新型列式存储格式 Parquet 详解
Apache Parquet是Hadoop生态圈中一种 新型列式存储格式 ,它可以兼容Hadoop生态圈中大多数计算框架(Hadoop、Spark等),被多种查询引擎支持(Hive、Impala、Drill等),并且它是语言和平台无关的。Parquet最初是由Twitter和Cloudera(由于Impala的缘故)合作开发完成并开源,2015年5月从Apache的孵化器里毕业成为Apache顶级项目,最新的版本是1.8.1。
1. 概述
1.1 简介
Apache Parquet是Hadoop生态圈中一种 新型列式存储格式 ,它可以兼容Hadoop生态圈中大多数计算框架(Hadoop、Spark等),被多种查询引擎支持(Hive、Impala、Drill等),并且它是语言和平台无关的。Parquet最初是由Twitter和Cloudera(由于Impala的缘故)合作开发完成并开源,2015年5月从Apache的孵化器里毕业成为Apache顶级项目,最新的版本是1.8.1。
Parquet是语言无关的,而且不与任何一种数据处理框架绑定在一起,适配多种语言和组件,能够与Parquet配合的组件有:
查询引擎: Hive, Impala, Pig, Presto, Drill, Tajo, HAWQ, IBM Big SQL
计算框架: MapReduce, Spark, Cascading, Crunch, Scalding, Kite
数据模型: Avro, Thrift, Protocol Buffers, POJOs
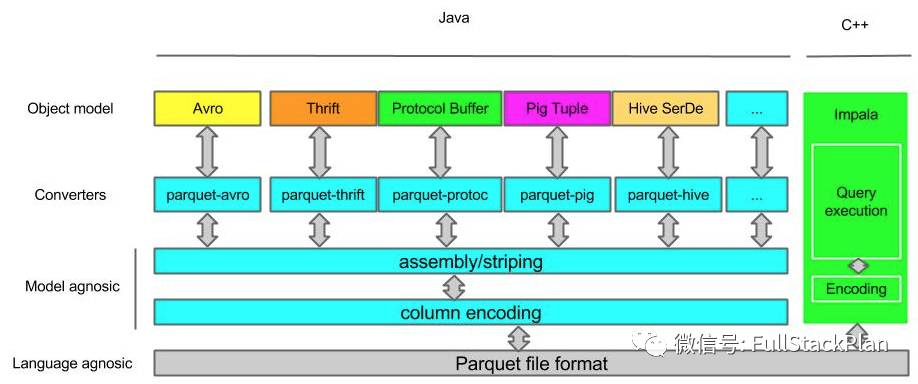
那么Parquet是如何与这些组件协作的呢?这个可以通过下图来说明。数据从内存到Parquet文件或者反过来的过程主要由以下三个部分组成:
-
存储格式(storage format)
parquet-format项目定义了Parquet内部的数据类型、存储格式等。
-
对象模型转换器(object model converters)
这部分功能由parquet-mr项目来实现,主要完成外部对象模型与Parquet内部数据类型的映射。
-
对象模型(object models)
对象模型可以简单理解为内存中的数据表示,Avro, Thrift, Protocol Buffers, Hive SerDe, Pig Tuple, Spark SQL InternalRow等这些都是对象模型。Parquet也提供了一个example object model 帮助大家理解。
例如parquet-mr项目里的parquet-pig项目就是负责把内存中的Pig Tuple序列化并按列存储成Parquet格式,以及反过来把Parquet文件的数据反序列化成Pig Tuple。
这里需要注意的是Avro, Thrift, Protocol Buffers都有他们自己的存储格式,但是Parquet并没有使用他们,而是使用了自己在parquet-format项目里定义的存储格式。所以如果你的应用使用了Avro等对象模型,这些数据序列化到磁盘还是使用的parquet-mr定义的转换器把他们转换成Parquet自己的存储格式。
1.2 列式存储
列式存储,顾名思义就是按照列进行存储数据,把某一列的数据连续的存储,每一行中的不同列的值离散分布。列式存储技术并不新鲜,在关系数据库中都已经在使用,尤其是在针对OLAP场景下的数据存储,由于OLAP场景下的数据大部分情况下都是批量导入,基本上不需要支持单条记录的增删改操作,而查询的时候大多数都是只使用部分列进行过滤、聚合,对少数列进行计算(基本不需要select * from xx之类的查询)。
example:
以下这张表有A、B、C三个字段:
| A | B | C |
|---|---|---|
| A1 | B1 | C1 |
| A2 | B2 | C2 |
| A3 | B3 | C3 |
行存储:
|A1|B1|C1|A2|B2|C2|A3|B3|C3| |-|-|-|-|-|-|-|-|-|
列存储
|A1|A2|A3|B1|B2|B3|C1|C2|C3| |-|-|-|-|-|-|-|-|-|
列式存储可以大大提升这类查询的性能,较之于行是存储,列式存储能够带来这些优化:
-
查询的时候不需要扫描全部的数据,而只需要读取每次查询涉及的列,这样可以将I/O消耗降低N倍,另外可以保存每一列的统计信息(min、max、sum等),实现部分的谓词下推。
-
由于每一列的成员都是同构的,可以针对不同的数据类型使用更高效的数据压缩算法,进一步减小I/O。
-
由于每一列的成员的同构性,可以使用更加适合CPU pipeline的编码方式,减小CPU的缓存失效。
2. Parquet详解
2.1 数据模型
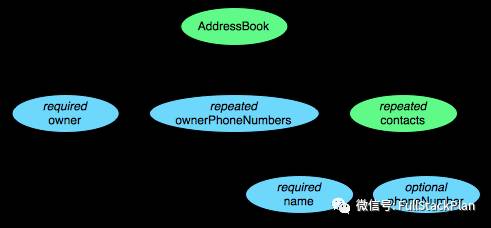
理解Parquet首先要理解这个列存储格式的数据模型。我们以一个下面这样的schema和数据为例来说明这个问题。
message AddressBook {
required string owner;
repeated string ownerPhoneNumbers;
repeated group contacts {
required string name;
optional string phoneNumber;
}
}
这个schema中每条记录表示一个人的AddressBook。有且只有一个owner,owner可以有0个或者多个ownerPhoneNumbers,owner可以有0个或者多个contacts。每个contact有且只有一个name,这个contact的phoneNumber可有可无。
每个schema的结构是这样的:根叫做message,message包含多个fields。每个field包含三个属性:repetition, type, name。repetition可以是以下三种:required(出现1次),optional(出现0次或者1次),repeated(出现0次或者多次)。type可以是一个group或者一个primitive类型。
Parquet格式的数据类型不需要复杂的Map, List, Set等,而是使用repeated fields 和 groups来表示。例如List和Set可以被表示成一个repeated field,Map可以表示成一个包含有key-value 对的repeated group ,而且key是required的。
List(或Set)可以用repeated field来表示:
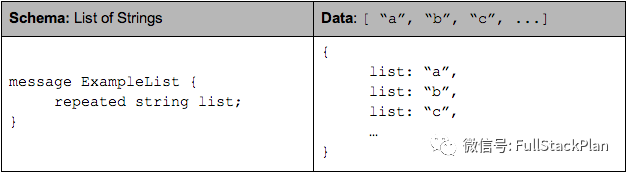
Map可以用包含key-value对且key是required的repeated group来表示:

2.2 列存储格式
列存储通过将相同基本类型(primitive type)的值存储在一起来提供高效的编码和解码。为了用列存储来存储如上嵌套的数据结构,我们需要将该schema用某种方式映射到一系列的列使我们能够将记录写到列中并且能读取成原来的嵌套的数据结构。
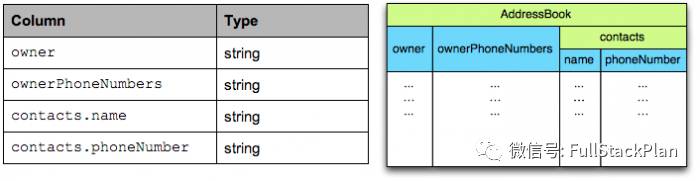
在Parquet格式的存储中,一个schema的树结构有几个叶子节点(叶子节点都是primitive type),实际的存储中就会有多少column。
上面的schema的树结构如图所示:
上面这个schema的数据存储实际上有四个column,如下图所示:
只有字段值不能表达清楚记录的结构。给出一个repeated field的两个值,我们不知道此值是按什么‘深度’被重复的(比如,这些值是来自两个不同的记录,还是相同的记录中两个重复的值)。同样的,给出一个缺失的可选字段,我们不知道整个路径有多少字段被显示定义了。因此我们将介绍repetition level 和 definition level的概念。
example:
两条嵌套的记录和它们的schema:

将上图的两条记录用列存储表示:
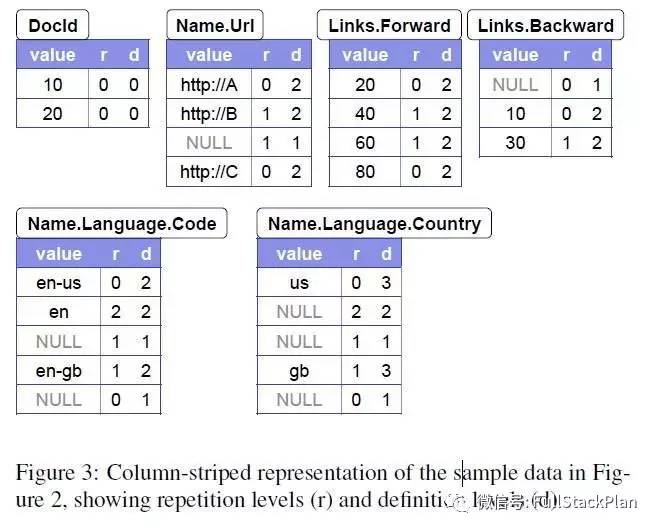
上面的例子主要是想让大家对嵌套结构的列式存储有个直观的印象,包括repetition level 和 definition level的应用,接下来详细介绍repetition level 和 definition level。
2.3 Definition levels
Definition level指明该列的路径上多少个可选field被定义了。
嵌套数据类型的特点是有些field(optional field 和 repeated field)可以是空的,也就是没有定义。如果一个field是定义的,那么它的所有的父节点都是被定义的。从根节点开始遍历,当某一个field的路径上的节点开始是空的时候我们记录下当前的深度作为这个field的Definition Level。如果一个field的definition Level等于这个field的最大definition Level就说明这个field是有数据的。对于required类型的field必须是有定义的,所以这个Definition Level是不需要的。在关系型数据中,optional类型的field被编码成0表示空和1表示非空(或者反之)。
注:definition Level是该路径上有定义的repeated field 和 optional field的个数,不包括required field,因为required field是必须有定义的。
再举个简单的例子:
message ExampleDefinitionLevel {
optional group a {
required group b {
optional string c;
}
}
}

因为b是required field,所以第3行c的definition level为1而不是2(因为b是required field,所有不需计算在内);第4行c的definition level为2而不是3(理由同上).
2.4 Repetition levels
Repetition level指明该值在路径中哪个repeated field重复。
Repetition level是针对repeted field的。注意在图2中的Code字段。可以看到它在r1出现了3次。‘en-us’、‘en’在第一个Name中,而‘en-gb’在第三个Name中。结合了图2你肯定能理解我上一句话并知道‘en-us’、‘en’、‘en-gb’出现在r1中的具体位置,但是不看图的话呢?怎么用文字,或者说是一种定义、一种属性、一个数值,诠释清楚它们出现的位置?这就是重复深度这个概念的作用,它能用一个数字告诉我们在路径中的什么重复字段,此值重复了,以此来确定此值的位置(注意,这里的重复,特指在某个repeated类型的字段下“重复”出现的“重复”)。我们用深度0表示一个纪录的开头(虚拟的根节点),深度的计算忽略非重复字段(标签不是repeated的字段都不算在深度里)。所以在Name.Language.Code这个路径中,包含两个重复字段,Name和Language,如果在Name处重复,重复深度为1(虚拟的根节点是0,下一级就是1),在Language处重复就是2,不可能在Code处重复,它是required类型,表示有且仅有一个;同样的,在路径Links.Forward中,Links是optional的,不参与深度计算(不可能重复),Forward是repeated的,因此只有在Forward处重复时重复深度为1。现在我们从上至下扫描纪录r1。当我们遇到’en-us’,我们没看到任何重复字段,也就是说,重复深度是0。当我们遇到‘en’,字段Language重复了(在‘en-us’的路径里已经出现过一个Language),所以重复深度是2.最终,当我们遇到’en-gb‘,Name重复了(Name在前面‘en-us’和‘en’的路径里已经出现过一次,而此Name后Language只出现过一次,没有重复),所以重复深度是1。因此,r1中Code的值的重复深度是0、2、1.
要注意第二个Name在r1中没有包含任何Code值。为了确定‘en-gb’出现在第三个Name而不是第二个,我们添加一个NULL值在‘en’和‘en-gb’之间(如图3所示)。
2.5 Striping and assembly
下面用AddressBook的例子来说明Striping和assembly的过程。
对于每个column的最大的Repetion Level和 Definition Level下图所示。

下面这样两条record:
AddressBook {
owner: "Julien Le Dem",
ownerPhoneNumbers: "555 123 4567",
ownerPhoneNumbers: "555 666 1337",
contacts: {
name: "Dmitriy Ryaboy",
phoneNumber: "555 987 6543",
},
contacts: {
name: "Chris Aniszczyk"
}
}
AddressBook {
owner: "A. Nonymous"
}
以contacts.phoneNumber这一列为例,"555 987 6543"这个contacts.phoneNumber的Definition Level是最大Definition Level=2。而如果一个contact没有phoneNumber,那么它的Definition Level就是1。如果连contact都没有,那么它的Definition Level就是0。
下面我们拿掉其他三个column只看contacts.phoneNumber这个column,把上面的两条record简化成下面的样子:
AddressBook {
contacts: {
phoneNumber: "555 987 6543"
}
contacts: {
}
}
AddressBook {
}
这两条记录的序列化过程如下图所示:

如果我们要把这个column写到磁盘上,磁盘上会写入这样的数据:
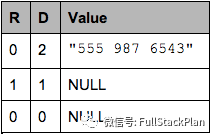
注意:NULL实际上不会被存储,如果一个column value的Definition Level小于该column最大Definition Level的话,那么就表示这是一个空值。
下面是从磁盘上读取数据并反序列化成AddressBook对象的过程:
-
读取第一个三元组R=0, D=2, Value=”555 987 6543”
R=0 表示是一个新的record,要根据schema创建一个新的nested record直到Definition Level=2。
D=2 说明Definition Level=Max Definition Level,那么这个Value就是contacts.phoneNumber这一列的值,赋值操作contacts.phoneNumber=”555 987 6543”。
-
读取第二个三元组 R=1, D=1
R=1 表示不是一个新的record,是上一个record中一个新的contacts。
D=1 表示contacts定义了,但是contacts的下一个级别也就是phoneNumber没有被定义,所以创建一个空的contacts。
-
读取第三个三元组 R=0, D=0
R=0 表示一个新的record,根据schema创建一个新的nested record直到Definition Level=0,也就是创建一个AddressBook根节点。
可以看出在Parquet列式存储中,对于一个schema的所有叶子节点会被当成column存储,而且叶子节点一定是primitive类型的数据。对于这样一个primitive类型的数据会衍生出三个sub columns (R, D, Value),也就是从逻辑上看除了数据本身以外会存储大量的Definition Level和Repetition Level。那么这些Definition Level和Repetition Level是否会带来额外的存储开销呢?实际上这部分额外的存储开销是可以忽略的。因为对于一个schema来说level都是有上限的,而且非repeated类型的field不需要Repetition Level,required类型的field不需要Definition Level,也可以缩短这个上限。例如对于Twitter的7层嵌套的schema来说,只需要3个bits就可以表示这两个Level了。
对于存储关系型的record,record中的元素都是非空的(NOT NULL in SQL)。Repetion Level和Definition Level都是0,所以这两个sub column就完全不需要存储了。所以在存储非嵌套类型的时候,Parquet格式也是一样高效的。
2.6 文件格式
-
行组(Row Group):按照行将数据物理上划分为多个单元,每一个行组包含一定的行数。一个行组包含这个行组对应的区间内的所有列的列块。
官方建议:
更大的行组意味着更大的列块,使得能够做更大的序列IO。我们建议设置更大的行组(512MB-1GB)。因为一次可能需要读取整个行组,所以我们想让一个行组刚好在一个HDFS块中。因此,HDFS块的大小也需要被设得更大。一个最优的读设置是:1GB的行组,1GB的HDFS块,1个HDFS块放一个HDFS文件。
-
列块(Column Chunk):在一个行组中每一列保存在一个列块中,行组中的所有列连续的存储在这个行组文件中。不同的列块可能使用不同的算法进行压缩。一个列块由多个页组成。
-
页(Page):每一个列块划分为多个页,页是压缩和编码的单元,对数据模型来说页是透明的。在同一个列块的不同页可能使用不同的编码方式。官方建议一个页为8KB。
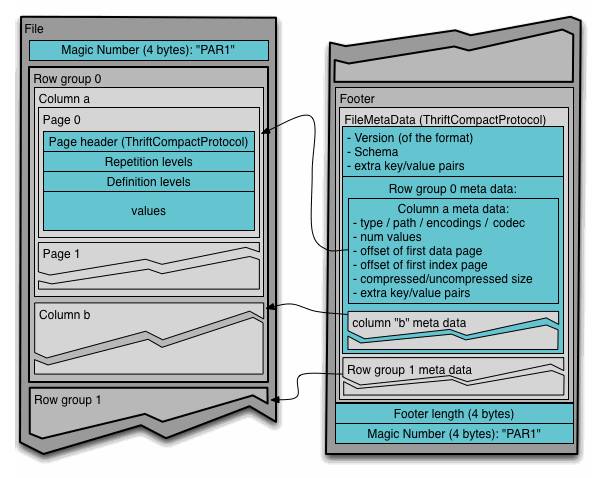
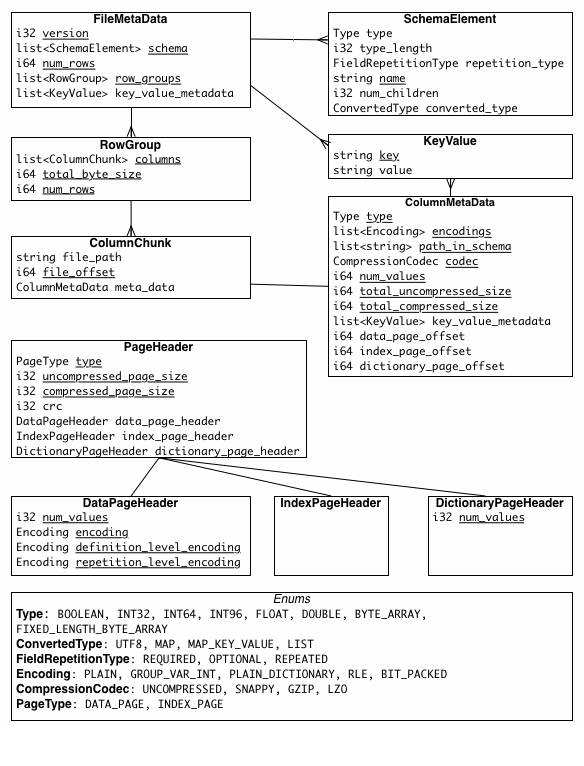
上图展示了一个Parquet文件的结构,一个文件中可以存储多个行组,文件的首位都是该文件的Magic Code,用于校验它是否是一个Parquet文件,Footer length存储了文件元数据的大小,通过该值和文件长度可以计算出元数据的偏移量,文件的元数据中包括每一个行组的元数据信息和当前文件的Schema信息。除了文件中每一个行组的元数据,每一页的开始都会存储该页的元数据,在Parquet中,有三种类型的页:数据页、字典页和索引页。数据页用于存储当前行组中该列的值,字典页存储该列值的编码字典,每一个列块中最多包含一个字典页,索引页用来存储当前行组下该列的索引,目前Parquet中还不支持索引页,但是在后面的版本中增加。
2.7 映射下推(Project PushDown)
说到列式存储的优势,映射下推是最突出的,它意味着在获取表中原始数据时只需要扫描查询中需要的列,由于每一列的所有值都是连续存储的,所以分区取出每一列的所有值就可以实现TableScan算子,而避免扫描整个表文件内容。
在Parquet中原生就支持映射下推,执行查询的时候可以通过Configuration传递需要读取的列的信息,这些列必须是Schema的子集,映射每次会扫描一个Row Group的数据,然后一次性得将该Row Group里所有需要的列的Cloumn Chunk都读取到内存中,每次读取一个Row Group的数据能够大大降低随机读的次数,除此之外,Parquet在读取的时候会考虑列是否连续,如果某些需要的列是存储位置是连续的,那么一次读操作就可以把多个列的数据读取到内存。
2.8 谓词下推(Predicate PushDown)
在数据库之类的查询系统中最常用的优化手段就是谓词下推了,通过将一些过滤条件尽可能的在最底层执行可以减少每一层交互的数据量,从而提升性能,例如”select count(1) from A Join B on A.id = B.id where A.a > 10 and B.b < 100″SQL查询中,在处理Join操作之前需要首先对A和B执行TableScan操作,然后再进行Join,再执行过滤,最后计算聚合函数返回,但是如果把过滤条件A.a > 10和B.b < 100分别移到A表的TableScan和B表的TableScan的时候执行,可以大大降低Join操作的输入数据。
无论是行式存储还是列式存储,都可以在将过滤条件在读取一条记录之后执行以判断该记录是否需要返回给调用者,在Parquet做了更进一步的优化,优化的方法时对每一个Row Group的每一个Column Chunk在存储的时候都计算对应的统计信息,包括该Column Chunk的最大值、最小值和空值个数。通过这些统计值和该列的过滤条件可以判断该Row Group是否需要扫描。另外Parquet未来还会增加诸如Bloom Filter和Index等优化数据,更加有效的完成谓词下推。
3. 性能
3.1 压缩
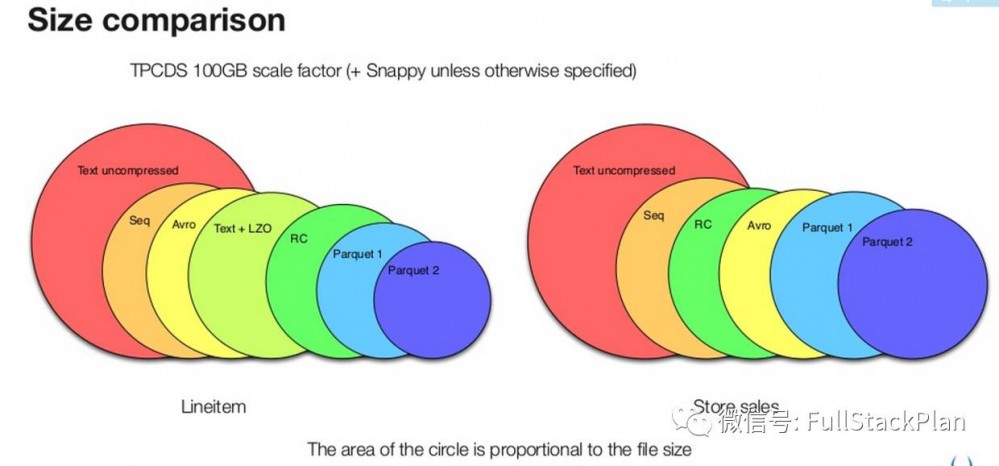
上图是展示了使用不同格式存储TPC-H和TPC-DS数据集中两个表数据的文件大小对比,可以看出Parquet较之于其他的二进制文件存储格式能够更有效的利用存储空间,而新版本的Parquet(2.0版本)使用了更加高效的页存储方式,进一步的提升存储空间。
3.2 查询
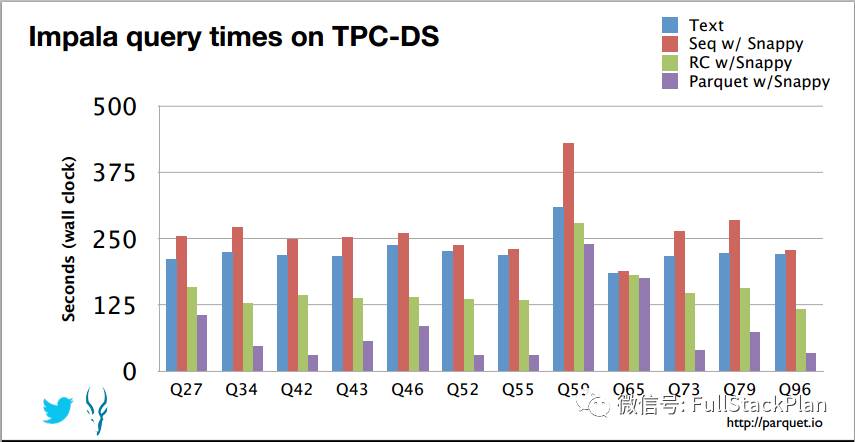
上图展示了Twitter在Impala中使用不同格式文件执行TPC-DS基准测试的结果,测试结果可以看出Parquet较之于其他的行式存储格式有较明显的性能提升。
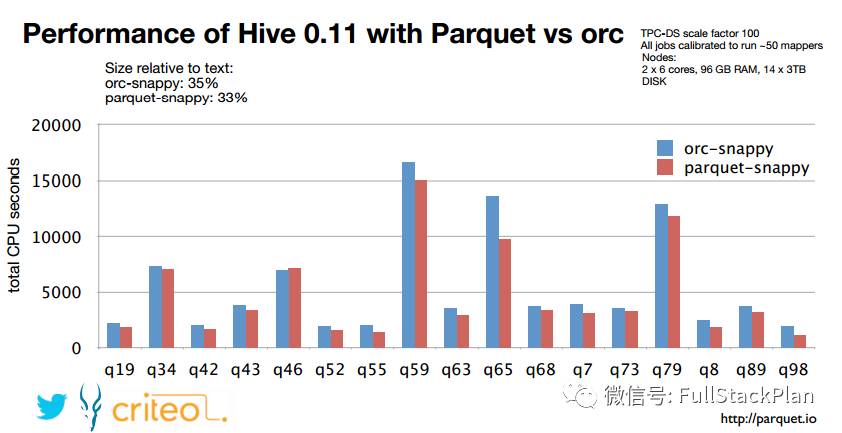
上图展示了criteo公司在Hive中使用ORC和Parquet两种列式存储格式执行TPC-DS基准测试的结果,测试结果可以看出在数据存储方面,两种存储格式在都是用snappy压缩的情况下量中存储格式占用的空间相差并不大,查询的结果显示Parquet格式稍好于ORC格式,两者在功能上也都有优缺点,Parquet原生支持嵌套式数据结构,而ORC对此支持的较差,这种复杂的Schema查询也相对较差;而Parquet不支持数据的修改和ACID,但是ORC对此提供支持,但是在OLAP环境下很少会对单条数据修改,更多的则是批量导入。
4. 总结
本文介绍了一种支持嵌套数据模型对的列式存储格式Parquet,作为大数据系统中OLAP查询的优化方案,它已经被多种查询引擎原生支持,并且部分高性能引擎将其作为默认的文件存储格式。通过数据编码和压缩,以及映射下推和谓词下推功能,Parquet的性能也较之其它文件格式有所提升,可以预见,随着数据模型的丰富和Ad hoc查询的需求,Parquet将会被更广泛的使用。
5. 参考
-
Google论文:Dremel: Interactive Analysis of Web-Scale Datasets
-
Twitter博文:Dremel made simple with Parquet
-
http://www.importnew.com/2617.html
-
http://www.2cto.com/database/201605/509506.html
-
http://www.infoq.com/cn/articles/in-depth-analysis-of-parquet-column-storage-format/
 长按关注公众号获取更多干货哦~
长按关注公众号获取更多干货哦~
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

