监控系统故障定位之事件关联分析的设计
介绍
作者介绍
本文作者是 吴城 联系方式: autohomeops@autohome.com.cn ,主要负责汽车之家云平台的开发和技术管理工作。 个人Blog http://jackywu.github.io/

团队介绍
我们是汽车之家运维团队,是汽车之家技术部里最为核心的团队,由op和dev共同组成。我们的目标是为汽车之家集团打造一个高性能,高可扩展,低成本,并且稳定可靠的网站基础设施平台。 团队技术博客地址为 http://autohomeops.corpautohome.com

联系方式
可以通过邮件或者在官方技术博客留言跟我们交流。
一、前言
在《汽车之家监控系统的第一次里程碑》](http://autohomeops.corpautohome.com/articles/汽车之家监控系统的第一次里程碑/)之后,我们实现了如下几个小Feature
- URL监控
- 日志监控,并且在告警信息中带上错误日志片段
而后,我们又希望能够实现所谓的“自动故障定位”,来提升问题诊断的效率。
二、思路
我们认为,一个异常问题的发生,必定是有一个或者多个原因导致的,我们用“事件(Event)”来描述这个异常。网站的QPS增大超预期是一个事件,后端接口响应时间变大超预期是一个事件,服务器的CPU-Load增大超预期是一个事件,有人对MySQL服务器进行了配置变更是一个事件,有人进行了一次业务代码发布也是一个事件,找出这些事件之间的关系是实现故障定位的关键。
我们理解有两种故障定位的方法
- 事件关联分析
- 决策树自动推理
我们目前在实践第一种方法。
三、方案
监控指标分类
为了方便进行分析定位,我们对所有采集的监控指标进行了分类

解释
- 业务层:该层指标反映出Service的质量,如一个订单系统的下单成功率
- 应用层:该层指标反映出应用软件的运行状态,如Nginx连接数
- 系统层:该层指标反映出操作系统的运行状态,如平均负载
- 硬件层:该层指标反映出硬件设备的运行状态,如CPU温度
通过分层,我们将问题分类在我们熟知的范围内。
建立服务树模型
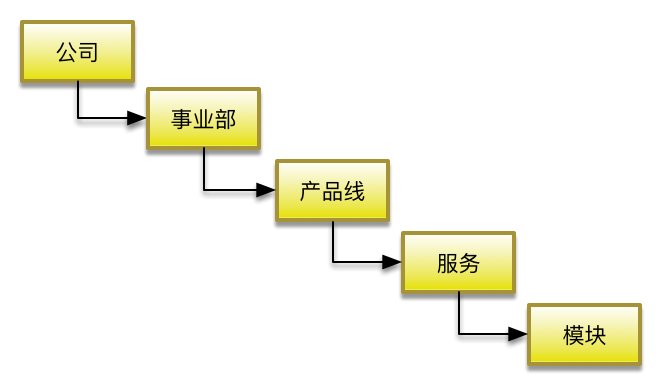
重点是:“服务” 和 “模块”
- 模块:提供某种功能的服务器的组合,属于同一个模块中的服务器功能一样。如“缓存模块“,”DB模块“。
- 服务:由多个模块组织在一起提供一种Service,“服务”是对“功能”的一个更高层的抽象。如”订单拆分服务“。
这两个概念的定义,为下面的模块调用关系奠定了基础。
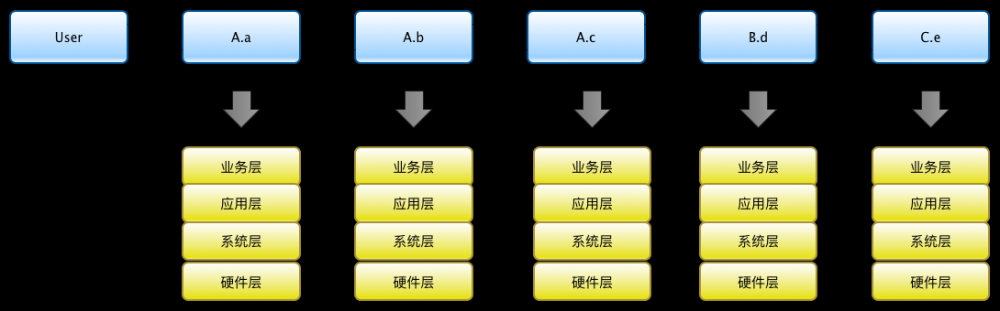
建立模块调用关系
大写字母代表”服务“,如A服务;小写字母代表”模块“,如a模块;箭头代表调用或者结果返回关系
建立”统一事件库“
我们认为有如下几种确定事件之间关系的方法
- 上面的模块调用关系是一种人为定义的确定性关系。
- 时间相关性,这是一种非确定性的策略,代表了一种相关可能性。
- 事实相关性,通过对大批量历史数据进行分析计算,找到事件之间事实上发生的相关性。
那么,首先我们得需要一个统一的“事件库”来收集所有事件。
我们认为形成事件的来源有这么几个
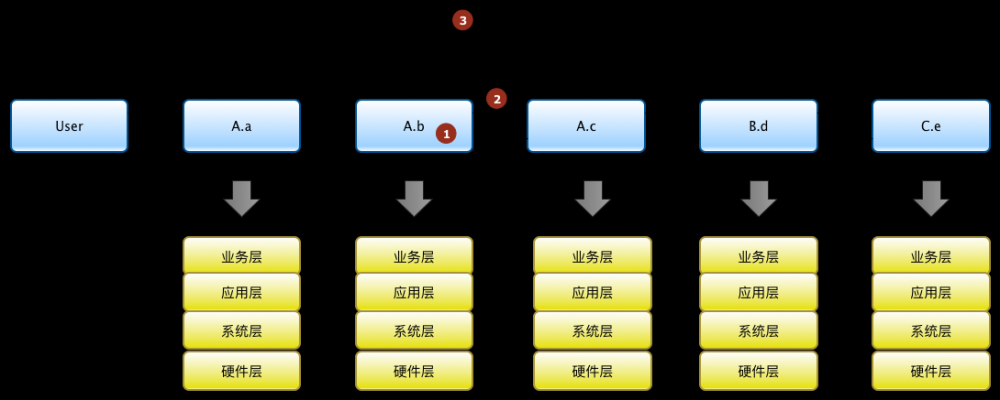
我们认为一个对象产生异常的影响因素来自于这几个方面
- 自身异常,如硬盘损坏
- 依赖方异常,如A.b调用了A.c的服务,然而A.c服务异常
- 来自外部的对其产生的变更,如开发者对A.b服务进行了代码升级,该服务器所在交换机故障,局方机房网络割接
对于第一点,我们只要将自身的4层指标监控完整,就能够做到可控的程度。 对于第二点,需要我们完整确定每个模块的调用关系。 对于第三点,是我们尤其担心的一点,因为我们很难收集全所有的外部事件,我们使用了如下的方法来尽量实现这个目标。
- 建立“通告中心”,让人为已知的确定性变更通过这个方式发送出来,并且记录到事件库中。例如对A.b服务进行代码升级。
- 通过消息队列的Pub/Sub模型建立一个公共的事件总线,让平台里的每个系统都能够将自己产生的重要变更通过这种松耦合的方式对外发布,对该系统的变更感兴趣的其他系统就可以有选择地抓取,如监控系统可以抓取写入事件库。
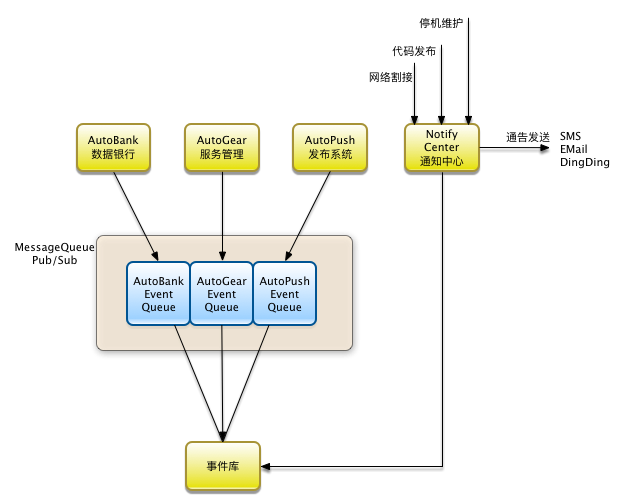
对于事件总线这块,我们这几个系统的是这样工作的
- AutoBank(资源管理系统)会将设备(服务器、交换机等)的状态变化,附加上工单,作为一个事件记录到自己的日志中,同时发布到事件总线里。我在 2016 opsworld - 运维的数据银行 的分享中有提到,状态的变化意味着有变更流程,有变更就有产生风险的可能。
- AutoGear(服务管理系统)会直接对服务器上的软件环境产生变更,所以会将哪台服务器上安装了什么软件,或者对什么软件的参数进行了怎么样的修改封装成一个事件记录到自己的日志中,同时发布到事件总线里。
- AutoPush(代码发布系统)会在流程上强制要求代码上线人必须先通过“通告中心”发布”上线通告“,这条通告会通过钉钉、邮件或者短信发送给相关人,也会录入事件库,然后AutoPush会尝试读取这条发布通告,读到了才开启发布窗口,发布人才能够在页面上进行代码发布。发布窗口期过期后,自动锁定AutoPush禁止发布。
故障原因定位策略
我们目前使用的策略
- 调用链越尾端的模块,越有可能是故障根本原因。
- 监控指标中越下层的,越有可能是故障根本原因。
根据“模块调用关系”和“指标分层”的概念,采用递归的方法去遍历所有事件,得到一个疑似故障原因诊断报告。
范例如下
“广告服务”的接口响应时间异常(为3s),疑似原因为“索引模块”的服务器xxx.autohome.cc磁盘util异常(为98%)。
保留问题现场
业务层指标是直接反应出服务质量的,是最能代表用户体验的,所以在业务层指标异常发生的时候,我们通过SaltStack这个远程执行通道在服务器上执行snapshot脚本保存当前服务器的运行状态快照,该脚本其实是平时运维在发现问题后登陆服务器上执行常规命令的一个标准化封装,所做的事情有:
- 保存uptime指令输出
- 保存CPU占用top10
- 保存free指令输出
- 保存内存占用top10
- 保存df指令输出
- 保存
ip addr show指令输出 - 保存路由表
- 保存Local DNS
- 保存
Dig autohome.com.cn指令输出 - 保存
Ping -c 3 autohome.com.cn输出 - 保存TCPDUMP抓包10秒的结果
- 等等
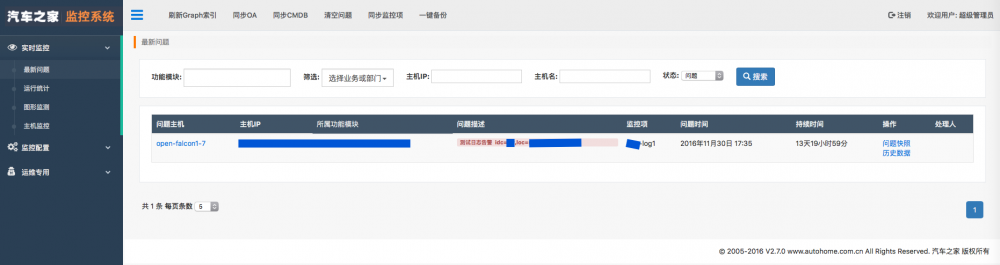
同时,在监控系统的“最新问题”页面,点击“现场快照”,上面的信息会直接呈现在页面上,并且点击“历史数据”,页面上会显示问题发生时刻前后30分钟的历史数据曲线,包括CPU,内存,硬盘,IO,网络流量,等等,方便运维快速定位问题。
日志追踪
通过ELK构建日志分析系统,在如下两个方面满足故障定位的需求
- 搜索服务器A某个时间段内的B应用程序的日志,通过上文“最新问题”页面可以直接跳转过来。
- 通过TraceID搜索单个用户请求的全流程。
四、小结
监控系统的建设真是个任重道远的活,上文只是部分实现了事件关联分析的内容,下一步我们计划在“决策推理”方面进行研发,以提高定位的精准度,为后续的故障自愈打下基础。文中有任何不妥之处,欢迎大家指出。
正文到此结束
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

