海航生态科技舆情大数据平台容器化改造
海航舆情监控系统能够为海航集团内部提供监控网络舆情信息,对负面信息、重大舆情及时预警,研判具体舆情或者某一舆情专题事件的发展变化趋势,生成图标报告和各种统计数据,提高舆情工作效率和辅助领导决策。然而,随着项目的持续运行,许多问题逐渐暴露出来,为了解决这些难题,对整个项目重新规划设计,迁移到Hadoop、Spark大数据平台,引进持续化Docker容器部署和发布,开发和运营效率得到显著提升。
一、 舆情平台介绍
我们的舆情平台
舆情平台项目的初衷是为了加强海航集团及其下属各成员企业的品牌效应,并且减少关键信息传播的成本,及时洞悉客户评价和舆论走向,以及指导舆论引导工作,加快对紧急事件的响应速度。
需要完成工作包括分析及预测敏感内容在互联网、社交网络等载体的传播状况,包括数据采集, 情感分析,爆发预测,敏感预警等
目前的规模:
- 微博类:
通过设置微博种子账户(一部分通过搜索,一部分是公司微博账号),挖掘粉丝的粉丝深层次挖掘,爬取数据每天信息条目目前有20w 左右,逐渐会加入更多 的种子账户,也在沟通购买新浪的开放API;
-
新闻、论坛、博客:
主流媒体30个;
大型论坛20个;
科技行业70个;
财经行业30个;
旅游行业33个;
航空行业30个;
其他如微信公众号、自媒体类,同行业票价网站等,一共300多家站点,数据维度达到30多个,每天数据量达150w条,数据量接近10G;
主要功能如下:
• 数据爬取: 每天定时计划爬取指定微博,新闻媒体最新发布信息,存储以供分析
• 数据存储:存储微博、新闻内容、图片等,以及中间分析结果、计算结果
• 微博舆情:统计分析、信息监测、信息检索
• 新闻舆情:统计分析、信息监测、信息检索
• 热词统计:高频度热词统计
• 情感分析:文本分析、根据文字内容定位情感倾向
• 舆情监测:根据指定敏感词进行信息过滤,并提供通知功能
• 数据接口服务:提供对外的Rest的API数据服务
• 热点事件梳理:提供检索,优先列出热度高的新闻、微博记录
• 图像识别和内容分析:(这部分正在做)
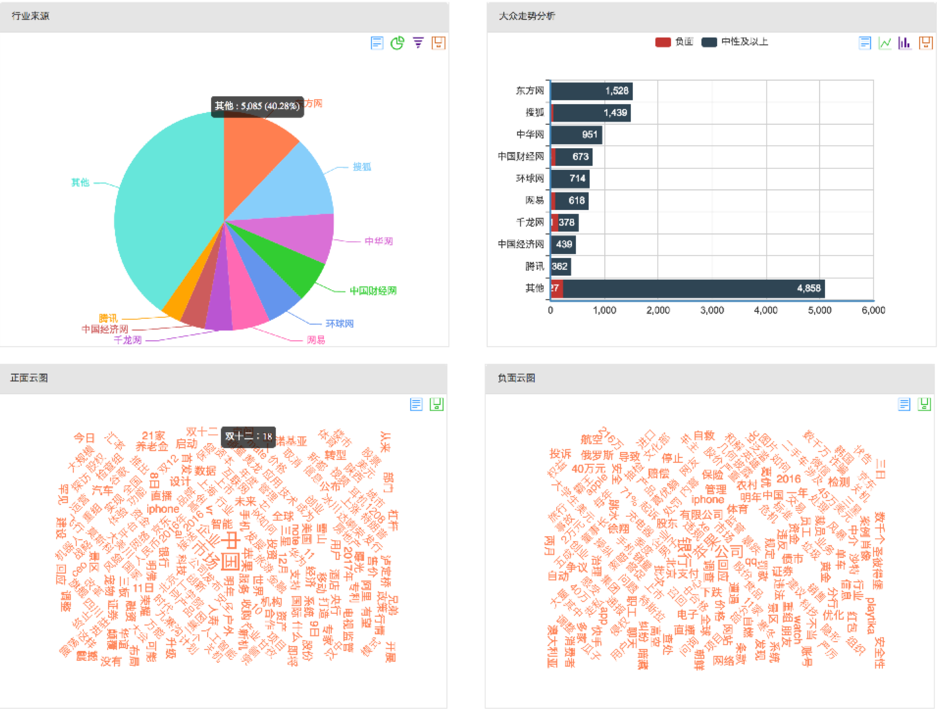
一些展示效果如下所示:
二、 初期架构
加入项目的时候,项目架构比较简单,作为一个验证阶段,就是一个传统的Web应用,采用的 Spring Web MVC + MySQL,再加上数据采集功能爬虫系统+文本分析模型(CNN),代码审查使用git+gitlab。
爬虫部分:
java语言实现,基于WebMagic框架二次开发。由于各个网站的页面布局没有一个统一的格式,所以开发人员需要针对每个网站单独写一个爬虫程序用来做页面数据解析。爬虫在部署的时候是,手动进行编译,并按照运行计划打多个可执行jar包,分别部署到多个节点上执行,数据存入MySQL数据库(用一个专门的节点来部署)。支持最初的30几个网站和微博的数据,数据量每天大概有不到20w。
文本分析模型
python实现,使用结巴分词工具和CNN(卷积神经网络)模型,支持矩阵批量运算。运行方式是python web(用框架是tornado)提供API,由爬虫调用调用,并回填结果,增加情感倾向、热度、关键词等字段,后存入数据库。
前端+后台
典型的Spring MVC应用,采用Spring MVC+MyBatis+MySQL,前端使用ECharts生成图形和报表;统计数据是提前计算好,存入MySQL数据库中,并通过quartz调度运算作业和数据更新 。
很显然,MySQL无法应对数据的大量增长,这个平台对于数据的增长和扩张是无法适应的, 应用的接口响应时间从开始的几秒甚至延长到几分钟,无法令人接受。
总结一下,这个框架有多个显而易见的弊端(也算是初期作为验证使用,另一方面也是因为开始资源不足):
• 不能支持大量的数据存储(同时还保持不错的性能)
• 不能较好地支持多种格式的数据存储
• 项目依赖库文件也未代码化管理,更新、升级、打包非常麻烦
• 部署困难,手动打包,tomcat部署运行,不方便开发及测试人员,对新人极不友好
• 性能差,很难进行横向扩展
三、 应用容器化
为了解决上述问题,我们就尝试去做首先确定的是需要迁往大数据平台。在这同时,我们做了一些容器化的工作。做这些工作的目的是,方便部署和迁移,容易进行伸缩控制,能够借助工具向着自动化的方向进行。
1) 引入Gradle+Jenkins持续构建工具
采用Gradle构建工具,使用了gretty插件,去除代码依赖 jar包,依赖代码化,配置一键调试和运行;采用Jenkins持续构建工具,给每一个模块搭建了一条流水线代码测试、打包和部署,目前部署是shell脚本实现。
2) 代码结构整理
爬虫代码中每个站点的数据抓取是一条流水线,每条流水线有着相同的流程,我们把配置部分代码抽出来,改写启动入口接收配置参数,由配置来决定启动哪些站点的流水线;修改Spring Web改为前后端分离;
3) 应用容器化
首先是MySQL数据库容器化,把默认的/var/lib/mysql数据目录和配置文件目录挂载到了本地,把之前的数据做了迁移;接着是Web服务,使用Tomcat镜像,挂载了webapps目录,gradle打war包复制到本地挂载目录;
然后是文本分析模型,由于文本分析模型需要安装大量依赖文件(pip),我们重新构建了镜像提交到本地Registry;周期执行的计算任务打成jar包,运行时启动新的镜像实例运行。
4) 使用Rancher容器管理监控平台
容器编排我们使用的是Rancher平台,使用默认Cattle编排引擎。我们大概有40多个长时运行的实例,分为3类:
爬虫实例,接近40个实例调度到20多个宿主节点上。我们数据放在在CDH平台上,这些容器间并不发生通信,只与文本分析模型进行通信,最后数据发送到CDH集群的Kafka,对这些实例只进行代码替换、更新及运维工作;
目前部署了3个文本分析模型的实例,由爬虫根据名字随机请求。
批处理任务类,使用rancher提供的crontab工具,周期性的运行。
现在可以做到自动的代码更新和部署,时间大概不到一个小时,之前部署一次至少半天。
5) 本地镜像仓库
Rancher提供了Registry管理功能,可以很方便地管理Registry。为了加速下载,我们在本地部署了一个registry,方便镜像更新和应用迁移。
四、 技术架构迁移
随着爬虫爬取的数据逐日增加,现在这个系统肯定是支撑不了的。 我们经过讨论,确定了基本架构。使用HBase + ElasticSearch作为数据存储,Kafka作消息队列,由HBase负责保存爬虫数据,ES则负责建立索引(我们的一致性目前要求不高)。由Rancher管理分布式爬虫将爬取的数据送往Kakfa集群,在这之前向文本分析模型(容器中)发送http请求,回填相应字段。然后再由两个Kafka Consumer将数据分别传输到HBase和ES中完成数据保存。
爬虫现在经过容器化,由Rancher进行管理。
统计工作交由Spark SQL读写HBase完成,目前还没有做到实时的。我们的做法是按天统计存到表中,服务请求时根据请求条件选择计算范围进行实时计算。这个算是离实时性前进了一步,接下来会继续改造成实时的。
这里有一个细节,由于我们的数据是有时间要求的,有根据时间排序的需求,而且我们处理的数据也主要是在近期范围的(最近一天/周/月/年),所以我们希望HBase能根据记录的发布时间来排倒序,于是我们将时间戳作为HBase的rowkey拼接的第一段,但这样又引入了新的问题,记录在HBase集群上会“扎堆”,于是为了缓解这个问题,我们把发布时间的小时拿出来放在这个时间戳之前,这样局部还是根据时间排序的,暂时也不会影响到HBase节点的伸缩。
后端使用Spring Data (ES + HBase)操作数据,暂时未加入缓存机制;前端还是用AngularJS,但是做了前后端分离。现在总数据量已经达到之前的数十倍,数据请求基本在1S以内,检索查询由ES提供数据,请求基本在300ms至1s。离线批处理作业执行时间由先前的8min缩减到平均2.5分钟。
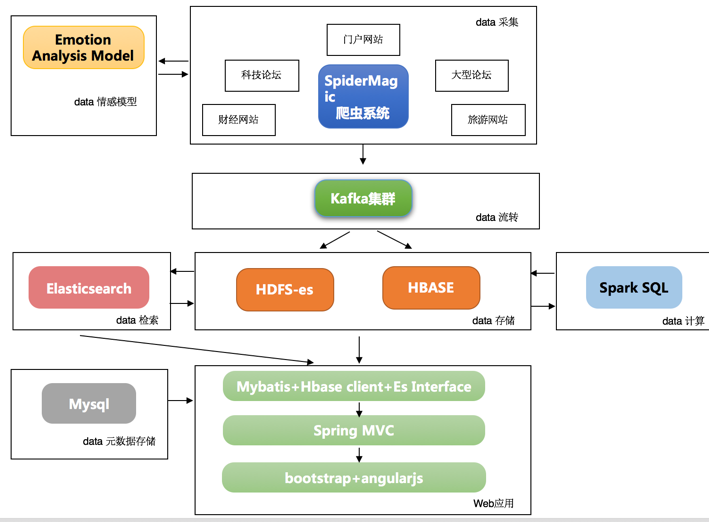
目前大数据平台未实现容器化,运行在一套CDH集群上,集群配置了高可用。Kafka和ES使用的是开源版(Spring Data的版本原因),通过使用Supervisord提高其服务的可靠性。
在这一块儿,我们下一步的目标是将大数据平台的计算部分如spark、模型算法这一块儿分离出来实现容器化,方便我们实现计算能力根据计算量进行弹性自动伸缩,我们有一套基于Mesos管理Docker镜像的测试集群,包括Spark应用和分布式的机器学习算法,这一部分正在测试中。
五、 持续部署和发布
这一块使用Gitlab + Gradle + Jenkins(docker)+ Shell脚本
Gradle:执行测试、构建、应用打包,本地调试和运行;
Gitlab: 代码仓库、代码审查;
Jenkins: 容器中运行,持续构建管理,和定期执行构建和部署;
Gitlab中设置提交触发,Jenkins设置接收触发执行Pipeline,Jenkins执行构建,调用Gradle和Shell命令执行构建;由于已做了代码和配置文件分开映射到本地,部署时复制打包代码到部署节点替换代码文件,重启容器实例完成服务部署。
作者信息:
高颜,目前就职于海航生态科技有限公司,从事大数据平台架构设计和代码编写工作。
正文到此结束
- 本文标签: REST Webapps 博客 社交网络 站点 shell cat 调试 时间 插件 微博 http 神经网络 web tomcat 互联网 UI 需求 consumer 运营 微信公众号 java jenkins 数据库 配置 代码 key 开源 统计 Quartz spring 自动化 科技 安装 API 消息队列 总结 src 下载 监控平台 目录 tab sql 管理 Docker 开发 lib 自媒体 希望 mysql Hadoop js HBase 领导 实例 参数 企业 python IO 测试 git 集群 大数据 解析 mybatis AngularJS 关键词 图片 编译 ip 网站 数据 App
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

