轻量级大规模机器学习算法库Fregata开源:快速,无需调参
一. 大规模机器学习的挑战
随着互联网,移动互联网的兴起,可以获取的数据变得越来越多,也越来越丰富。数据资源的丰富,给机器学习带来了越来越多,越来越大创造价值的机会。 机器学习在计算广告,推荐系统这些价值上千亿美元的应用中起到的作用越来越大,创造的价值也越来越大。但是越来越大的数据规模也给机器学习带来了很多挑战。
最大的挑战就是庞大的数据量使得对计算资源的需求也急剧增长。首先经典的机器学习算法其计算量基本上都是与训练数据条数或者特征数量呈二次方甚至是三次方关系的[1]。即是说数据量或者特征数每翻一倍,则计算量就要增加到原来的四倍,甚至是八倍。这样的计算量增长是十分可怕的,即使是采用可扩展的计算机集群一难以满足这样的计算量增长。好在对于很多依赖于凸优化方法的算法,可以采用随机梯度下降方法,将计算量的增长降到基本与数据量和特征数呈线性关系。但是, 大规模机器学习在计算上依然有三个比较大的困难。
第一,因为几乎所有的机器学习算法都需要多次扫描数据,对于大规模数据无论在什么平台上,如果不能全部存储在内存中,就需要反复从磁盘存储系统中读取数据,带来巨大的IO开销。在很多情况下,IO开销占到整个训练时间的90%以上。
第二,即使有足够的资源将所有数据都放到内存中处理,对于分布式的计算系统,模型训练过程中对模型更新需要大量的网络通信开销。无论是同步更新还是异步更新,庞大的数据量和特征数都足以使得通信量爆炸,这是大规模机器学习的另外一个瓶颈。
第三,大规模的模型使得无法在一个节点上存储整个模型,如何将模型进行分布式的管理也是一个比较大的挑战。
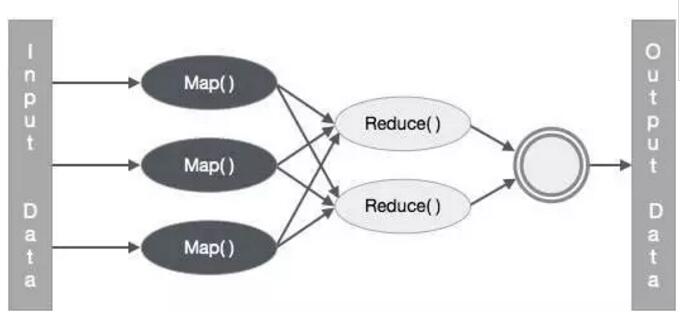
图 1
目前的主流大数据处理技术都是以Map Reduce计算模式为核心的(包括Hadoop和Spark)。而 Map Reduce 计算模式下对第一个问题只能通过增加内存,SSD存储来解决或者缓解,但同时也需要付出高昂的成本。对于第二,和第三个个问题,Map Reduce模式的局限是很难克服这两个问题的。
而 Parameter Server [2]作为目前最新的大规模机器学习系统设计模式,主要解决的其实是第三个问题,通过参数服务器以及模型参数的分布式管理来实现对超大规模模型的支持。同时在模型更新过程中的通信模式可以采用异步更新模式,来减小数据同步的开销,提高通信效率,但是Parameter Server模式下模型的更新量计算和模型的更新是分离的,其庞大的通信开销在原理上就是不可避免的。幸运的是,常见的大规模机器学习问题,都是高维稀疏问题,在很大程度上缓解了通信开销的问题,而Parameter Server突破了模型规模限制的优点是Map Reduce模式无法取代的,所以Parameter Server成为了目前大规模机器学习最先进,最受认可的模式。
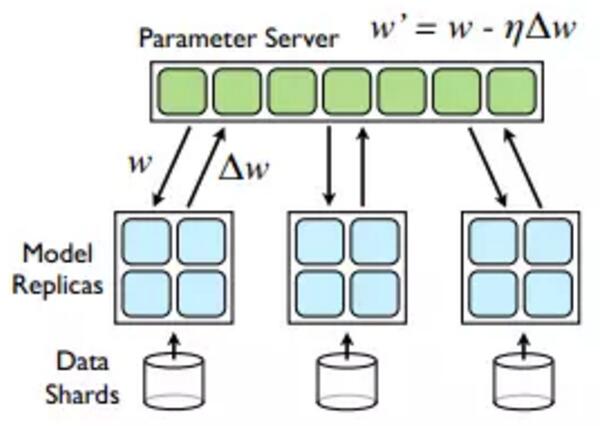
图 2
虽然Parameter Server解决了模型分布式管理的瓶颈,异步通信模式和问题本身的稀疏性大大降低了通信的压力。 但是机器学习算法本身对数据的多次扫描带来的计算和通信开销依然是大规模机器学习效率的很大瓶颈。
除此之外还有一个很大的挑战就是算法的 调参工作 , 一般机器学习算法都会依赖一个或者多个参数,对于同一问题,不同的参数设定对模型精度的影响是很大的,而同一参数设定在不同的问题上的效果也有很大的不同。对于从事机器学习工作的人来说,调参始终是一个令人的头疼的问题。知乎上有个问题是“调参这事儿,为什么越干越觉得像老中医看病?”[3],里面有不少关于机器学习调参的经验,心得,吐槽和抖机灵。
对于大规模机器学习问题,调参的难度显然是更大的:
首先,一次训练和测试过程的时间和计算资源开销都是庞大的,不管采用什么调参方法,多次实验都会带来很大的时间和计算资源消耗。
其次,大规模机器学习问题通常都是数据变化很快的问题,如计算广告和推荐系统,之前确定好的参数在随着数据的变化,也有劣化的风险。
目前来说 大规模机器学习存在的主要挑战 是两个: 第一 是计算资源的消耗比较大,训练时间较长的问题, 第二 是调参比较困难,效率较低。TalkingData在大规模机器学习的实践中也深受这两个问题的困然,特别是公司在早起阶段硬件资源十分有限,这两个问题特别突出。我们为了解决这个问题,做了很多努力和尝试。TalkingData最近开源的Fregata项目[4],就是我们在这方面取得的一些成果的总结。
二. Fregata的优点
Fregata是TalkingData开源的大规模机器学习算法库, 基于Spark ,目前支持Spark 1.6.x, 很快会支持Spark 2.0。目前Fregata包括了Logistic Regression, Softmax, 和Random Decision Trees三中算法。
三种算法中Logistic Regression, Softmax可以看作一类广义线性的参数方法,其训练过程都依赖于凸优化方法。我们提出了Greedy Step Averaging[5]优化方法,在SGD优化方法基础上实现了学习率的自动调整,免去了调参的困扰,大量的实验证明采用GSA 优化方法的Logstic Regression和Softmax算法的收敛速度和稳定性都是非常不错的,在不同数据规模,不同维度规模和不同稀疏度的问题上都能取得很好的精度和收敛速度。
基于GSA优化方法,我们在Spark上实现了并行的Logistic Regression和Softmax算法,我们测试了很多公开数据集和我们自己的数据,发现在绝大部分数据上都能够扫描一遍数据即收敛。这就大大降低了IO开销和通信开销。
其中Logsitic Regression算法还有一个支持多组特征交叉的变种版本,其不同点是在训练过程中完成维度交叉,这样就不需要在数据准备过程中将多组特征维度预先交叉准备好,通常这意味着数据量级上的数据量膨胀,给数据存储和IO带来极大压力。而这种多组特征交叉的需求在计算广告和推荐系统中又是非常常见的,因此我们对此做了特别的支持。
而Random Decision Trees[6][7]算法是高效的非参数学习方法,可以处理分类,多标签分类,回归和多目标回归等问题。而且调参相对也是比较简单的。但是由于树结构本身比较复杂而庞大,使得并行比较困难,我们采用了一些Hash Trick使得对于二值特征的数据可以做到扫描一遍即完成训练,并且在训练过程中对内存消耗很少。
总结起来,Fregata的优点就两个,第一是速度快,第二是算法无需调参或者调参相对简单。这两个优点降低了减少了计算资源的消耗,提高了效率,同时也降低了对机器学习工程师的要求,提高了他们的工作效率。
三. GSA算法介绍
GSA算法是我们最近提出的梯度型随机优化算法,是Fregata采用的核心优化方法。它是基于随机梯度下降法(SGD)的一种改进:保持了SGD易于实现,内存开销小,便于处理大规模训练样本的优势,同时免去了SGD不得不人为调整学习率参数的麻烦。
事实上,最近几年关于SGD算法的步长选取问题也有一些相关工作,像Adagrad, Adadelta, Adam等。但这些方法所声称的自适应步长策略其实是把算法对学习率的敏感转移到了其他参数上面,并未从本质上解决调参的问题,而且他们也引入了额外的存储开销。GSA和这些算法相比更加轻量级,易于实现且易于并行,比起SGD没有额外的内存开销,而且真正做到了不依赖任何参数。

我们把GSA算法应用于Logistic回归和Softmax回归,对libsvm上16个不同类型规模不等的数据集,和SGD,Adadelta,SCSG(SVRG的变种)这些目前流行的随机优化算法做了对比实验。结果显示,GSA算法在无需调任何参数的情况下,和其他算法做参数调优后的最佳表现不相上下。此外,GSA比起这些流行的方法在计算速度和内存开销方面也有一定的优势。
GSA算法的核心原理非常简单:在迭代的每一步对单个样本的损失函数做线搜索。具体来说,我们对逻辑回归和softmax回归的交叉熵损失函数,推导出了一套仅用当前样本点的梯度信息来计算精确线搜索步长的近似公式。我们把利用这套近似公式得到的步长做时间平均来计算当前迭代步的学习率。这样做有两方面的好处:基于精确线搜索得到的步长包含了当前迭代点到全局极小的距离信息——接近收敛时步长比较小,反之则更大,因而保证收敛速度;另一方面平均策略使算法对离群点更鲁棒,损失下降曲线不至剧烈抖动,为算法带来了额外的稳定性。
四. GSA算法Spark上的并行化实现
GSA算法是基本的优化方法,在Spark上还需要考虑算法并行化的问题。机器学习算法的并行化有两种方式,一种是数据并行,另一种是模型并行。但是Spark只能支持数据并行,因为模型并行会产生大量细粒度的节点间通信开销,这是Spark采用的BSP同步模式无法高效处理的。
数据并行模式下进行机器学习算法的并行化又有三种方法,分别是梯度平均,模型平均,以及结果平均。梯度平均是在各个数据分片上计算当前的梯度更新量然后汇总平均各分片上的梯度更新量总体更新模型。模型平均是各分片训练自己的模型,然后再将模型汇总平均获得一个总体的模型。而结果平均实际上就是Ensemble Learning, 在大规模问题上因为模型规模的问题,并不是一个好的选择。
实际上是目前采用得最多的是梯度平均,当前Parameter Server各种实现上主要还是用来支持这种方式,Spark MLLib的算法实现也是采用的该方式。但是在Spark上采用梯度平均在效率上也有比较大的瓶颈,因该方法计算当前的梯度更新量是要依赖于当前的最新模型的,这就带来了在各数据分片之间频繁的模型同步开销,这对Map Reuce计算模式的压力是较大的。
模型平均一直被认为其收敛性在理论上是没有保证的,但是最近Rosenblatt[8]等人证明了模型平均的收敛性。而我们在大量的测试中,也发现模型平均通常能取得非常好的模型精度。考虑到模型平均的计算模式更适合Map Reduce计算模型,我们在Fregata中对于GSA算法的并行方法采用的就是模型平均方法。模型平均的并行方法中,每个数据分片在Map阶段训练自己的模型,最后通过Reduce操作对各个分片上的模型进行平均,扫描一次数据仅需要做一次模型同步。而且在大量的实验中,该方法在扫描一次数据后,模型的精度就可达到很高的水平,基本接近于更多次迭代后的最好结果。
五. Fregata与MLLib对比
Fregata是基于Spark的机器学习算法库,因此与Spark内置算法库MLLib具有很高的可比性。我们这里简要介绍了三个数据集,两种算法(Logistic Regression和Softmax)上的精度和训练时间对比。精度指标我们采用的是测试集的AUC。对于精度和训练时间,算法每扫描完一次数据记录一次。
Fregata的算法不需要调参,因此我们都只做了一次实验。而对于MLLib上的算法,我们在各种参数组合(包括优化方法的选择)中进行了网格搜索,选取了测试集AUC能达到最高的那组参数作为对比结果。
Lookalike是一个基于Fregata平台运用比较成熟的服务,其目标在于根据种子人群进行人群放大以寻找潜在客户。我们将Lookalike作为二分类问题来处理,因此可以采用Logistic Regression算法来处理。在训练模型时以种子人群为正样本,其他为负样本,通常种子人群的数量不会很多,因此Lookalike通常是正样本比例非常少的class imblance问题。 在一个大规模数据集(4亿样本,2千万个特征)上的Lookalike问题的模型训练中,我们对比了Fregata LR和MLLib LR的性能。

从图4中可以看到Fregata的LR算法扫描一次数据即收敛达到AUC(测试集上)的最高值0.93。在这个数据样本中 而MLLib的LR算法,即使我们通过调参选取了最好的AUC结果,其AUC也仅为0.55左右。模型预测精度差别非常大。另外,MLLib的训练时间(达到最高精度的时间)也是Fregata大的6倍以上。
在公开数据集eplison[9]上(40万训练集,2000特征), Fregata LR无论从收敛速度还是模型效果与MLLib LR相比也有较大的优势。从图5中可以看到,在这个数据集上Fregata LR在迭代一次以后就在测试集上非常接近最好的结果了,而MLLib LR需要5次迭代而且最高的精度比Fregata LR相差很大,而训练时间MLLib LR也是Fregata LR的5倍以上。
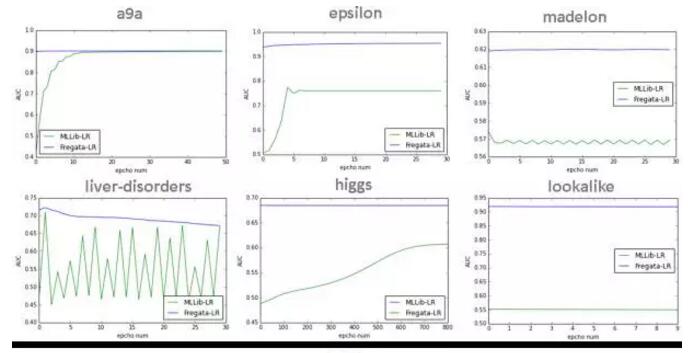
另外图6展示了Fregata LR与MLLib LR在6个不同问题上的测试集AUC曲线,可以看到Fregata LR算法在不同问题上收敛速度和稳定性相较于MLLib LR都是有较大的优势。Fregata LR在第一次迭代后,AUC就已经基本收敛,即使与最高值还有一些差距,但是也是非常接近了。
我们也在公开数据集MNIST上测试了Softmax算法。 从图7中可以看到, Fregata Softmax也是一次扫描数据后在测试集上的AUC就非常接近最好的结果, 而MLLib Softmax需要扫描数据多达40多次以后才接近Fregata Softmax一次扫描数据的结果。对比两个算法在达到各自最优结果所花的时间,MLLib Softmax是Fregata Softmax的50倍以上。

六. Fregata的使用简介
前面简要介绍了Fregata算法库涉及到的一些技术原理和性能对比,我们再来看看Fregata的使用方式。可以通过3种不同的方式来获取Fregata如果使用Maven来管理工程,则可以通过添加如下代码在pom.xml中进行引入,
<dependency>
<groupId>com.talkingdata.fregata</groupId>
<artifactId>core</artifactId>
<version>0.0.1</version>
</dependency>
<dependency>
<groupId>com.talkingdata.fregata</groupId>
<artifactId>spark</artifactId>
<version>0.0.1</version>
</dependency>
如果使用SBT来管理工程,则可以通过如下代码在build.sbt中进行引入,
// 如果手动部署到本地maven仓库,请将下行注释打开
// resolvers += Resolver.mavenLocal
libraryDependencies += "com.talkingdata.fregata" % "core" % "0.0.1"
libraryDependencies += "com.talkingdata.fregata" % "spark" % "0.0.1"
如果希望手动部署到本地maven仓库,可以通过在命令中执行如下命令来完成:
git clone https://github.com/TalkingData/Fregata.git cd Fregata mvn clean package install
接下来,让我们以Logistic Regression为例来看看如何快速使用Fregata完成分类任务:
1.引入所需包
import fregata.spark.data.LibSvmReader
import fregata.spark.metrics.classification.{AreaUnderRoc, Accuracy}
import fregata.spark.model.classification.LogisticRegression
import org.apache.spark.{SparkConf, SparkContext}
2. 通过Fregata的LibSvmReader接口加载训练及测试数据集,训练及测试数据集为标准LibSvm格式,可参照[10]
val (_, trainData) = LibSvmReader.read(sc, trainPath, numFeatures.toInt)
val (_, testData) = LibSvmReader.read(sc, testPath, numFeatures.toInt)
3. 针对训练样本训练Logsitic Regression 模型
val model = LogisticRegression.run(trainData)
4. 基于已经训练完毕的模型对测试样本进行预测
val pd = model.classPredict(testData)
5. 通过Fregata内置指标评价模型效果
val auc = AreaUnderRoc.of( pd.map{
case ((x,l),(p,c)) =>
p -> l
})
在Fregata中,使用breeze.linalg.Vector[Double]来存储一个样本的特征,如果数据格式已经是LibSvm,则只需通过Fregata内部的接口LibSvmReader.read(…)来加载即可。否则,可以采用如下的方法将代表实例的一组数据封装成breeze.linalg.Vector[Double]即可放入模型中进行训练及测试。
// indices Array类型,下标从0开始,保存不为0的数据下标
// values Array类型, 保存相应于indices中对应下标的数据值
// length Int类型,为样本总特征数
// label Double类型,为样本的标签。如果是测试数据,则不需该字段
sc.textFile(input).map{
val indicies = ...
val values = ...
val label = ...
...
(new SparseVector(indices, values, length).asInstanceOf[Vector], asNum(label))
}
七. Freagata的发展目标
Fregata目前集成的算法还不多,未来还会继续扩充更多的高效的大规模机器学习算法。Fregata项目追求的目标有3个:轻量级,高性能,易使用。
轻量级是指Fregata将尽可能在标准Spark版本上实现算法,不另外搭建计算系统,使得Fregata能够非常容易的在标准Spark版本上使用。虽然Spark有一些固有的限制,比如对模型规模的限制,但是作为目前大数据处理的基础工具,Fregata对其的支持能够大大降低大规模机器学习的应用门槛。毕竟另外搭建一套专用大规模机器学习计算平台,并整合到整个大数据处理平台和流程中,其成本和复杂性也是不可忽视的。
高性能就是坚持高精度和高效率并举的目标,尽可能从算法上和工程实现上将算法的精度和效率推到极致,使得大规模机器学习算法从笨重的牛刀变成轻快的匕首。目前对Fregata一个比较大的限制就是模型规模的问题,这是基于Spark天生带来的劣势。未来会采用一些模型压缩的方法来缓解这个问题。
易使用也是Fregata追求的一个目标,其中最重要的一点就是降低调参的难度。目前的三个算法中有两个是免调参的,另一个也是相对来说调参比较友好的算法。降低了调参的难度,甚至是免去了调参的问题,将大大降低模型应用的难度和成本,提高工作效率。
另一方面我们也会考虑某些常用场景下的特殊需求,比如LR算法的特征交叉需求。虽然通用的LR算法效率已经很高,但是对于特征交叉这种常见需求,如果不把特征交叉这个过程耦合到算法中去,就需要预先将特征交叉好,这会带来巨大的IO开销。而算法实现了对特征交叉的支持,就规避了这个效率瓶颈。未来在集成更多的算法的同时,也会考虑各种常用的场景需要特殊处理的方式。
Fregata项目名称的中文是军舰鸟,TalkingData的开源项目命名都是用的鸟名,而军舰鸟是世界上飞得最快的鸟,最高时速达到418km/小时,体重最大1.5公斤,而翼展能够达到2.3米,在全球分布也很广泛。我们希望Fregata项目能够像军舰鸟一样,体量轻盈,但是能够支持大规模,高效的机器学习,而且具有很强的适用性。目前Fregata还是只雏鸟, 期望未来能够成长为一只展翅翱翔的猛禽。
引用
- Cheng T. Chu, Sang K. Kim, Yi A. Lin, Yuanyuan Yu, Gary R. Bradski, Andrew Y. Ng, Kunle Olukotun, Map-Reduce for Machine Learning on Multicore, NIPS, 2006.
- https://www.zhihu.com/question/48282030
- https://github.com/TalkingData/Fregata
- http://arxiv.org/abs/1611.03608
- http://www.ibm.com/developerworks/cn/analytics/library/ba-1603-random-decisiontree-algorithm-1/index.html
- http://www.ibm.com/developerworks/cn/analytics/library/ba-1603-random-decisiontree-algorithm-2/index.html
- Rosenblatt J D, Nadler B. On the optimality of averaging in distributed statistical learning[J]. Information and Inference, 2016: iaw013 MLA
- https://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/binary.html#epsilon
- https://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/
作者介绍
张夏天:TalkingData首席数据科学家,12年大规模机器学习和数据挖掘经验,对推荐系统、计算广告、大规模机器学习算法并行化、流式机器学习算法有很深的造诣;在国际顶级会议和期刊上发表论文12篇,申请专利9项;前IBM CRL、腾讯、华为诺亚方舟实验室数据科学家;KDD2015、DSS2016国际会议主题演讲;机器学习开源项目Dice创始人。
感谢杜小芳对本文的审校。
给InfoQ中文站投稿或者参与内容翻译工作,请邮件至editors@cn.infoq.com。也欢迎大家通过新浪微博(@InfoQ,@丁晓昀),微信(微信号: InfoQChina )关注我们。
正文到此结束
- 本文标签: 实例 微博 core IO Hadoop 数据 注释 DOM 开源 src 高通 测试 突破 UI 时间 parse 总结 lib ORM 翻译 https map 需求 HTML dependencies dist 数据科学 服务器 git 集群 代码 参数 build Features apache ip cat GitHub CTO 快的 自适应 2015 pom 互联网 管理 CEO value Developer 数据挖掘 id maven 压力 大数据 创始人 XML 同步 http 希望 IBM 广告 开源项目 设计模式
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

