流利说工程师带你了解 AWS re:Invent 2016
2016年11月28日,英语流利说的两位工程师前往美国拉斯维加斯参加了 2016 AWS re:Invent大会 ,该会议可谓是大数据云计算领域相关的年度盛会,现场也是精彩云集。
流利说的工程师们还在会议现场接受了北京电视台的采访:point_down::point_down::point_down:
▲流利说高级数据工程师@Haitao

▲流利说后端工程师@Tony
知道你们想看看参会回来的工程师的精彩见闻,小编 特意请来了流利说高级数据工程师Haitao和大家分享此次AWS re:Invent 2016大会的巨大收获,一起来感受一下吧。
▼

新品发布篇
本次发布会,AWS 发布了大约 1000 个特性,让人眼花缭乱,短短的几天会议,我也仅仅能参加其中的少量 session,管中窥豹,简单的从计算、存储、网络、安全和工具5个方面总结一下我所看到的:
1. 计算
云计算云计算,计算是根本。本次 AWS 在计算相关的产品发布真让人眼花缭乱。IaaS 层面:
-
James Hamilton 带大家见识了 AWS 的定制化硬件,并透露 AWS 的 IDC 45% 已经是可再生能源;
-
发布了几个其他类型的实例,其中包括 FPGA 实例,从此可以写程序创建自定义硬件加速;
-
为了方便大家更简单上手 AWS 计算资源,发布了 AWS Lightsail,号称鼠标点击几下开始 AWS 之旅。

PaaS 层面的计算产品,就更多了。
-
AWS Glue 一站式数据解决方案,配套 AWS CTO Werner Vogels 的 “The Modern Data Architecture”理论,不仅给大家提供了架构建议,也减轻了Data Infrastructure Engineer 的工作。
-
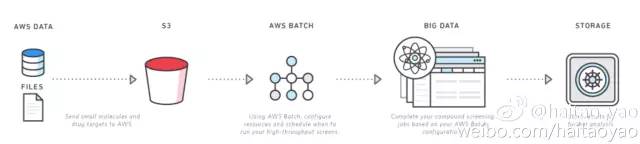
AWS Batch 作为 Producer-Consumer 模式的典型实现,大大简化了异步任务处理系统的开发,并且通过 autoscaling 自动调整计算资源,帮助节省成本。
-
喜欢 Presto 的同学也有好消息了,AWS Athena 作为一个基于 Presto 的服务,无缝与 S3 结合,零部署查询 S3 上的数据,免去了要使用 SQL 查询数据必须导入 Redshift 或者启动 EMR 集群的烦恼,按查询读取的数据量付费,童叟无欺。不过还是关注 Athena 如何暴露数据 schema 相关的 meta 信息,毕竟要构建统一的数据平台,meta 数据的关系到数据的易用性,只有了解了数据的含义,才可以正确的使用数据不是。
-
作为 AWS 的拳头产品 Lambda 也不会落后,Lambda@Edge 和 step functions 也是各种牛逼,不过作为中国区的用户,从来没用过 Lambda,就不多啰嗦了。
-
AI 最近火的不行,AWS 也发布了自己的 AI 三件套,涵盖自然语言理解、语音识别、图像识别等领域,从此 AI 服务的入门门槛降低了,解决了“他有 AI 我没有”的问题,但要在一个领域做的出神入化,就要看各家自己的内功修炼了,比如我们英语流利说是吧 :smile:。
2. 存储
今年 AWS 在存储方面,更多的是升级了原有的数据盒子 Snowball,并且发布了“数据大卡车” Snowmobile。Snowmobile 咱没有那么多数据用不起,但作为真的买过几个移动硬盘盒子快递给机房拷贝过数据的“搬运工”,Snowball 简直就是“人民的大救星”。
3. 网络
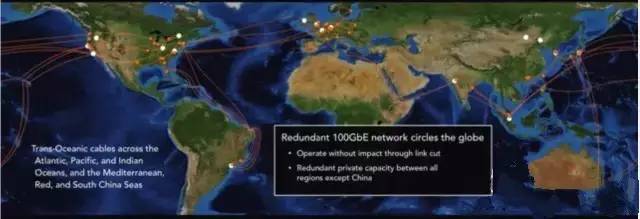
James Hamilton 宣布 AWS 自建了海底光缆,连接了大多数 AWS 的 IDC。用他的原话说这是 “really really expensive” 的事情,但他们的网络团队 100% 确信这是非常必需的,然后他们就搞了,不得不佩服 AWS 的技术实力。
4. 安全
随着越来越多的 DDoS 事件,AWS 也发布了自己的 AWS Shield 服务,帮助客户防御 DDoS。大胆预测一下, AWS 的安全产品团队应该不会仅仅做这一个产品,期待更多安全相关的产品发布,进一步加强我们在安全方面的防御能力。
5. 工具
AWS 很早就注意 API 的建设,几乎所有的服务都可以通过 API 操作,从而构建了一套生态体系,开源社区有很多工具可以供开发者选择。本次发布会工具方面我最关注 X-Ray,一个整合了所有 AWS 内部服务的 APM 服务。其实 AWS 内部应该早就有类似的服务,每次 AWS API 调用失败,都会有一个“Request ID” 的东西在错误信息里,反馈给 AWS 的支持人员,就会得到失败调用的分析,非常好用。 这次作为服务开放出来,整合到自己的应用中,每次调用失败都有关联到 AWS 服务的信息,想想都很开心。 发布会还发布了几个关于 DevOps 和开发相关的工具服务,总结来说就是“未来就需要写应用代码,其他的事情交给AWS” 的远景。
理论收获篇
Herd 时代
除了新品的发布,AWS CTO Werner Vogels又抛出一个新口号: There Are No Cattle, There Is Only The Herd。这句话源自另一个关于云计算的讨论:Pets vs Cattles,大意就是云计算之前管理 server 都像是养宠物一样,细心呵护;云计算时代了,应该像对待牲口一样对待 server,坏了就重来新启动一个 EC2 instance。现在 Serverless 成熟了,连“牲口”都不需要了,你仅仅需要关注自己的计算逻辑,Serverless 程序一部署,什么都不用管,这就是 Herd:放牧时代。Werner Vogels 还强调, Serverless 不仅仅是 Lambda,而是一大堆成熟的托管的服务,Lambda 仅仅是执行引擎。

AWS Well-Architectured Framework
AWS也更新了之前一个关于架构设计的白皮书: AWS Well-Architectured Framework 。我还是第一次读到这个白皮书,大体思路就是认为好的架构是靠5大支柱:
-
Security Pillar:安全
-
Reliability Pillar:可靠性
-
Performance Efficiency Pillar:性能效率
-
Cost Optimization Pillar:成本
-
Operational Excellence Pillar:运维
并且提到架构设计从来都是 trade-off,你可以在开发环境为了节省成本而妥协可靠性,或者在 mission-critical 环境为了 reliability 而提升了成本,但 Security 和 Operational Excellence 在大多数场景下却不是妥协的对象。真知灼见啊。 白皮书中还提到了几个设计准则,仔细琢磨一下,也有收获:
-
Stop guessing your capacity needs 不要再猜测基础设施的容量了。之前租、买主机时代,从硬件上架到上线周期很长,必须要做容量规划,避免临时资源不够用束手无策。云计算时代,按需扩容,容量规划就不怎么需要了。但我的实际经验告诉我,AWS 对每个账户是有资源上限的,避免用户手抖一下或者程序 bug 开启了大量不需要的资源。想要提升资源上限,还是要一点时间的,并不是一眨眼就可以从1台 EC2 instance 提升到 1000 台的。提前关注自己的账户的资源上限,接近饱和时及时提升一定限额是必需工作。
-
Test systems at production scale 在生产规模环境测试系统,指性能测试。但这个前提是自动化做得足够好,能够在几分钟内修改相关参数并部署一套跟生产一样规模的系统进行测试,如果自动化做的不好,模仿一套生产系统要几个小时甚至几天,这个思路就别想了,成本太高了。自动化不仅仅包含应用部署,也包含基础设施初始化。 性能测试不仅仅是环境初始化,还包括线上流量模拟回放。开源社区有 tcpcopy 等工具,录制生成环境中的流量存储下来,供后续测试回放。AWS 中我们通常会使用 ELB 作为 Load balancer,大胆猜测一下,后续 AWS 会不会在 ELB 层发布一个服务,支持将 ELB 的流量在不影响线上系统的情况下录制下来,存储到 S3,更加方便大家模拟生产环境做性能测试。
-
Automate to make architectural experimentation easier 自动化让架构实验更简单。可以关注 AWS 官方的产品 CloudFormation,或者 HashiCorp 公司开发的 Terraform。思路应该就是尽量的 Infrastructure as Code:让所有的基础设施写成代码,用 git 等版本管理起来,严格禁止手动修改基础设施。
-
Data-Driven architectures 数据驱动的架构。AWS 所有的服务都有 API,基本上所有的数据都可以采集分析,Cloudwatch 涵盖了基本上所有 AWS 服务的基础监控数据,因此数据驱动的架构就变得可行。
-
Improve through game days 通过演习提升架构。这点 Netflix 应该是做到了极致:生产环境长时间运行 Chaos Monkey,每个月演习关闭一个 Region。
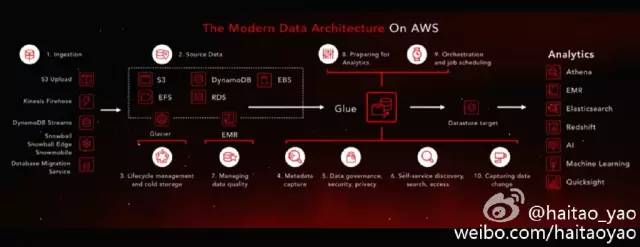
The Modern Data Architecture
英语流利说也非常注重数据平台的建设,之前我们总结了一个叫 数据三步走 的理论:
-
Data in:
-
数据从哪里来,我们应该如何收集数据。涉及到的技术包括 Apache Flume、DataX 等
-
Data processing
-
数据进来,我们首先要考虑存储问题。是选择 HDFS、S3 等文件类型的存储,还是选择 Kafka 等消息队列存储。
-
存储下来的数据就要计算,因此需要想如何用一个计算框架方便的实现计算逻辑。是 Hive、Spark、还是用 Presto?
-
随着计算的增多,计算资源的调度和计算任务的调度就成为了下一步考虑的问题。Yarn、Airflow、Azkaban 等技术走进视野,按需选取
-
Data out
-
数据到底有什么用?是作为 BI 给业务团队提供建议,还是作为产品的功能服务于用户?
-
用处的不同,又影响上面两个步骤:数据收集方案和存储计算方案的选择

我们所有的数据平台的工作,基本上都是围绕上面三个大方面展开。但 AWS 总结的更细致,将 The Modern Data Architecture 总结为10个方面,更全面的涵盖了整个数据生命周期,并且通过 AWS 的相关产品勾勒了一整套解决方案。强烈建议去看一遍相关的视频。

厂商篇
围绕 AWS 有很多厂商,本次也来参展。逛展台也是人山人海。一大堆公司围绕 AWS 生态,构建自己的企业应用。逛了很久,收获良多。

Case Study 篇
除了 AWS 自己的新品发布和产品介绍 session,还有一些重度基于 AWS 构建自身服务的公司前来助阵,比如大家熟知的 Netflix 带来了10个 session,涵盖架构、数据、网络、文化建设等多个话题,并且场场爆满,感触最深的莫过于跟 Netflix 的 SRE manager 聊天时,他透露 Netflix 部署在 AWS 3 个不同的 region 上, 每个月都会选择一个 AWS region 进行容灾演练,通过关闭该 region 中的服务,实际测试其他两个 region 是否会自动接管用户流量。感兴趣的前往 The Netflix Tech Blog 寻找相关 session 的视频链接。
拜神篇
我本人是 James Hamilton 的脑残粉,在 "Tuesday Night Live with James" 的 session 中,“近距离”膜拜了 James 大神 。 
总结
英语流利说从2014年开始就使用 AWS 的服务,转眼已经两年多了。我们不仅需要借助 AWS 构建我们的后端服务,也需要解决迄今为止超过 3.6 亿分钟用户语音数据的存储和计算问题。通过 AWS re:Invent 2016 大会,我们学习了很多其他公司的经验教训,对我们未来如何构建更好的产品,从而服务于超过3600万的流利说用户有着极大的帮助。
如果你也想跟我们的工程师们一样,每天跟 AWS 打交道,赶紧猛戳 招聘链接 。

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

