一致性hash原理
一致性hash最常见的应用情形就是缓存,其实只要涉及到hash和多台主机请求路由的情况,都可能涉及到一致性hash问题。一致性hash主要是考虑到集群中节点挂掉或新增节点的时候,要对已有节点的影响降到最小,传统hash值取余方式肯定不能满足这个要求,交换节点位置影响还有限,但是新增节点、删除节点会让绝大多数的缓存失效,除了导致性能骤降外很有可能会压垮后台服务器。对于日常使用的情况,节点挂掉算是小概率事件,但是对于像Amazon Dynamo这种规模的分布式集群来说,节点挂掉是必然事件——甚至每天都会有集群中的主机或者硬盘出问题。
一致性hash的解决思路,就是对缓存的object和Node使用同一个hash函数(实际不需要完全一致,但至少保证产生的hash空间相同),让他们映射到同一个hash空间中去,当然这很容易实现,因为大多数的hash函数都是返回uint32类型,其空间即为1~$2^{32}$-1。然后各个Node就将整个hash空间分割成多个interval空间,然后对于每个缓存对象object,都按照顺时针方向遇到的第一个Node负责缓存它。通过这种方法,在新增加Node和删除Node的时候,只会对顺时针方向遇到的第一个Node负责的空间造成影响,其余的空间都仍然有效。
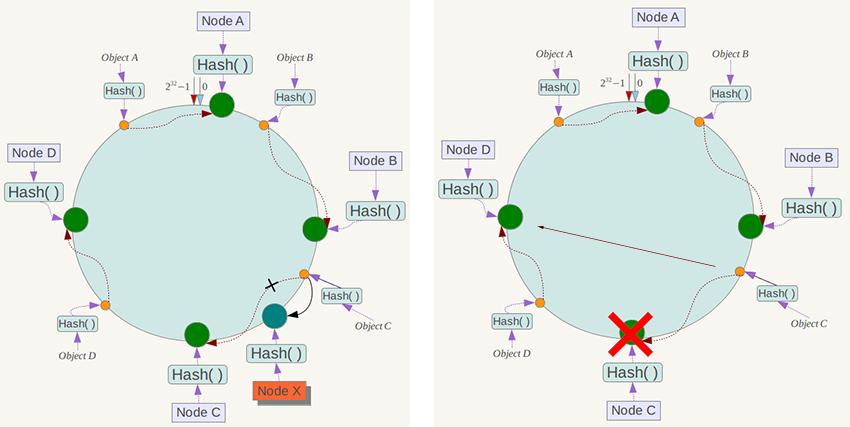
假设有Object A、Object B、Object C、Object D四个对象,以及Node A、Node B、Node C、Node D四个节点。根据上面的一致性hash原理,如果Node C挂掉了,那么Node C掌管的区域(包括Object C)都将会由Node D所接管;而如果增加节点Node X,那么原先Node C掌管的空间将会被分割,导致Node X之前的对象Object C由Node X所接管;针对节点之间交换顺序的情况,也可以预见也只有交换的那两个节点对应的区间会被影响。
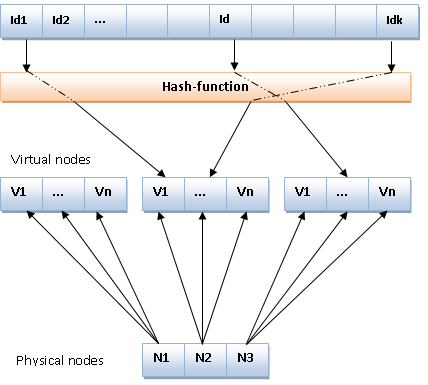
当然,上图各个节点的均匀分布是理想状态,实践中通常采用节点的IP地址或者主机名来计算hash值,在整个hash空间不太可能分布的这么均匀,而且即使当前比较均匀的话后面也会由于增加和删除节点打破这种状态。因为通常Node数目不会非常大,导致这种分布不会很均匀,所以采用虚拟节点(virtual nodes)的技术来增加节点的数目,这些虚拟节点再由底层实体Node来承载,当虚拟节点足够多的时候,他们趋向于将整个hash空间均匀成各个区间了。
MySQL的文档指出一致性hash算法有Ketama和Wheel两种,但是后者Wheel算法的相关资料没有找到。因为Memcached的服务端是设计成单机模式的,如果需要达到多节点协同的效果,就必须在客户端支持负载均衡和一致性hash算法。目前开源流传的主要是last.fm实现的 libketama ,作者声称已经在Last.fm的生产环境稳定运行十几年,用C语言实现,而且提供了各种语言的接口,不过这个项目貌似也开始长草了,作者正在寻找maintainer。
这个库十分的小,代码没有多少。同时在作者的博客也给出了具体的实现步骤:
a. 确定主机列表,比如 1.2.3.4:11211, 5.6.7.8:11211, 9.8.7.6:11211;
b. 对上面的每个主机”ip:port-%d”字符串计算MD5散列值,因为每个MD5是128位,所以可以产生4个unsigned int散列值,每个主机循环40次,即每个主机产生160个虚拟节点,这里每个虚拟机点都保存了实体节点的地址,可以直接取出给客户端访问使用;
c. 把这些散列值进行排序,然后想象它们分布在0~$2^{32}$-1的散列空间中去;
d. 当存取一个key的时候,先计算出unsigned int的散列值,然后通过二分查找的方式,快速定位到满足条件的虚节点,并从中取出响应的物理节点的地址信息;
e. 关于节点的添加和删除,我查看到估计只有ketama_roll这个函数相关,其会判断文件修改时间戳,如果修改了就使用信号量锁住系统,然后重新读取配置重新建立虚拟节点。因为虚拟机点的建立方式是固定规则的,所以对于那些没有修改的主机,其得到的虚拟节点仍然存在,hash一致性得到维持。
从上面的描述看来,一致性hash的原理和实现其实还是挺简单明了的。此外,还需要提到无意中观察到的一个案例,就是Google在其Maglev系统中,并没有直接采用通常的一致性hash解决方案,而是改进成了一个Maglev hashing。因为对于一致性hash,通常考量的有两个方面:
a. load balancing: 对于backend group中的节点,他们所承担的负载应该是大致均匀的;
b. minimal disruption: 当backend group中的节点发生增删变化时候,没有变化的节点应当受到最小的影响。
虽然通过虚拟节点和hash盘的手段,上面的两个需求都可以得到一定的满足,但是Google的这个Maglev系统后台会有上千台的服务器集群,所以对负载均衡和最小扰动需求要高的多:要想负载均衡就需要添加更多的虚拟节点以平均单个物理节点的影响,虚拟节点数目增加后会对查找key到虚拟节点映射操作负担增加。
Maglev hashing的最主要步骤,就是以不同的方式产生每个entry(其实这个entry也有虚拟节点等价的意义)的lookup table。假设backend的节点数目为N,entry的条目数为M(通常M为大于100×N的质数),使用两个hash函数h1、h2计算产生offset和skip,首先第一步初始化得到permutation表。
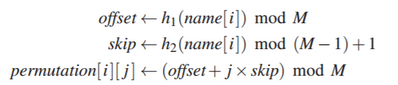
上图是假设h1和h2计算得到的三个backend的(offset, skip)分别为(3,4)、(0,2)、(3,1)情况下所产生的结果,原文中算法伪代码写的十分详细了,可以轻易进行工程化实现。通过permutation表,就可以得到entry和backend节点的映射关系lookup table,不过生成lookup table的步骤原文没有说,看了半天是这个意思:首先产生长度为N的数组,然后把permutation表按照从左到右、从上到下的顺序遍历,如果发现该数字代表的entry还没有backend节点就将其所在的节点填进去,如果已经有了就直接跳过,直到lookup table填满了完成。
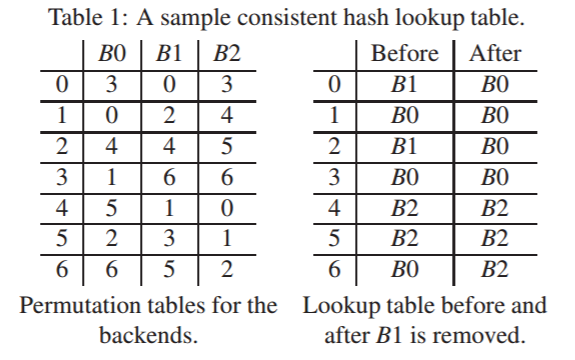
从上图中可以看出,原始生成的lookup table中三个节点的分别比较均匀,而如果将B1节点移除,新生成的lookup table中剩余的B0、B2节点分配还是比较均匀的,而且改动的条目都是原始B1节点的entry,而B0和B2的条目都没有更改。在后文的测试中也发现,当在1000台backend节点下以0%~2.5%的比例并发撤出节点模式故障的情况下,查找表的改动率相比传统一致性hash比率也是相当低的,而且在有限entry数目下各个节点的负载均衡也得到了保证。
本文完!
参考
- Dynamo: Amazon’s Highly Available Key-value Store
- The Simple Magic of Consistent Hashing
- Programmer’s Toolbox Part 3: Consistent Hashing
- libketama: Consistent Hashing library for memcached clients
- GitHub ketama
- Consistent Hashing
- Maglev: A Fast and Reliable Software Network Load Balancer
- [Maglev : A Fast and Reliable Software Network Load Balancer] ( https://www.evanlin.com/maglev/ )
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

