Dynamo:Amazon的高可用性的键-值存储系统
Dynamo是一个分布式键值系统,最初用于支持购物车系统,强调的是提供一个 “永远在线“ 的用户体验。
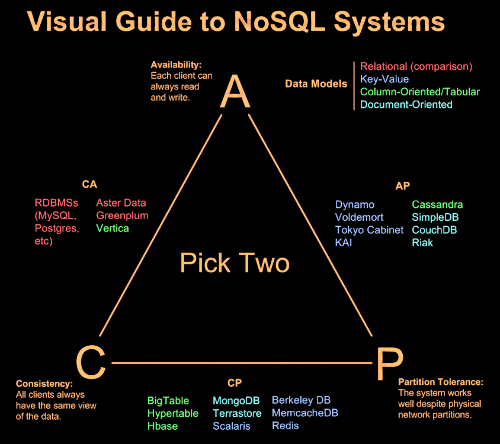
根据CAP理论不可能同时达到一致性、可用性和分区容忍,于是Dynamo选择了AP,放弃了一致性。
Dynamo在设计时遇到的问题及解决方案(来源大规模分布式存储系统第5章)
| 问题 | 采取的技术 |
| ——— | —————————————- |
| 数据分布 | 改进的一致性哈希(虚拟节点) |
| 复制协议 | 复制写协议(Replicated-write protocol,NRW参数可调) |
| 数据冲突处理 | 向量时钟 |
| 临时故障处理 | 数据回传机制 |
| 永久故障恢复 | Merkle哈希树 |
| 成员资格及错误检测 | 基于Gossip的成员资格和错误检测协议 |
数据分布
Dynamo是是一个P2P(peer-to-peer)系统,需要解决怎么快速定位key的位置,答案是DHT(distributed hash table),并且Dynamo为了保证快速响应,就需要保证最快的定位key,于是每个node都保存了整个集群的信息,客户端也缓存了集群信息,保证能将请求直接转发到目标node,达到 zero-hop 。
Dynamo采用一致性哈希的方法来定位key到node,采用一致性哈希的优点是:
节点加入和退出时,只影响哈希环中相邻的节点。
接着考虑到每个节点的异构性,其处理能力不同,于是加入了虚拟节点的概念,尽可能做到每个虚拟节点处理能力一样。
对于一致性哈希算法,用php实现个简单版本:
<?php
classRing{
protected $hashMap = [];
protected $keys = [];
protected $hashFunc;
protected $replicas;
/**
* Ring constructor.
*
* @param $hashFunc
* @param $replicas
*/
public function__construct( $hashFunc = null, $replicas =3)
{
$this->hashFunc = $hashFunc;
$this->replicas = $replicas;
if ( !is_callable( $this->hashFunc ) ) {
$this->hashFunc = 'crc32';
}
}
public functionadd( $keys )
{
if ( !is_array( $keys ) ) {
$keys = func_get_args();
}
foreach ( $keys as $key ) {
for ( $i = 0; $i < $this->replicas; $i++ ) {
$hash = call_user_func( $this->hashFunc, $i . $key );
array_unshift( $this->keys, $hash );
$this->hashMap[ $hash ] = $key;
}
}
sort( $this->keys );
// $this->keys = array_reverse( $this->keys );
}
public functionget( $key ):string
{
if ( empty( $this->keys ) ) {
return '';
}
$hash = call_user_func( $this->hashFunc, $key );
$idx = 0;
foreach ($this->keys as $i => $value){
if ($value >= $hash){
$idx = $i;
break;
}
}
return $this->hashMap[ $this->keys[ $idx ] ];
}
}
$hash = function( $key ){
return (int)$key;
};
$ring = new Ring( $hash, 3 );
$ring->add( 2, 4, 6 );
$testCases = [
"2" => "2",
"11" => "2",
"23" => "4",
"27" => "2",
];
//var_export($ring);
foreach ($testCases as $key => $expected){
assert($ring->get($key) == $expected);
}
原理很简单,看上面代码就能看懂,不多说了,更多的原理可以看 每天进步一点点——五分钟理解一致性哈希算法
起初一致性哈希是为了解决新加入节点和退出节点对数据的影响最小,但是由于数据分布的不均匀,热点数据,节点能力的异构都会造成分布不均匀,于是加入了virtual nodes,但是为了同一份数据的replicas分布式在不同的物理机器上,配置virtual也会造成一定的困难。
一致性和复制
为了应对数据丢失的风险,Dynamo也会对数据进行replicate,进行数据复制的node称为 coordinator ,而负责存储key的node被称为 preference list 。
此处当 coordinator 进行数据复制的时候,是异步进行的,为的就是尽可能快的给用户返回,因此Dynamo是一个弱一致的系统。
Dynamo的一个亮点是NRW,应用根据自己的需求,合理的调整R和W,但是需要满足:
R + W > N
写操作参数W(W<=N),该值的含义是,一个写操作只有成功更新了W个副本,才会被认为操作成功。同样,读操作也有R(R<=N),这是一个读操作需要读取的副本数量。
R + W > N能够保证读操作和写操作有节点交集。也就是,至少有一个节点会被读操作和写操作同时操作到。
通过调整R和W能实现available和consistency之间的转换。
给W配置一个小值R配置一个大值则”writes never fail”(high availablility);给R配置一个小值W配置一个大值则”block for all replicas to be readable”(strong consistency)
下一个考虑的是数据冲突问题,看一个例子:
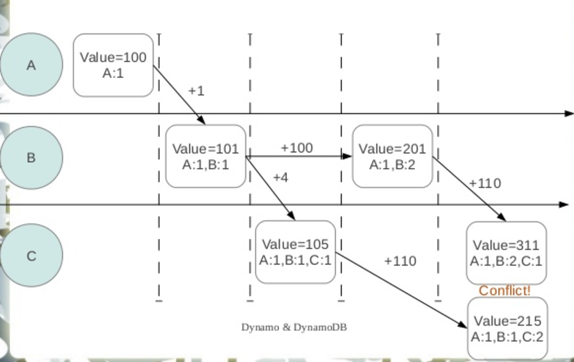
每个node都记录自己的操作记录,通过向量时钟能记录记录同一对象不同版本间的因果关系。当节点接收到更新,逐项对比本地向量钟和待更新数据的向量时钟。如果待更新数据的向量钟的每一项都不小于本地向量钟,那么数据无冲突,新的值可以被接受。Dynamo并不会贸然假定数据的冲突合并准则,而是保留全部的冲突数据,等待客户端处理。
容错
Dynamo将异常分为两种:
- 临时性问题
- 永久性问题
针对临时性故障,其处理策略是仲裁(quorum),但是如果严格执行仲裁策略,会影响Dynamo的可用性,因为需要等到N个都执行了,才能返回,此时如果其中一个临时故障了,会影响可用性。
于是Dynamo采用了 sloppy quorum 策略,只需要N个 healthy node 即可,具体是指:如果某台机器故障了,则顺延将数据写入到后面的健康机器,并标注数据为hinted handoff,当机器恢复后,将数据进行回传。
针对永久性故障,我们解决方案是Merkle哈希树。Merkle的原理是:每个非叶子节点对应多个文件,值是其所有子节点值组合以后的哈希值,叶子节点对应单个数据文件,值是文件内容的哈希。通过比对Merkle树,就能找出不同的文件了。
成员资格及错误检测
最开始介绍过一致性哈希,为了保证能够直接找到key对应的node,因此所有的node中都保存了集群中所有node的路由信息,这就导致有新节点加入或者节点推出的时候,需要将这信息传递给集群内的所有人,于是就有了Gossip

从上图中能看到Gossip就是在AP系统中特有的,
在看下下面这张图,说明了Gossip算法
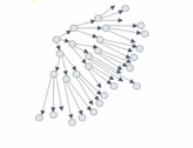
1传3,3传9,9传27,快速扩散,然后整个集群就都知道了。
总结
本文只是对Dynamo简单阅读,好多问题还没有阐述清楚,以后有了深入阅读后再来继续补充的,就目前来说,先对Dynamo做个总结,Dynamo总体特点是:
- 最终一致性
- 即使故障的时候也要保证可写
- 允许写冲突,让应用自己解决
正文到此结束
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

