解说JSON 解析和生成的Python实现
解说JSON 解析和生成的Python实现
JSON 定义
JSON(JavaScript Object Notation)
JSON建构于两种结构:
- “名称/值”对的集合(A collection of name/value pairs)。不同的语言中,它被理解为对象(object),纪录(record),结构(struct),字典(dictionary),哈希表(hash table),
- 有键列表(keyed list),或者关联数组 (associative array)。 值的有序列表(An ordered list of values)。在大部分语言中,它被理解为数组(array)。
object: 
array: 
value又有以下几种 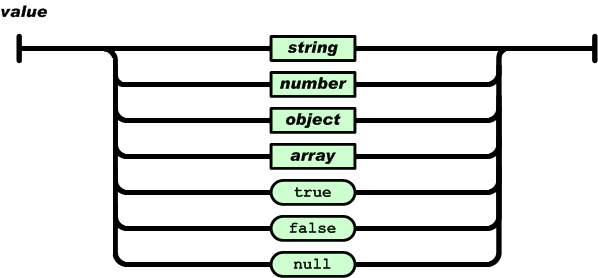
官方中文定义和说明 可以更详细。
decode
decode 就是把JSON 转成Python 的数据结构 和Python 的数据结构之间的转换关系可以定义如下:
| Python | JSON | |--------------------|--------------| | dict | object | | list, tuple | array | | str | string | | int, float | number | | True | true | | False | false | | None | null |
deocode 之前我想了如下问题:
- 输入的JSON 对Python 来说是一个字符串,这个字符串是满足上面JSON定义的,那我可以实现这个定义就好如:
[和]之间接 的转成Python list,list里面的值就转成对应类型。 - JSON 是可以嵌套的,如何才能解析这个嵌套的结构,代码该如何构建,而且object 的值可以是array,array里面又可以是object
Python 的标准实现
Python 标准库对json的实现几乎是一个独立的包,它有两种实现,默认会使用C的版本,在源码中也有纯Python的实现,当机器上没有C版本的时候就会使用纯Python的实现。其实可以去Python(我看的是3.5.1) 的源码中的Lib目录下的json 整个考出来,然后去掉所有使用c 的模块的地方 比如解析字符串的方法
scanstring = c_scanstring or py_scanstring
直接修改为:
scanstring =py_scanstring
然后整个包就是纯Python 的了,可以写个小测试在代码中Debug 查看代码的执行过程。 如果不这样做,直接看代码也是可行的,因为整个包的代码加注释也就1000多行 json 这个包结构如下:
├── decoder.py ├── encoder.py ├── __init__.py ├── scanner.py └── tool.py
写个小测试:
import json
a = {"key":{"subkey":"value"}}
json_str = json.dumps(a)
print (json_str)
b = json.loads(json_str)
最后发现loads 的核心实现在 scanner.py 的 scan_once 方法 scan_once 的逻辑是很简单的:当下一个字符是 “ 就调用 parse_string 如果是 { 就调用 parse_object .....值得注意的是,所有的parse方法都已两个参数,第一个参数是输入的JSON字符串,第二个参数是当前解析位置,就相当于有个指针在字符串上移动,指针指到字符串末尾解析结束。
def _scan_once(string, idx):
try:
nextchar = string[idx]
except IndexError:
raise StopIteration(idx)
if nextchar == '"':
return parse_string(string, idx + 1, strict)
elif nextchar == '{':
return parse_object((string, idx + 1), strict,
_scan_once, object_hook, object_pairs_hook, memo)
elif nextchar == '[':
return parse_array((string, idx + 1), _scan_once)
elif nextchar == 'n' and string[idx:idx + 4] == 'null':
return None, idx + 4
elif nextchar == 't' and string[idx:idx + 4] == 'true':
return True, idx + 4
elif nextchar == 'f' and string[idx:idx + 5] == 'false':
return False, idx + 5
m = match_number(string, idx)
if m is not None:
integer, frac, exp = m.groups()
if frac or exp:
res = parse_float(integer + (frac or '') + (exp or ''))
else:
res = parse_int(integer)
return res, m.end()
elif nextchar == 'N' and string[idx:idx + 3] == 'NaN':
return parse_constant('NaN'), idx + 3
elif nextchar == 'I' and string[idx:idx + 8] == 'Infinity':
return parse_constant('Infinity'), idx + 8
elif nextchar == '-' and string[idx:idx + 9] == '-Infinity':
return parse_constant('-Infinity'), idx + 9
else:
raise StopIteration(idx)
那些parse 又是如何实现的呢?具体的我只在这里说明parse_object 的实现。parse_object 的具体实现在 decode.py 中的 JSONObject 方法 JSONObject 首先会对下一个字符做判断,为了不陷入细节问题我把很多地方删除只留下了下面的结构,并做了注释。
def parse_object(s, end):
nextchar = s[end:end+1]
pairs = []
# 判断下一个字符的合法性
if nextchar!='"':
if nextchar =="}":
return {}, end+1
else:
# 需要字符串
raise Exception("Expecting property name enclosed in double quotes")
end += 1
while True:
# 解析出 key
if nextchar == '"':
key , end = parse_string()
pairs.append(key)
if s[end, end+1]!=":":
raise Exception("except ':' delimiter")
end += 1
# 解析value , 这里的can 方法是scanner 中的scan_once
value,end = scan(s, end)
pairs.append(key, value)
nextchar = s[end,end+1]
if nextchar=="}":
break
elif nextchar!=",":
raise Exception("Expecting ',' delimiter")
return dict(pairs)
其实最开始有个问题嵌套是如何解决的,如果是object 的嵌套object 的解析本质上就是 parse_object 的递归实现的。只不过这里的函数之间的组装方式很巧妙,根据下一个字符该干的事情都写到了 scan_once 方法里面。 具体的实现细节,无非就是字符串的操作,但是要对正则有比较高的要求,比如在解析string 的时候会用到下面的正则
FLAGS = re.VERBOSE | re.MULTILINE | re.DOTALL STRINGCHUNK = re.compile(r'(.*?)(["///x00-/x1f])', FLAGS)
STRINGCHUNK 分为两部分,分别用括号分组,第一个是所有非控制字符类容,第二个是控制字符,控制字符(control character)就是一些非答应字符可以查看 wiki .
encode
encode 就是decode 的反向过程,把Python 数据结果转换成JSON. 具体实现有兴趣的可以自行研究源码,比decode 简单。
总结
研究这种问题的好处是很多的,比如Python 代码是需要编译的,不管是什么时候编译,总要有个编译器。那和JSON 的解析是不是是类似的事情,需要把满足Python 语法格式的字符串转成目标代码? 所以些写问题本质上都是一个问题,但是编译器会复杂很多。 如果这里不是Python, 是Java, C又该有何区别呢?
如果你还在看我的blog,不去看代码那你还是别看了,我从代码里获得的东西,只看我的文章你永远学不会的。
正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

