当我们把它们之中再关掉一台时,我们在剩下的那台上看到了下面的日志:
java.net.SocketException: Too many files open
在把所有的连接都导向唯一的一台服务器时,我们就会达到单进程的文件描述符限制。要查看一个进程可用的文件描述符限制数,可以查看下面这个文件的“Max open files”的值。
$ cat /proc/<pid>/limits Max open files 30000
如下面的例子,这个可以加大到20万,只需要在文件/etc/security/limits.conf中添加下面的行:
<process username> soft nofile 200000 <process username> hard nofile 200000
注意还有一个系统级的文件描述符限制,可以调节文件/etc/sysctl.conf中的内核参数:
fs.file-max
这样我们就把所有服务器上面的单进程文件描述符限制都调大了,所以你看,我们现在每台服务器才能轻松地处理3万条以上的连接。
限制五:JVM堆
下一步,我们重复了上面的过程,只是把大约6万条连接导向剩下的两台服务器中幸存的那台时,情况又开始变糟了。已分配的文件描述符数,还有相应的活跃长连接的数量,都一下子大大降低,而延迟也上升到了不可接受的地步。
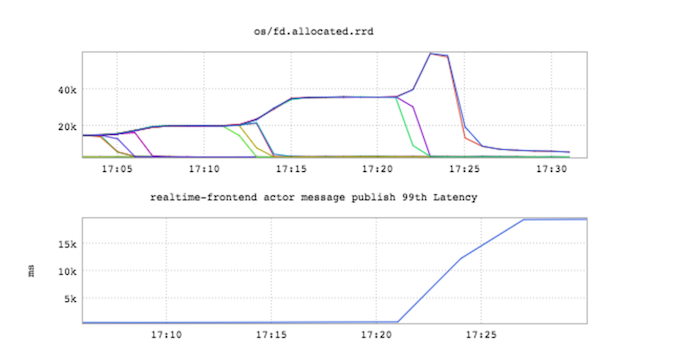
经过进一步的调查,我们发现原因是我们耗尽了4GB的JVM堆空间。这也造就了下面这张罕见的图,显示每次内存回收器所能回收的堆空间都越来越少,直到最后全都用光了。
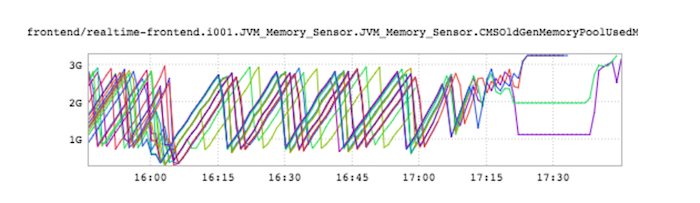
我们在数据中心的即时消息服务里用了TLS处理所有的内部通信。实践中,每条TLS连接都会消耗JVM的约20KB的内存,而且还会随着活跃的长连接数量的增加而增涨,最终导致如上图所示的内存耗尽状态。
我们把JVM堆空间的大小调成了8GB(-Xms8g, -Xmx8g)并重跑了测试,不断地向一台服务器导过去越来越多的连接,最终在一台服务器处理约9万条连接时内存再次耗尽,连接数开始下降。
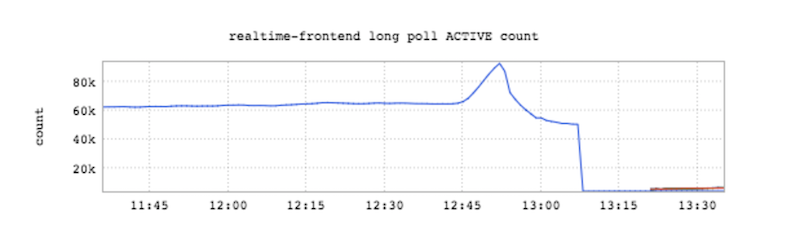
事实上,我们又把堆空间耗尽了,这一次是8G。
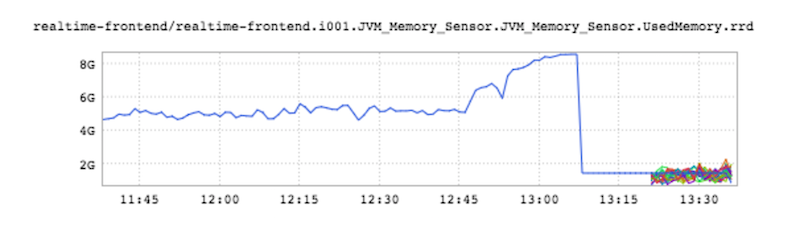
处理能力倒是从来都没用达到过极限,因为CPU利用率一直低于80%。
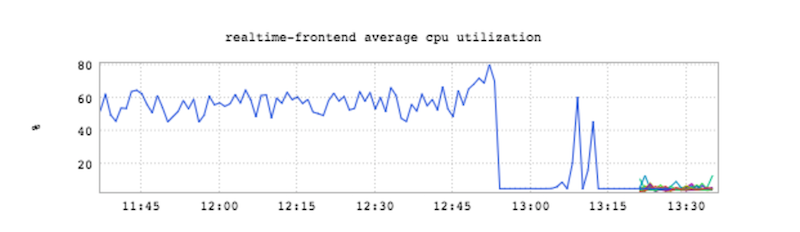
我们接下来是怎么测的?因为我们每台服务器都是非常奢侈地有着64GB内存的配置,我们直接把JVM堆大小调成了16GB。从那以后,我们就再也没在性能测试中达到这个内存极限了,也在生产环境中成功地处理了10万条以上的并发长连接。可是,在上面的内容中你已经看到,当压力继续增大时我们还会碰上某些限制的。你觉得会是什么呢?内存?CPU?请通过我的Twitter账号 @agupta03 告诉我你的想法。
结论
在这篇文章中,我们简单介绍了LinkedIn为了向即时通信客户端推送服务器主动发送的消息而要保持长连接的情况。事实也证明,Akka的Actor Model在Play框架中管理这些连接是非常好用的。
不断地挑战我们的生产系统的极限,并尝试提高它,这样的事情是我们在LinkedIn最喜欢做的。我们分享了在我们在我们经过重重挑战,最终让我们的单台即时通信服务器可以处理几十万条长连接的过程中,我们碰到的一些有趣的限制和解决方法。我们把这些细节分享出来,这样你就可以理解每个限制每种技术背后的原因所在,以便可以压榨出你的系统的最佳性能。希望你能从我们的文章中借鉴到一些东西,并且应用到你自己的系统上。
鸣谢
在LinkedIn开发即时通信功能的是一个大团队,里面有很多超牛的工程师。 Swapnil Ghike 、 Zaheer Mohiuddin 、 Aditya Modi 、 Jingjing Sun 和 Jacek Suliga 等领导了我们的开发,也主导解决了这篇文章中提到的许多问题。
正文到此结束
- 本文标签: 生命 Twitter web js 网站 API App 操作系统 http scala java struct cat 管理 CTO 解决方法 core Security linux 端口 压力 领导 CEO 参数 src message unix 进程 IDE 空间 list client IOS id 测试 线程 数据 TCP json Connection kk 希望 翻译 swap UI 代码 实例 开源 文章 长连接 协议 配置 多线程 Select 开发 ACE IO 服务器 负载均衡 集群 Netty DOM
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

