基础深度学习概念备忘录
基础深度学习概念备忘录 翻译自 DeepLearning Cheat Sheet 。笔者还是菜鸟一枚,若有谬误请多多赐教,另外如果希望了解更多机器学习&深度学习的资料可以参考笔者的 面向程序猿的数据科学与机器学习知识体系及资料合集 以及 程序猿的数据科学与机器学习实战手册 。

深度学习可能对于很多初学者是一头雾水,在高速发展的同时有很多新的概念名词被抛出,而本文则是对一些常见名词的备忘介绍。
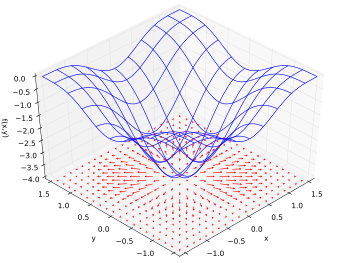
Gradient ∇ (微分算符):梯度
梯度即是某个函数的偏导数,其允许输入多个向量然后输出单个值,某个典型的函数即是神经网络中的损失函数。梯度会显示出随着变量输入的增加输出值增加的方向,换言之,如果我们要降低损失值则反梯度逆向前行即可。
Back Propagation:反向传播
简称为Back prop,即将前向传播输入值计算得出的误差反向传递到输入值中,经常用于微积分中的链式调用。
Sigmoid σ
用于将神经元的输出结果限制在 [0,1] 范围内的阈值函数,该函数的输出图形看起来有点像 S 型,在希腊语中就是所谓Sigma。Sigmoid函数是Logistic函数的某个特例。
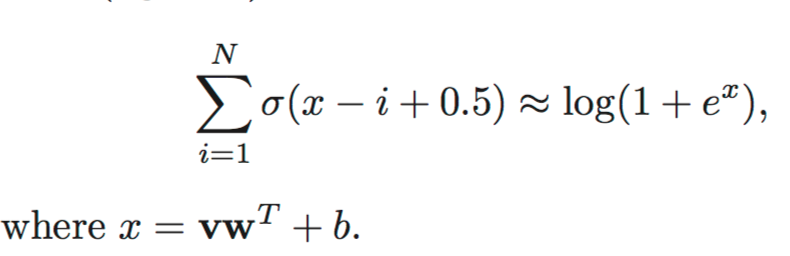
Rectified Linear Units or ReLU
Sigmoid函数的输出间隔为 [0,1] ,而ReLU的输出范围为 [0,infinity] ,换言之Sigmoid更合适Logistic回归而ReLU更适合于表示正数。深度学习中ReLU并不会受制于所谓的梯度消失问题(Vanishing Gradient Problem)。
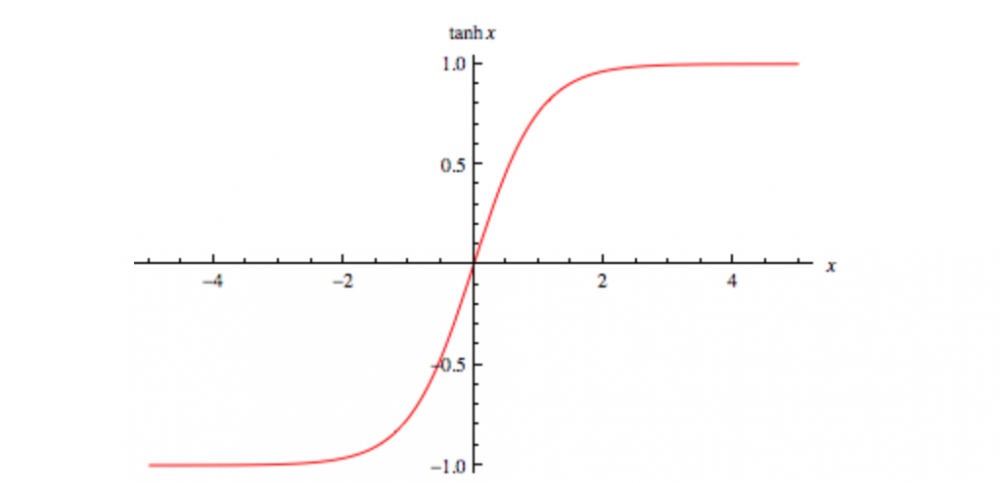
Tanh
Tanh函数有助于将你的网络权重控制在 [-1,1] 之间,而且从上图中可以看出,越靠近0的地方梯度值越大,并且梯度的范围位于 [0,1] 之间,和Sigmoid函数的范围一致,这一点也能有助于避免梯度偏差。
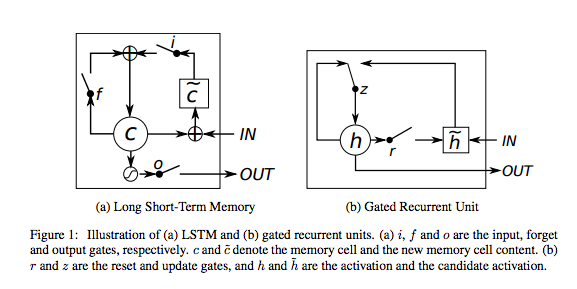
LSTM/GRU
最早见于Recurrent Neural Networks,不过同样可以用于其他内存单元较少的地方。其主要可以在训练中保持输入的状态,从而避免之前因为RNN丢失输入先验上下文而导致的梯度消失问题。
Softmax
Softmax函数常用于神经网络的末端以添加分类功能,该函数主要是进行多元逻辑斯蒂回归,也就可以用于多元分类问题。通常会使用交叉熵作为其损失函数。
L1 & L2 Regularization
正则化项通过对系数添加惩罚项来避免过拟合,正则化项也能够指明模型复杂度。L1与L2的区别在于L1能够保证模型的稀疏性。引入正则化项能够保证模型的泛化能力并且避免在训练数据中过拟合。
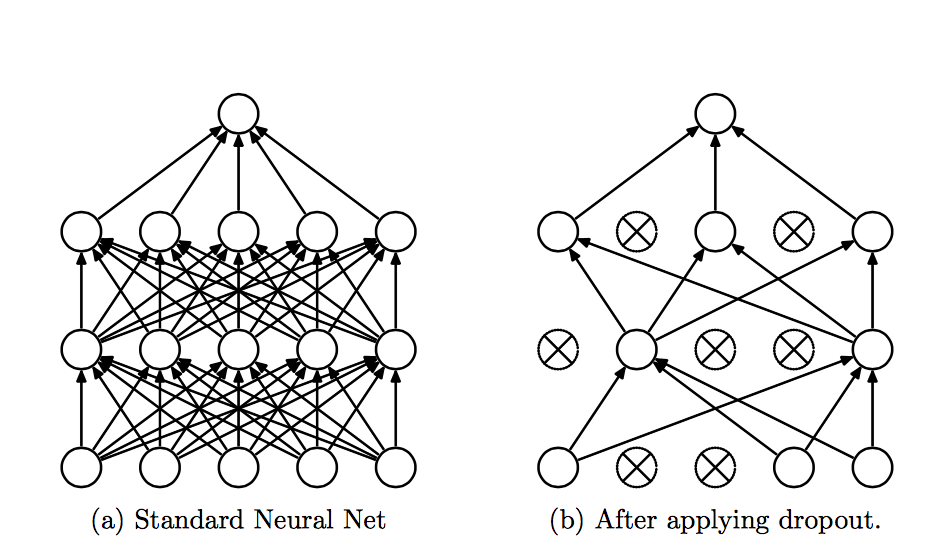
Drop out
Drop out同样可以避免过拟合,并且能以近似指数的时间来合并多个不同的神经网络结构。该方法会随机地在每一层中选择一些显性层与隐层,在我们的实践中通常会由固定比例的层Drop out决定。
Batch Normalization
在深度学习中,如果有太多的层次会导致所谓的Internal Covariate Shift,也就是训练过程中因为网络参数的变化导致网络激活分布的变化。如果我们能减少这种变量迁移,我们能够更快地训练网络。Batch Normalization则通过将每个处理块进行正则化处理来解决这个问题。
Objective Functions
也就是损失函数或者Optimization Score Function,某个深度学习网络的目标即是最小化该函数值从而提升网络的准确度。
F1/F Score
用于衡量某个模型的准确度的标准:
F1 = 2 * (Precision * Recall) / (Precision + Recall) Precision = True Positives / (True Positives + False Positives) Recall = True Positives / (True Positives + False Negatives)
Cross Entropy
用于计算预测标签值与真实标签值之间的差距,基本的定义如下:
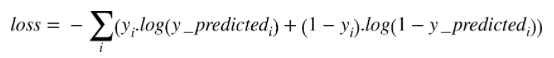
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

