Docker构建Flink集群
Docker是在硬件资源不富裕的的情况下获得集群体验的一个非常不错的方式,本篇文章实现通过docker-compose编排Flink 高可用(HA)模式集群。集群构建两个JobManager和N个TaskManager,JobManager启动后向Zookeeper注册信息,并选举出leader,JobManager的数据备份保存在HDFS上;TaskManager从ZooKeeper上获取leader JobManager并发起注册请求。
镜像构建
镜像包括Flink、Hadoop、ZooKeeper。镜像Dockerfile整理在 Github 上,下面分别来看镜像的构建与配置,完整文件可以再 这里下载 :
Flink镜像构建
Flink镜像可以从DockerHub上直接pull下来也可以根据Dockerfile自己构建,这里通过Dockerfile来构建。进到docker-flink目录下:
docker-flink/ ├── build.sh ├── docker-compose.yml ├── docker-entrypoint.sh ├── Dockerfile ├── flink-conf.yaml
Dockerfile内容如下:
FROM java:8-jre-alpine # Install requirements RUN apk add --no-cache bash snappy # Configure Flink version ARG FLINK_VERSION=1.1.1 ARG HADOOP_VERSION=27 ARG SCALA_VERSION=2.11 # Flink environment variables ARG FLINK_INSTALL_PATH=/opt ENV FLINK_HOME $FLINK_INSTALL_PATH/flink ENV PATH $PATH:$FLINK_HOME/bin # Install build dependencies and flink ... ... # Configure container ADD flink-conf.yaml $FLINK_HOME/conf/flink-conf.yaml #USER flink ADD docker-entrypoint.sh $FLINK_HOME/bin/ ENTRYPOINT ["docker-entrypoint.sh"] CMD ["sh", "-c"]
这里Dockerfile首先指定基础镜像java:8-jre-alpine,指定Flink版本并下载Flink包。最后将flink-conf.yaml配置文件加到Flink的配置文件目录下,最后指定容器运行入口docker-entrypoint.sh。
由于这里构建高可用模式的Flink集群,需要对默认flink-conf.yaml进行修改:
# Common # The host on which the JobManager runs. Only used in non-high-availability jobmanager.rpc.address: localhost jobmanager.rpc.port: 6123 jobmanager.heap.mb: 256 taskmanager.heap.mb: 512 taskmanager.numberOfTaskSlots: 1 taskmanager.memory.preallocate: false parallelism.default: 1 # Streaming state checkpointing state.backend: filesystem state.backend.fs.checkpointdir: hdfs://hadoop:9000/flink-checkpoints # Master High Availability (required configuration) recovery.mode: zookeeper recovery.zookeeper.quorum: zookeeper:2181 recovery.zookeeper.storageDir: hdfs://hadoop:9000/recovery
配置文件中指定了HA模式集群的zookeeper服务地址,以及数据备份HDFS路径,其中zookeeper和hadoop再docker-compose.yml文件中指定的服务标识,在flink容器中可以将该表示看作对应容器的主机名。docker-compose.yml会在后面看到。
容器入口脚本docker-entrypoint.sh接收参数jobmanager或taskmanager分别启动不同服务,这里不再具体分析。
hadoop 和 zookeeper镜像构建
hadoop 和 zookeeper镜像构建使用已有的Dockerfile构建,如果需要定制化或者希望减小build的镜像大小,可以进行优化。用到的Dockerflie和构建方法整理在上面的链接里,这里不再拿出来分析。
Docker Compose编排集群
先来看docker-compose.yml:
version: "2"
services:
jobmanager:
image: flink
ports:
- "48085:8081"
expose:
- "6123"
command: jobmanager
depends_on:
- zookeeper
- hadoop
links:
- "zookeeper"
- "hadoop"
taskmanager:
image: flink
expose:
- "6121"
- "6122"
depends_on:
- jobmanager
- zookeeper
- hadoop
command: taskmanager
links:
- "jobmanager"
- "zookeeper"
- "hadoop"
zookeeper:
image: zookeeper
ports:
- "2181:2182"
expose:
- "2181"
hadoop:
image: sequenceiq/hadoop-docker:2.7.1
ports:
- "50070:50070"
- "8088:8088"
- "9000:9000"
- "8020:8020"
expose:
- "8020"
- "8042"
- "8088"
- "9000"
- "10020"
- "19888"
- "50010"
- "50020"
- "50070"
- "50075"
- "50090"
从yml文件中可以看到指定jobmanager和jobmanager2两个JobManager服务分别将web端口8081映射到宿主机的48085,48084端口,指定JobManager服务依赖hadoop和zookeeper并用links标签链接;taskmanager依赖zookeeper和jobmanager以及hadoop,同样与其连接。docker-compose.yml的镜像需要根据Dockerfile构建。
运行Flink集群
进入docker-flink目录,运行脚本构建flink镜像
sh build.sh
docker-compose启动flink集群,并查看容器启动是否正常:
docker-compose up -d docker-compose logs
系统默认启动1个JobManager和1个TaskManager,可以启动N个TaskManager
docker-compose scale taskmanager=N
查看集群启动情况
docker ps查看容器启动情况:
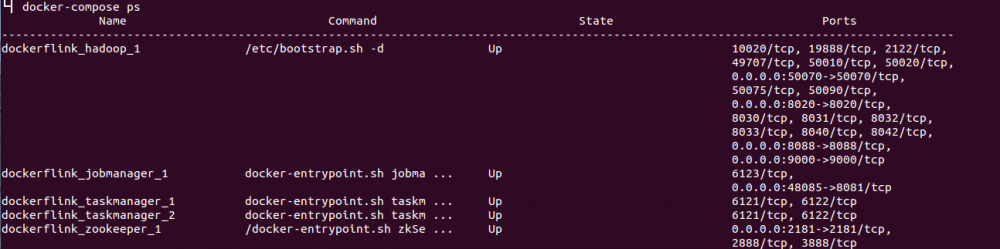
连接zookeeper,可以登录进容器,也可以在宿主机利用映射的2081端口,查看JobManager的注册和选举:
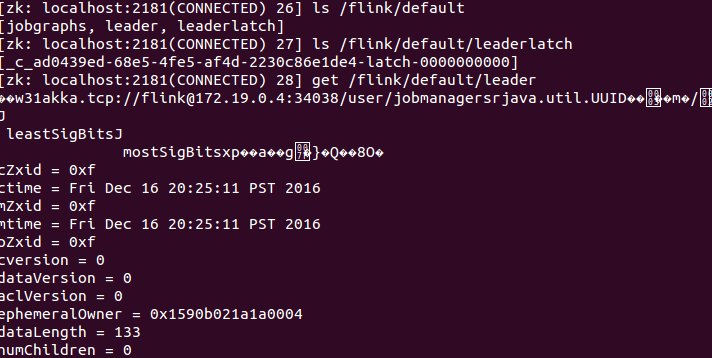
可以看到候选JobManager信息保存在/flink/default/leaderlatch节点,被选举出来的leader JobManager将自己Actor地址和ID对象信息保存在/flink/default/leader节点,TaskManager从zk节点获取该地址向JobManager完成注册。
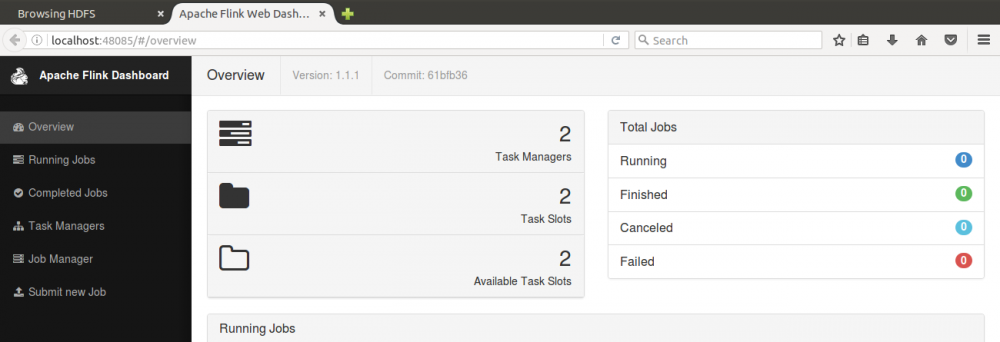
flink web端口8081映射在宿主机48085,浏览器访问该端口可以看到2个TaskManager成功注册:
小结
单机构建集群,集群性能并不会达到分布式的效果,仅仅是资源的隔离,模拟出多个主机,更多的是应用于开发测试使用。实际应用场景的部署仍然需要其他分布式系统管理容器。
正文到此结束
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

