COS沙龙第40期(北京)纪要
数据科学三原则:可预测性,稳定性和可计算性
嘉宾:郁彬
主办:统计之都、中国人民大学统计学院、中国人民大学统计与大数据研究院
场地:中国人民大学逸夫会议中心第一报告厅
纪要:杨舒仪 李宇轩

简介:郁彬,加州大学伯克利分校统计系及电气工程与计算机科学系校长教授,加州大学伯克利分校统计系前系主任。她同时是北京大学微软统计与信息技术教育部-微软重点实验室的创办者及联席主任。她与基因组学、神经科学、医学领域科学家合作进行跨学科研究,开发了统计和机器学习方法/算法和理论,并与领域知识以及量化批判思维结合以解决这些领域中的数据问题。
郁彬教授是美国国家科学院和美国艺术与科学学院两院院士。2006年当选Guggenheim Fellow,2011年受邀在ICIAM(The International Council for Industrial and Applied Mathematics,国际工业与应用数学大会)作特邀演讲,2012年作了伯努利协会的图基纪念演讲(Turkey Memorial Lecture of the Bernoulli Society),2016年作IMS(Institution of Mathematical Statistics,数理统计协会)Rietz演讲。郁彬教授曾于2013-2014年出任IMS主席,也是IMS、ASA(American Statistical Association,美国统计协会)、AAAS(American Association for the Advancement of Science,美国科学促进会)和IEEE(Institute of Electrical and Electronics Engineers,电气和电子工程师协会)的会士。
在该演讲中,郁彬老师将讨论在数据驱动决策中的数据科学三原则的重要性和其相互关联。预测的终极重要性在于,未来是所有人类活动独特且几乎唯一的目的,无论是商业、教育、研究或是政治等任何方面。
以预测为目标,以计算为核心,机器学习让数据驱动取得了广泛的成功。预测是检验现实的有效方法,而好的预测都隐含着一个假设:过去和未来之间的稳定性。稳定性(相对于数据和模型的扰动)也同时是数据驱动结果可解释性和可重复性的最低要求,它与不确定性评估密切相关。同时,可预测性和稳定性还都需要建立在可行的计算算法基础之上,因此可计算性也是十分重要的。
郁彬老师通过两个正在进行的关于“数据智慧”的实际项目来说明这三个原则。第一个项目采用深度学习网络(CNNs)来研究神经元在不易理解的视觉皮层V4的模式选择性;第二项目通过采用和比较不同的潜变量模型以及基于Lasso的模型来预测政治电视广告中的党派和语气。
下面是对沙龙主要内容的回顾:
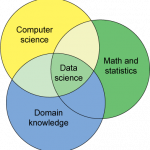
什么是数据科学?首先,数据科学由人来做,应当先做人在做数据科学。统计是数据科学的一大支柱。郁彬老师将解决数据问题比作寻求宝藏。她谈到,数据是寻宝的队伍,数据质量是寻宝队伍里人的认真程度,数据精度是寻宝队伍里人的能力和设备的好坏,数据问题的解是宝藏,而问题难度是寻宝场所地形大小和复杂度。虽然当今大数据处处皆是,但“大”一词应是相对于问题的难度而言的,同时数据的质量、精度也是关键。从相对容易的机器语言翻译,到人工智能、精准医学等领域,数据问题的难度在不断递增,我们对数据的质量、精度的需求也在不断提高。而我们所掌握的专业知识,可以顶数据、提供模型表达式、缩小搜索空间,从而减少问题的难度,同时分析数据又是为了获取更多知识。
https://www.ibm.com/developerworks/library/os-datascience/figure1.png
数据科学是统计学与计算机学的再度携手共进,是解决大数据问题的科学。对此,郁彬老师给出了一个公式:数据科学三元素+给力团队+验证=解决数据问题/获取知识/做决定。首先,数据科学三元素是指:计算机学、统计学/数学、专业知识。其次,解决问题需要组队,因此我们需要发现并抓住机会,要注重传统交流方式,并学会解决冲突。最后,“验证”也十分重要,尤其是在精准医学等领域。
接下来,郁彬老师回顾了统计学发展史,介绍了四位统计先驱:Herman Hollerith、R.A.Fisher、J.W.Tukey和Leo Breiman。她强调,在解决问题的过程中,我们能够超越前人的框架,因此问题应该驱动统计进化、前行。我们应该流淌着科学家的血液,必须继承科学家的思维方式和求实精神,并提出统计应该不限于建模型,应该采用多样工具。
郁彬老师认为,人通过数据智慧做数据科学,而数据智慧是整合数据、统计方法和专业知识之间的联系的人的思辨能力。在验证统计理论的过程中,要注意考察其预测效果、稳定性/可解释性,尝试用专业领域的知识证明、做基于程式化模型的模拟以及探索性数据分析(可视化)。
为什么会有数据科学三原则呢?作为新兴科学,数据科学需要基本的概念与原则的支撑,以便人们交流和传递经验。同时,数据科学的三原则彼此紧密关联。预测是检验现实的有效方法,而好的预测都隐含着一个假设:过去和未来之间的稳定性。稳定性(相对于数据和模型的扰动)也同时是数据驱动结果可解释性和可重复性的最低要求,它与不确定性评估密切相关。如今预测和计算已经成为机器学习的基石,而机器学习或者说统计的前沿之一是逐渐注重解释性。同时,稳定性是科学可重复性的最低要求,目前的统计发现普遍存在着错误和虚假问题,使得稳定性变得越来越重要。而可预测性和稳定性都需要建立在可行的计算算法基础之上,因此可计算性也是十分重要的。
随后,郁彬老师通过两个正在进行的关于“数据智慧”的实际项目来说明这三个原则。第一个项目与影像重构相关,采用深度学习网络(CNNs)来研究神经元在不易理解的视觉皮层V4的模式选择性;第二个项目与文本挖掘有关,通过采用和比较不同的潜变量模型以及基于Lasso的模型来预测政治电视广告中的党派和语气。
最后,郁彬老师谈到了研究的原义:研究重在过程而不在于目的,不是为了写文章,而是为了理解与分享。对于学院研究,郁彬老师认为:理想模型下的渐进理论对于统计实践而言,是统计在计算机时代之前的计算平台。好的统计理论要对实践给予解释、指导,作为数学的理论统计应向Fields奖看齐。而我们需要的现实统计模型,来源于专业知识。
提问环节精彩花絮:
1. 问 :可解释性很重要,但是神经网络是难以解释的,请问老师应该如何看待这个问题?
答:它的确需要可解释性,所以我们需要将它可视化,然后找不同的模型里稳定的那部分信息去解释。
问:据我所知的可视化,就是说将一些部分用图像来解释,但是还是有一部分不太能解释,而且我们难以让这部分解释在很短时间内进步的很快,其实我个人感觉对这个不是很有信心,不知道老师怎么看?
答:我觉得还是很有希望的,我们在这部分是有一些科学实践的,不过是质量性的,不是数量性的。需要有专业知识能做到简单明了,然后这个深度学习告诉我们“预测”能到什么程度。之后另起炉灶,建立一个生物上可解释的模型,去匹配这个“预测”的情况。
2. 问 :刚才老师讲到,理论统计这方面应该是向菲尔兹奖看齐,我了解到有一些前沿的人是用代数几何的方法来分析统计的,然后他们出了一本书,非常酷炫,我看了一下,但我很难理解它到底是有什么用呢?
答:我没有看到有什么用。
问:那他们为什么还会做这方面的东西?
答:那些数学家中有一个主力是我的同事,他就说其实就是相当于努力在从数学做到实际,但是不是每次努力都会成功的,但是还是要鼓励他们去努力,他们至少努力在和实际结合。
问:那您觉得,这方面的研究,未来会变得很好吗?
答:我不会压在这个上面。这种事情很难预料,但是我打赌肯定不会打到这个上面。
3. 问 :您好,如果想要成为数据科学家的话,在已经了解了很多经典算法的基础上,还应该学习哪些?我在做项目的时候,清洗数据可能占到了80%~90%的精力。
答:你的经历也是我的学生的经历,我没有这些经历,我靠理论支撑过了那段时间。首先你的编程能力要和计算机系的一样,然后你要学会思辨能力,就是公司里的人要能淘到一些别人淘不到的专业知识,另外机器学习所有的基本大略的方法都要有了解。就是说,统计和计算机的交叉部分几乎是二合一的,就是机器学习这部分,所以他们懂的你也得懂,知己知彼。此外永远要挑战自己,每个人能力不同,情况不同,不要一定给自己找难题,套枷锁,这样你就不会得老年痴呆。这是我比较担心的一个问题。
问:我可以这样理解吗,就是说后面最大的问题就是把自己需要的知识用到实际问题上,多做一些项目、比赛等?
答:我是最不喜欢比赛的,我的组很少参加比赛。首先我不喜欢deadline,我喜欢慢慢自己想东西,所以我做老师比较喜欢找冷门,我不愿意在大家一拥而上的时候去做事情,因为我需要心静想问题。所以我比较喜欢自己慢慢想问题,再找人去做。但是可能比较前沿,就是五年以后比较重要的问题。但是这个在于对知识的好奇心一定要非常广,有些东西都是相连的,我现在觉得我现在学的东西都是连在一起的,我记得我当时有学生老不去讨论班,当时我还是系主任,对他们的学生会系主席说,为什么同学都不去讨论班,系主席说同学都想优化自己的时间,然后我说你连这个Domain都不知道,怎么搞优化。因为你知道的很少,这个世界很大,你都不知道怎么搞优化?所以面一定要铺得广,当然这个也和你自己的兴趣,精力都有关系,我是因为很喜欢人,所以当老师,什么样的人都喜欢,喜欢就学很多东西,但圈子转来转去就那么几个人。所以每个人都不一样,要知道什么对自己合适,但永远要给自己挑战,就是不要太舒适,我就喜欢这样,要知道自己的弱点,然后去挑战自己的弱点。快慢不要紧,关键在于坚持。
4. 问 :我想问一下,去年有人写了一篇关于纪念数据科学五十年这样的文章,他也提到了一些统计的新的方法,您今天提到了三原则,您觉得您所提的和他的几个方向之间有什么关系?
答:我还真没记住他那篇文章写了什么,你给我提醒一下那篇文章。
问:他那里面有一个提到了语言分析,就是说统计的一些传统的方法,以及会有一些新的算法加入其中,另外他谈到了跨学科的合作。他的方向都比较具体。
答:因为他没在做我在做,我还想反问一下:为什么你就觉得他的一定是对的呢?
问:我没有觉得他是对的,我只是说,在我们今天一起来探讨数据科学和统计的发展和未来走向的时候,我们有很多老师,都在思考这个问题。
答:这个问题我也是比较注重,所以虽然我没记住但我也是看了,我觉得我很喜欢历史的那部分,但是前言这部分,我是更会去欣赏前沿正在做这些的老师的意见。因为我觉得那个老师还主要是数学家。
问:我今天主要受到两个启发,第一个就是数据化这个方向,第二个就是有选择地增加对问题在预测和建构方面的可能性,这两个是您主要提到的,所以我在想,这两块会不会也会成为未来统计学里的一个核心,您是这样认为的吗?
答:我要不这么认为,就不会这么做了。统计,至少学院的统计,对经验的重视不够。大家就老老实实做事情,东西自然就出来了,不要去提出很多没有经验支撑的框架。
问:我感觉这个有点难,难点在于跨学科的问题。
答:就是不难也得这样去做,统计从来都不是一个逻辑的东西,是一个实践的东西,我没有灵丹妙药,我只是在分享经验。我觉得经验对统计现在这个时期非常重要,所以我建议大家都去实践,我们再回来的时候就会有很多的东西可说可做。
5. 问 :郁教授您好,我是统计博士的新生,我想问一下,您有没有几门具体的计算机课程能推荐给我们?
答:对,有两个课,在伯克利的网站上有,是Computer Science,61AB,一门是Program Language,一门data structure。这两门课网上都有,我希望我的博士生能把这两门课都上了,这两门是本科的课,但是非常基本,尤其老师是一位特别好的老师。
6. 问 :郁彬老师你好,我是已经毕业了三年多了,虽然很想申请PhD的,但是由于某些事情,不得不进入工业界。有一个问题就是EDA对于模型来讲的话价值在哪里?
答:EDA就是我每次教统计课程候,经常觉得不好看,高维数据很多很难可视化,另外我发现很多可视化软件不是统计学家,而是艺术家在做。所以我们这个统计没有把计算机的本领加进来,其实它是像movie这样看的,就是说把高维数据当成图像来看。我还没有讲,是因为我想用的多一点再出来讲。但只是一个小小的努力,我觉得更大的努力实际上是有很多软件,都是其他人,比如计算机的人写的,但还没有把这些融入到统计里面。就是说R里面都是比较简单的东西,我觉得是需要三维,电影啊这些来呈现的。比如生物就是这样,我现在看生物都是上YouTube,Google看视频,而读生物书很头痛,他们现在在尝试用电影写生物书,但都不是统计人在搞。这就是我们统计人计算机功底有缺陷,所以走不进去,就如同visual reality一样,可视化最后还是会和visual reality走在一起,但我们统计人做的很少。
7. 问 :我是来自计算机背景的,我在工作的时候深刻体会到了统计的重要性,所以我想问一下就是现在如何更好地吸取统计的营养?
答:我觉得就是要读经典,就是读之前的著名统计学家的著作。
问:如果说沿着统计本科,研究生这样一个过程下来,时间是很长的,就是有没有什么特别快的办法?
答:最近那个历史学家Stephen Stigler写了一本书叫做seven pillars of statistical wisdom,我觉得那个书总结很好的。我觉得统计的精华不是计算,是ideas。但是现在统计有的人把数学放的太重了,数学很有用,但是需要斟酌比例问题,现在缺的是好的数学工具来解决问题,但更缺的是ideas。
8. 问 :我在做工业界的事情,我在工作的过程中遇到了一些困难,就是做一些机器学习的问题的时候,发现我只需要拿到我这个需要的参数,对它求一个我自己需要的综值,然后这个模型就可用了,之后再调整。这样的话我就感觉我之前做的一些复杂的模型都有些失效了。
答:这不很好吗?大彻大悟,最后的事情应该都是简单的,你应该庆祝,不应该困惑。简单的能解决问题就是要比复杂的要好。
问:但是向领导报告的时候,就不是很合适。
答:那你需要去教育你的领导,简单就好,你也可以用一些大家说的话去镇住他。
报告后,郁彬老师就现场参会者们提出的疑问进行了幽默细致的解答,并在结束后与大家继续热情地讨论,本次沙龙圆满结束。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

