Amazon Dynamo论文学习笔记
其实个人一直比较喜欢读Google、Amazon、Facebook这类科技公司工程化的paper,一方面是这类文章通常不会夹杂着让人看着眼花缭乱的数学公式(而且很多文章往往很简单的道理也会被装饰的神神叨叨滴);二来这些系统用到的技术都比较的大众成熟,可以很容易的在网上搜到相关资料,让你在短短时间就知道大概是个什么意思;还有最主要的是这些论文是进行实实在在工程化并用于生产环境了,方案可行性自然不用多说,在实现的过程中遇到的各种现实、细节问题也是很值得学习揣摩和借鉴的。比如,接下来要说的 《Dynamo: Amazon’s Highly Available Key-value Store》 这篇论文要算是分布式系统设计实现中的必读经典了,虽然该套系统没有开源,而且由于商业机密部分内容没能够详细阐述,但丝毫没有影响到它对分布式系统设计实现的重要指导作用。

一、前言
Amazon Dynamo系统的设计和实现从最开始就比较的实用主义:首先Amazon作为全球最领先的电商企业,其丰富的经验让其可以洞悉到绝大多数互联网公司的需求点和关切点,其次Dynamo是作为服务出售的,所以其并没有设计实现成一个至臻完美的分布式存储模型,它只支持K-V非关系型键值存储,就像是一个巨大的dict/map结构,只支持get()、put()两种简单访问方式,优化成高可写入性要求,存储的对象尺寸大多小于1M,成本考虑上支持99.9%级别的可用性(百毫秒读写响应),但依据Amazon在云计算领域的强大实力,该系统在性能、可靠性、效能、伸缩性等方面没有丝毫的妥协。
和绝大多数分布式系统一样,Dynamo使用最终一致性获取性能从而保证可用性的,然后通过现有各项成熟的技术手段解决项目中的各种问题:数据使用一致性hashing进行分区,同时提供数据副本保证安全;通过NWR和对象vector lock版本机制有限的解决冲突并实现最终一致性;Merkle tree数据结构可以实现节点间数据的高效同步;整个系统完全去中心化,采用Gossip协议实现成员变更的同步。
二、背景知识
2.1 系统假设和设计需求
a. 访问模式:数据项通过key唯一确定,且只提供读、写两个操作接口,对象采用二进制方式存储。这种K-V的存储符合绝大多数互联网海量对象的存储需求,对象的读取写入只支持单个对象的操作,任何多对象、关系性的操作都不支持;
b. ACID:就是分布式系统中的原子性、一致性、隔离性和持久性,强一致性模型虽然实现简单,但是可用性的最大杀手,所以该系统只提供最终一致性保证;同时也不支持隔离性,只提供单个元素的更新操作。
c. 有效性:服务必须提供稳定可靠的延时和吞吐量,根据在性能、价格、可用性和持久化各个因素的考量和妥协中,提供99.9%的可访问性;
由于在内部使用,所以不用考虑授权、鉴权操作,整个假设在一个可信环境的内网中执行的,不考虑拜占庭通信模型。
2.2 设计考虑的问题
在商业系统领域,传统方式都是采用强一致性的数据访问,数据会在各个节点之间进行同步,在数据不确定是否正确的情况下通常设置该数据将是不可用的状态。这种模型虽然从编程角度很容易实现,但是这种情况下一旦出现问题(比如脑裂),整个系统的可用性就必然会受到影响甚至处于不可用状态。
对于易于出现主机和网络系统的情况,可以通过优化同步操作来提高系统的可用性,比如后台异步化、并行传输,只要实现最终一致性就可以,但是异步化之后很容易导致修改和访问冲突和失败的情况,这时就需要确定何时、何人负责解决冲突问题(背锅问题)了,针对这个问题:
a. 很多传统的系统是在写阶段解决冲突和失败,这样读的时候操作会很简单,而如果比如因为冲突而不能顺利写入,写入操作就会被驳回返回失败。而Dynamo设计就是最强的可写入性,比如文中反复出现的购物车情形,即使网络不可用的情况下也不会驳回客户的请求,否则会很影响用户体验,为了保证这样高的可写入性,就必须在读阶段承担起这个解决冲突和失败的任务。
b. 解决冲突的角色可以是数据中心也可以是用户应用程序,前者是自动化解决冲突,通常只能用简单的机制来解决,比如“使用最新写入值(last write win)”,而用户程序处理会更加的灵活,比如多个版本共同求交集结果等方式。
除此之外,Dynamo还需要考虑:系统的高伸缩性;节点的对称性,所有的节点都一视同仁;去中心化,采用P2P的发现和同步技术,这一直是分布式系统追求的目标(比如避免单点故障)。
三、系统架构
系统的工程化会涉及到相当多的细节,比如:数据持久性存储、可伸缩性、负载均衡、成员管理和错误探测、错误恢复、复制备份同步、过载处理、状态迁移、并发和任务调度、请求安排、请求路由、系统监测和报警、配置管理。篇幅限制,这篇论文没有对上面所有内容都展开论述。
3.1 系统接口
Dynamo的数据类型是K-V,只支持最简单的get()和put()读和更新接口。Dynamo的底层会将key进行MD5 hash处理得到128bit的索引值,通过其确定底层实际的存储节点。
get(key); put(key, context, object);
get(key)正常情况下会返回key锁关联的object,而如果发生冲突(且底层无法解决冲突)的话,会返回一个列表,包含各个冲突的版本和context信息,用户可以用自己的机制解决这些冲突,并将结果写回更新成最新版本;put(key, context, object)会进行存储更新操作,其context参数通常是之前get读返回的。
3.2 分区算法
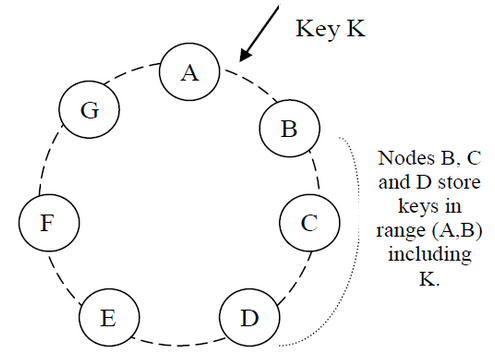
对于节点出错和删除,以及添加节点的时候,必须采用一致性hashing的方式保证对其他节点最小影响。一致性hashing的知识在《一致性hash原理》已经详细描述过了,主要也是基于hash环分区的方式实现的,而且相似地,为了让存储节点均匀分布、实现负载均衡,采用了虚拟节点的改进方式,这样不仅在平常访问的时候,而且在增加和删除节点的时候,都会将影像平均分布到其他节点上去,而不会对少数节点造成加大影响。
3.3 副本
因为Dynamo实现的是存储系统,而不是前面介绍到的缓存系统,所以为了数据的安全必须使用产生多副本(Replication)机制。Dynamo会让每个数据产生N个副本,关于这些副本的分布,是用到前面通过一致性hash根据key计算出该数据属于哪个虚节点,然后沿着顺时针的方向在接下来的N-1个节点上产生该数据的额外副本。
上面负责存储key的节点和副本节点共同组成了preference list列表。考虑到有些节点会出错不能访问的情况,这个列表的长度通常会大于N。而且在使用了虚拟节点机制后,物理节点会在hash环中出现多次,所以如果不加挑选的话,很有可能N个虚拟节点会映射到底层少于N个实际的物理存储节点上,显然这样的话单个物理节点可能会出现多个虚拟节点副本的丢失,所以系统在选择节点组成preference list的时候,都是采用跳跃的方式,确保列表中保存的都是物理节点各不相同的虚拟节点。
3.4 数据版本机制
Dynamo只保证最终一致性,采用异步的机制进行读写操作。
Dynamo采用vector clocks的机制,vector clock记录了某节点对该key更改的版本记录,是一个(node, counter)的结构,那么所有节点对该对象的修改将可以组成一个vector clock的列表。系统可以根据检查两个节点上某个对象的vector clock列表,而判断该对象在各节点上的副本,是序列化的因果关系还是并行分支的关系:如果是前者(大多数正常情况),系统就可以自动进行语法冲突合并(syntactic reconciliation),新版本的数据覆盖旧版本的数据;后者冲突情况则需要返回包含所有冲突版本等信息的context,然后由client端负责解决这个冲突,并最后用context更新写会最新结果,称为语义冲突合并(semantic reconciliation)。
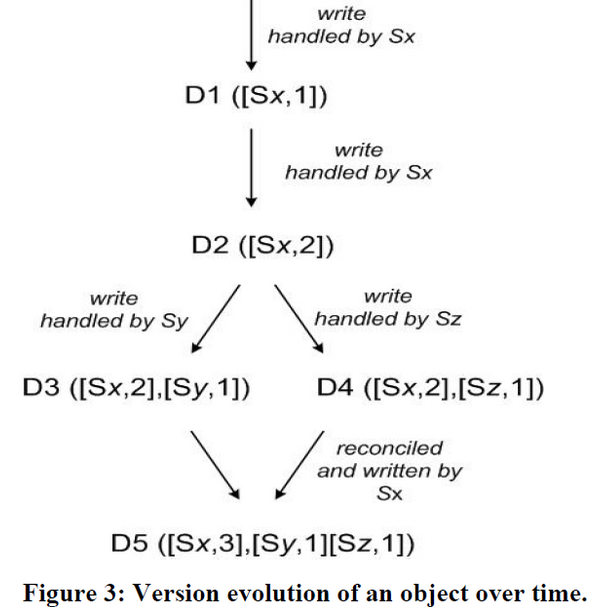
比如上图的过程,D1[(Sx, 1)]、D2[(Sx, 2)]都是由同一个节点X做的修改,所以不可能产生版本冲突,而当因为节点出错、前端负载均衡等因素影响,后面的更新都基于D2但发生在了Y、Z两个节点上,接下来客户读取的时候会发现D3、D4之间没有因果关系,因此将所有结果都罗列返回给客户端,client负责合并后并通过X节点更新写入,且相应地增加Sx的版本号。
看到这里可能会想到,如果所有的写请求都发向某个固定的节点,难么版本冲突的概率不就会大大降低了么?如果该节点一直可用,那么这种序列化的修改肯定是可以大大降低冲突的概率的,但是论文指出这样的操作负载是不均衡的,那么不均衡的节点请求会导致可用性降低。实际上,通常的写都是紧跟在读操作之后(难道是必须的?put需要一个context啊),通常写会发送到读响应最快的那个节点上面去,这样的优化就可以保证较好的写入性能,同时也间接实现了”READ-YOUR-WRITE”这读己之所写级别的一致性。
如果记录每个节点的更新版本的话,通常情况不会产生问题,因为更新都是在preference list的前N个节点,但是在发生脑裂或某些节点出错后,后续节点会依次代替不可用节点响应写入请求,那么这个vector clock列表长度必然会不断增加。为了防止这种情况,实践中的vector clock会加上时间戳以记录该节点最后修改的时间,当vector list列表的长度超过固定长度(比如10)的时候,将时间戳最旧的节点版本信息剔除出去。
3.5 get()和put()操作
用户的请求都是在HTTP层之上发起的,将用户请求分派到特定节点,分派的方式有两种:
a. 通用的负载均衡分配,这时分配是通用的基于后端节点的负载信息确定的;
b. 通过将客户端链接上节点发现(partition-aware)程序库,那么客户端就知道分布式节点的信息,请求会直接瞄准到对应的节点上面去。
两者各有优缺点,第一种方式应用程序不用链接额外的库,第二种方式更加的高效,会跳过一些无畏的请求转发,所以大多情况下请求会有更小的延迟。
通过客户端方式定位节点,客户端会以10s周期性的随机从一个节点下载集群的节点成员列表(这个列表是通过Gossip协议方式同步,并保证所有节点最终一致性的),有了这些信息客户端就直接可以向目标节点发送请求,而不会产生一次可能的请求转发了。这里成员列表更新是客户端主动pull模式,而不是节点主动push模式,很显然前者模型更简单方便,但是可能得到的列表是旧的,此时客户端如果请求失败的话,会立即请求刷新成员列表。
通常的读写操作都会在preference list的前top-N节点上操作的,如果是以客户端链接节点发现库的方式,负载均衡可能会将请求随机分配到任意节点,如果分配的节点不在该key的preference list的top-N中,那么该请求会自动转发到top-N的第一个节点(任何节点本地都含有整个系统完整的成员列表)。这里所说的top-N节点都是指健康可用的节点,系统会自动跳过那些出错或者不可访问节点,使用排在后面的低rank节点替补上来。
Dynamo采用NWR的机制来维护多个节点上数据副本的一致性,R和W表示读、写请求最少完成节点数目就可以表示本次操作成功,因而读写请求的延迟由最后一个完成读写操作的节点所决定,配置上要求R+W>N就形成了一个Quorum的机制,而R/W两者相对大小也代表了这个系统读/写性能之间的权衡。所以对于put()请求,当接收到请求的那个节点首先产生新版本的vector clock,本且本地写入该更新值,同时将新版本的值连同新vector clock发送给top-N的其他节点,当最后一个第(W-1)节点完成写入后,该更新操作被认为成功;对于get()请求,收到请求的节点会向top-N的所有节点发送读请求,然后等待收到R个响应后,如果节点收到的R个请求中会有多个版本的数据且无法因果合并冲突,则返回所有版本,冲突合并后的数据会更新并写回节点上去,如果超时后还没返回R个响应,则会做出错处理。
3.6 出错处理:Hinted Handoff
Dynamo中的Quorum成员不是固定的。之前说道为了考虑节点会出错的情况,preference list的长度通常会大于N,而top-N通常都是在hash环中按照顺时针方向依次选取的N-1个在不同物理节点上的虚拟节点,当出现脑裂或者部分节点宕机、不可访问的时候,就会依序访问接下来preference list中的接下来的节点。
对于上图中,假设N=3且preference list成员依次包含A、B、C、D节点,此时节点A临时不可访问,那么发送到A的数据将会被发送给D,同时会在元数据中标明hint信息,指明这个消息本来是要发送给A节点的。当D收到带有hint消息的数据时候,会在本地单独开辟一个数据库用于存储该类信息,在代替A节点响应请求的同时,还会周期性的检查节点A是否已经恢复,如果恢复了将会把这些副本同步给A节点,然后D节点再把这些本地存储给删除掉。
现实中,可能因为供电、网络、制冷系统、自然灾害等因素导致整个数据中心挂掉,Dynamo会配置成每个key的preference list会夸数据中心存储,数据中心之间采用高速网络连接,以保证在单个数据中心无法访问的时候整个系统仍然可用。
3.7 永久出错处理:同步恢复
上面的情况主要用于临时性、短暂性的节点不可访问的情况,对于其他永久性出错的情况,Dynamo采用副本同步(replica synchronization)的机制来处理。
Dynamo使用了Merkle trees的方式,该数据结构是个hash tree,这种数据结构的叶子节点都是单独key对应value的hash值,而父节点都是子节点的hash值,这样的好处是两个父节点的hash值一致,那么就不用逐个比较他们的子树了。当比较两个根节点的hash值的时候如果不一致,就需要不断的交换比较子节点的hash值,一直查找到不相等的叶子节点从而查找到需要同步的key,然后同步更新之。虽然这样操作麻烦一些,但是不需要在节点之间同步整个树结构或者整个数据集,减少了传输量从而增加了同步效率。
在Dynamo中,每个节点都为其所承担的hash virtual node的key范围建立一个Merkle树,那么当任意两个节点存储了相同数据(副本)的时候,这两个节点交换root节点的hash值看两者是否是已同步的状态,如果不相同采用树遍历的方式检查到未同步的部分。麻烦的是,当新加入节点的生活,需要重新建立Merkle树结构。
3.8 成员管理和错误探测
3.8.1 Ring Membership
管理员可以通过命令行或者浏览器的方式连接到某个节点上面去,然后发送添加、删除节点的指令,接受处理请求的节点会把这个成员变更事件和时间记录固化下来,然后通过Gossip协议不断地传播这个事件(就是每个节点每秒会随机地选择peer节点,然后两者通信交换自己的本地的全局节点成员信息,并合更新并两者的成员列表),虽然没有具体时间的保证,但是Gossip协议会保证最后某个时间集群中,所有node都会就成员列表达成最终一致性。
当一个新的节点添加进来的时候,根据一致性hash和虚拟节点的原理,会产生多个虚拟节点和其hash space的对应关系(tokens),并固化到本地磁盘上面,虽然新加入的节点起始只含有自己的token信息,然后根据前面相同Gossip协议传播机制,最终所有节点都会在本地存储这种虚拟节点的分区信息,所以这种本地存储也使得任何一个节点都可以快速的将目的key的读写请求进行精准转发。
3.8.2 External Discovery
论文描述了逻辑分区的Dynamo环的情况,但是我想主要可能考虑新加入多个节点不能快速互相发现和传播吧。Dynamo会选择一些节点作为种子(seed)的角色,这些种子是通过配置或者其他服务方式产生的,对所有的节点都可见,那么新加入的节点就可以快速的和这些种子节点进行交互和同步,传播的效率大大提高了。
3.8.3 Failure Detection
错误检测主要是防止节点尝试和不能访问的节点进行交互,尽量避免通信失败的情况。其实只要B节点不响应A节点的消息,那么A节点就认为B节点出错了,此时A节点就会选择和B节点具有相同数据副本的节点发送请求,同时A节点还会周期性地探测B节点是否恢复可用了。
最初的Dynamo设计使用去中心化的方式,维护一个全局的最终一致性的节点失败状态信息,后来发现这种设计是多余的:通过前面的增加或者删除节点的操作,然后通过Gossip协议节点的存在性会达到最终一致性,而临时性的节点不可用直接根据请求是否响应就可以探测出来,候选的节点会自动接替之用于响应服务。
3.9 存储节点(物理节点)的添加和删除
当一个节点加入到hash环中的时候,比如节点X,考虑到上面的分区问题外,还会涉及到数据副本的问题,会有至多N个节点会和这个变动的hash区间相关联。在这个分区划分出来之后,一些节点不需要再负责这部分区域的keys的时候,会把这部分keys的数据传输到这个新加入的节点上来。
比如对于上面的图,当节点X加入到节点A-节点B中间的时候且N=3的时候,节点X就需要存储(F,G]、(G,A]、(A,X]区域的数据,而对应的节点B、C、D就不需要保存对应部分的数据副本,因此他们会将这部分数据传输给节点X。
四、后言
Dynamo的基本实现算是理解完了。说到这里,之前看到腾讯微信后台出了PaxosStore的分布式存储,用以替代之前的QuorumKV存储,而后者恰巧是基于NWR(N为3,W/R为2)协议实现的分布式存储系统。他们给出的最终测试结数据看来,QuorumKV和PaxosStore两者的性能(延迟)差距并不大,而是在请求失败率的指标上有较大的改进。
没有QuorumKV的实现细节,Dynamo和PaxosStore也没有过正面PK,所以这里也不好乱喷。只不过从原理上来说,NWR只是保证异步修改多个副本,协议本身并没有保证最终一致性,那么冲突肯定是更容易发生的;而Paxos协议在更新的时候就需要多个Acceptor进行表决,并达成最终一致性(如果此轮表决没有达成一致还会继续Propose再表决),这种情况下冲突的概率肯定是很低的,所以得到他们的测试结果也是情理之中的事情,毫无悬念。
Paxos的论文过于的理论,工业实现确实不容易,坑点很多。感觉Raft虽然添加了一些假设,但是将整个系统实现会方便一大截,有机会要好好拜读一下那篇著名的斯坦福博士论文,你懂得!
本文完!
参考
- Dynamo: Amazon’s Highly Available Key-value Store
- 微信PaxosStore内存云揭秘:十亿Paxos/分钟的挑战
- Consistency and availability in Amazon’s Dynamo
正文到此结束
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

