OpenStack Swift源码导读之——业务整体架构和Proxy进程
OpenStack的源码分析在网上已经非常多了,针对各个部分的解读亦是非常详尽。这里我根据自己的理解把之前读过的Swift源码的一些要点记录一下,希望给需要的同学能带来一些帮助。
一、Swift的整体框架图
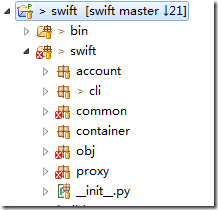
如上图,Swift的源码目录结构。其中proxy是前端的业务接入进程。account、container和object目录分别是账户、容器和对象的业务处理逻辑进程。common目录是一些通用工具代码。common中比较重要的有:哈希环的处理逻辑。接下来会依次介绍各个进程的源码逻辑和一些关键点机制。
各个业务进程或模块之间的逻辑关系可以参考《 Openstack Swift简介 》文中的架构图。
二、Proxy进程的业务处理
首先需要掌握基于PasteDeploy的堆栈式WSGI架构。根据PasteDeploy定义的各个层,可以很快理清配置文件定义的代码流程,从middleware到server。找到最外层的middleware,即是业务的入口。对于proxy进程,可以简单给出业务时序图:

每一层的分工非常清晰,如在proxy进程默认配置文件中,最上层是做异常处理,所有的业务流程抛出的未处理的异常,在这里都将得到处理。
Proxy进程会分析请求的URI(account、container和object组成的资源路径)和请求方法(put、del等)来分析当前请求的资源的具体类型,然后分别找到控制该资源的controller,由controller来分发请求到具体的资源server。分发的原则是一致性哈希环。一致性哈希环在系统初始化时由工具生成,在《 Swift 和 Keystone单机安装总结 》一文中有具体的操作步骤。
在《 Openstack Swift简介 》从理论上面介绍了具体的节点寻找过程。采用md5值加移位的方式来确定part,然后找到所有的虚拟节点。具体的代码为:
container_partition, containers = self.app.container_ring.get_nodes(
self.account_name, self.container_name)
def get_nodes(self, account, container=None, obj=None):
"""
Get the partition and nodes
for an account/container/object.
If a node is responsible
for more than one replica, it will
only appear in the
output once.
:param account: account name
:param
container: container name
:param obj: object name
:returns: a tuple of (partition, list of node dicts)
Each node dict will have at least the following keys:
======
===============================================================
id unique integer
identifier amongst devices
weight a float of the
relative weight of this device as compared to
others;
this indicates how many partitions the builder will try
to assign
to this device
zone integer indicating
which zone the device is in; a given
partition
will not be assigned to multiple devices within the
same zone
ip the ip address of the
device
port the tcp port of the device
device the device's name on disk (sdb1, for
example)
meta general use 'extra'
field; for example: the online date, the
hardware
description
======
===============================================================
"""
part = self.get_part(account,
container, obj)
return part,
self._get_part_nodes(part)
def get_part(self, account, container=None, obj=None):
"""
Get the partition for an
account/container/object.
:param account: account name
:param
container: container name
:param obj: object name
:returns: the partition number
"""
key = hash_path(account, container, obj, raw_digest=True)
if time() >; self._rtime:
self._reload()
part = struct.unpack_from('>;I', key)[0] >>
self._part_shift
return part
def _get_part_nodes(self, part):
part_nodes = []
seen_ids = set()
for r2p2d in
self._replica2part2dev_id:
if
part <; len(r2p2d):
dev_id =
r2p2d[part]
if dev_id
not in seen_ids:
part_nodes.append(self.devs[dev_id])
seen_ids.add(dev_id)
return part_nodes
然后根据quorum原则来决定当前请求至少需要几个节点成功即可返回。如NWR分别为322,则至少需要2个节点写成功,才能确保此次写成功。体现在公用的make_request方法中:
def make_requests(self, req, ring, part, method, path, headers, query_string=''): """ Sends an HTTP request to multiple nodes and aggregates the results. It attempts the primary nodes concurrently, then iterates over the handoff nodes as needed. :param req: a request sent by the client :param ring: the ring used for finding backend servers :param part: the partition number :param method: the method to send to the backend :param path: the path to send to the backend (full path ends up being /<$device>/<$part>/<$path>) :param headers: a list of dicts, where each dict represents one backend request that should be made. :param query_string: optional query string to send to the backend :returns: a swob.Response object """ start_nodes = ring.get_part_nodes(part) nodes = GreenthreadSafeIterator(self.app.iter_nodes(ring, part)) pile = GreenAsyncPile(len(start_nodes)) for head in headers: pile.spawn(self._make_request, nodes, part, method, path, head, query_string, self.app.logger.thread_locals) response = [] statuses = [] for resp in pile: if not resp: continue response.append(resp) statuses.append(resp[0]) if self.have_quorum(statuses, len(start_nodes)): break # give any pending requests *some* chance to finish pile.waitall(self.app.post_quorum_timeout) while len(response) <; len(start_nodes): response.append((HTTP_SERVICE_UNAVAILABLE, '', '', '')) statuses, reasons, resp_headers, bodies = zip(*response) return self.best_response(req, statuses, reasons, bodies, '%s %s' % (self.server_type, req.method), headers=resp_headers)
正文到此结束
热门推荐










相关文章

近期评论
-
收到
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
-
不会英语啊。
-
-
-
https://pplx.ai/floraliu4199466 这个链接打不开是什么原因?
-
-
-
-
来看看,最近更新了一波,顺着友联过来的,几年过去了,网站越搞越好,厉害
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

