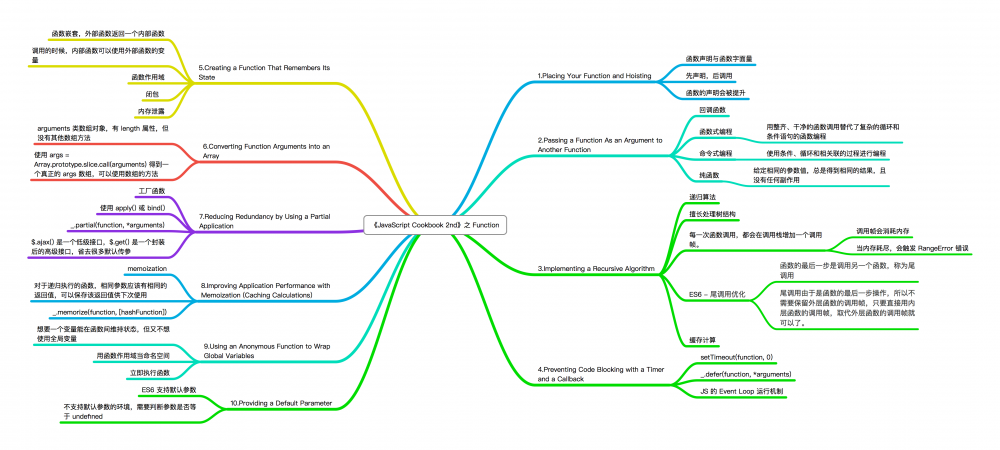
JavaScript Cookbook 2nd 之 Function
昨晚翻了一下,虽然都是一些旧知识,不过深入下去对照着其他资料一起看,还是能发现一些有意思的地方。
函数式编程
反正之前我是没搞懂函数式和命令式的区别,也很疑惑函数式编程中,如果出现分支怎么办,昨晚总算弄明白了。
// 我们有4个基础函数,会根据不同的业务逻辑进行组装使用
// 自动创建
function autoCreate () {}
// 自动同步
function autoSync () {}
// 流程 A
function processA () {}
// 流程 B
function processB () {}
// 流程 A 与流程 B 在业务上是互斥的
传统的命令式编程,我们会这样写业务逻辑
function service (errorHandler) {
var result;
if (!id) {
result = autoCreate();
if (result.error) {
errorHandler(result);
}
}
if (type === 'a') {
processA();
if (result.error) {
errorHandler(result);
}
}
if (type === 'b') {
result = processB();
if (result.error) {
errorHandler(result);
}
}
if (!isSync) {
result = autoSync();
if (result.error) {
errorHandler(result);
}
}
}
而函数式编程,我们则可以这样写业务逻辑。
// service 本身不是一个异步业务,所以直接使用 Promise.resolve() var service = Promise.resolve(); // 需要对autoCreate()等四个基础函数做 Promise 改造 service.then(autoCreate) .then(processA) .then(processB) .then(autoSync) .catch(errorHandler);
这里可能会有一个疑惑,互斥的 processA 和 processB 怎么进入了同一个处理流程,这样和需求就不符合了?
在这种情况下,我们还需要在 processA 和 processB 的内部,把退出条件补上。
function processA () {
return new Promise(function(resolve, reject){
if (type !== 'A') {
resolve();
}
// 这里继续 processA 的逻辑代码
});
}
调用栈
JS 在执行的时候,有一个函数调用栈,栈里面放着一个个的函数调用帧,这些帧保存着所属函数所需的所有变量信息。
函数调用会在内存形成一个“调用记录”,又称“调用帧”(call frame),保存调用位置和内部变量等信息。如果在函数A的内部调用函数B,那么在A的调用帧上方,还会形成一个B的调用帧。等到B运行结束,将结果返回到A,B的调用帧才会消失。如果函数B内部还调用函数C,那就还有一个C的调用帧,以此类推。所有的调用帧,就形成一个“调用栈”(call stack)。
浏览器拦截 window.open
我们发现有时候执行 window.open() ,能正常打开新窗口或者新的标签页,而有时却又不行,会被浏览器拦截。
其原因是浏览器会根据当前调用栈,找到最初的caller,如果不是用户触发的,则拦截。
尾调用优化
由于函数调用的时候会生成新的调用帧,当递归调用的时候,调用栈中的调用帧增长会非常厉害,最终导致内存耗尽而触发 RangeError。
如果把函数调用放在函数块的最后一条语句,且不在使用外层函数的变量了,则外层函数所占用的调用帧已无存在意义。在进入内层函数的时候,可以直接用内层函数的调用帧替换掉外层函数的调用帧,从而大大减少内存占用。
其他
Partial Application 的模式,用来做 Library 和 SDK 都挺好的。一个可定制性高的底层接口,再通过类似 _.partial() 的方式,提供一个开箱即用的上层接口。就像 $.ajax() 和 $.get() 一样。
_.defer() 和 _.memoize() 可以用在有大运算量的业务场景。
正文到此结束
热门推荐










相关文章

近期评论
-
收到
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
-
不会英语啊。
-
-
-
https://pplx.ai/floraliu4199466 这个链接打不开是什么原因?
-
-
-
-
来看看,最近更新了一波,顺着友联过来的,几年过去了,网站越搞越好,厉害
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

