NIPS 2016:机器学习的盛典

NIPS大会总览:
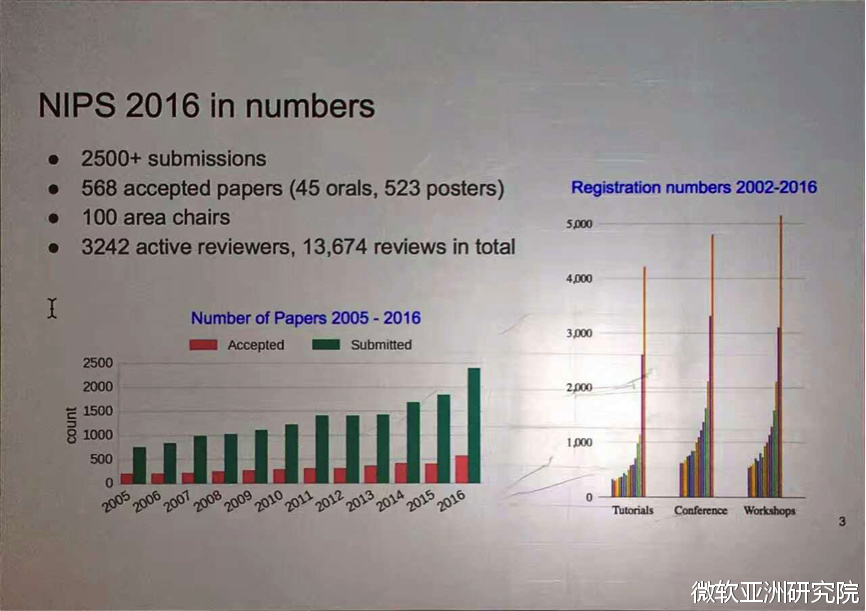
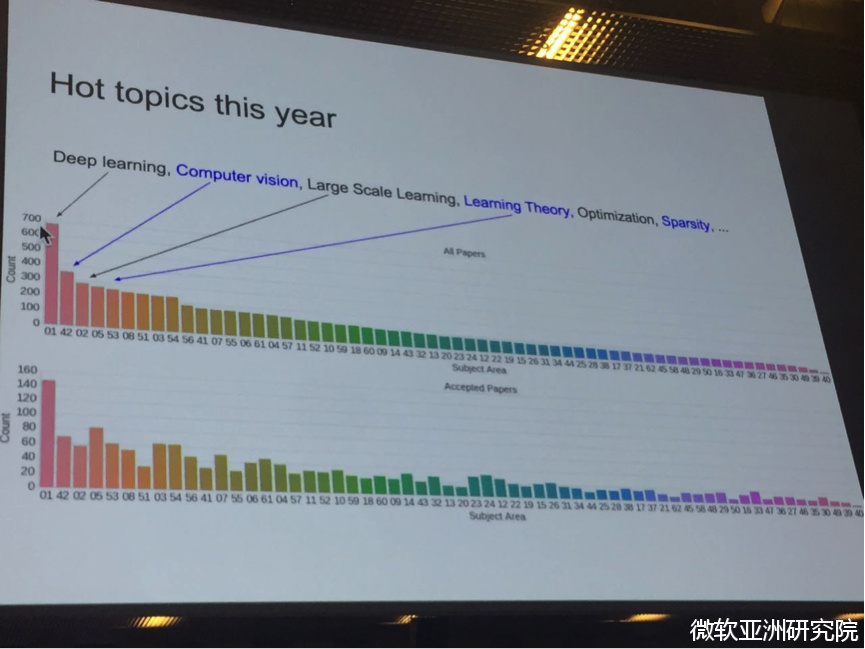
神经信息处理系统大会(Conference and Workshop on Neural Information Processing Systems),简称NIPS,是一个关于机器学习和计算神经科学领域的顶级国际会议。该会议固定在每年12月举行,由NIPS基金会主办。今年第30届的NIPS可谓火爆异常,初期就有2500篇投稿,涉及3000多位审稿人,最终录取568篇,总体接收率23%,其中包含深度学习、计算机视觉、大规模机器学习、学习理论、优化、稀疏理论等众多领域的文章。
本次NIPS大会在巴塞罗那举行。巴塞罗那(Barcelona)位于伊比利亚半岛东北部,濒临地中海,是西班牙第二大城市,也是加泰罗尼亚自治区首府,以及巴塞罗那省(隶属于加泰罗尼亚自治区)的省会。巴塞罗那是加泰罗尼亚的港口城市,是享誉世界的地中海风光旅游目的地和世界著名的历史文化名城,也是西班牙最重要的贸易、工业和金融基地。巴塞罗那气候宜人、风光旖旎、古迹遍布,素有“伊比利亚半岛的明珠”之称,是西班牙最著名的旅游胜地。当然,巴塞罗那还有更加世界闻名的足球俱乐部:巴萨。想必广大球迷都曾经被煤球王(梅西)和巴萨的颠覆时代所深深折服。


2016年的NIPS大会于12月5日至12月10日在巴塞罗那国际会议中心举行。大会获得了包括微软在内的多家知名IT企业的大力赞助,各大赞助商的总数接近上百个。今年共有5800多名来自世界各地的研究人员和机器学习实践者注册并参加了会议,这个注册数量创造了历届之最,而且相比于往年有近乎指数级增长的趋势。



大会主要分为4个部分,包括一天的教程(tutorials)、 3天的大会会议(conference sessions)、一天的专题研讨会(symposia)和两天的研讨会(workshops)四个部分。因为参与人数众多,偌大的会场也被挤得水泄不通。
周一的教程覆盖了机器学习领域的各个研究热点,如深度增强学习(DRL)、生成式对抗网络(GAN)、大规模优化、变分推断、众包、自然语言处理、非平稳时间序列、精准医疗及医疗保健、如何在实际中构建深度学习AI系统。
周二至周四的大会会议包含了口头报告(oral presentation)、海报展示(poster session),并在中间穿插了特邀报告(invited talk)。卷积神经网络的发明人Yann Lecun在他的特邀报告中依然大力推动predictive learning(可理解为一种更广义的无监督学习),希望广大的学者不断探索从未标注的数据中学习的边界。DL(深度学习)以及与深度学习紧密相关的技术如GAN(生成式对抗网络)、DRL(深度增强学习)等依然是本届大会最热的话题和关注点。今年NIPS评选的最佳论文是 《Value Iteration Networks》,由加州大学伯克利分校 Aviv Tamar、吴翼等人完成的。这篇论文介绍了一个新的不是基于模型的(model-free)强化学习观。在文章中,区别于传统的深度强化学习采用神经网络学习一个从状态(state)到决策(action)的直接映射,他们引入了在当前环境下做长远的规划(learn to plan)的机制,并利用长远的规划辅助神经网络做出更好的决策。最佳学生论文是《Matrix Completion has No Spurious Local Minimum》,由Rong Ge、Jason D. Lee、Tengyu Ma完成。这篇论文证明了半正定矩阵补全问题中的目标优化函数没有局部极值点,也就是说所有的局部极值点都是全局极值点,因此很多广泛使用的优化方法例如随即梯度下降方法从任意初始点出发都可以在多项式时间找到该问题的最优解。
本次大会还有一大学习理念被多次提及:Meta-learning。Meta-learning这个概念在很早的时候就已经有了,随着深度学习、增强学习技术全新的发展,这个概念也再一次地得到了升华。它的核心思想就是利用一个小的子学习过程来辅助主学习目标,例如learning to learn以及Fast Reinforcement Learning via Slow Reinforcement Learning都是核心代表作。
NIPS今年有3个专题研讨会(symposia)和52个研讨会(workshops)。由于其对机器学习各领域覆盖的广泛性以及对每一个专题讨论的深入性,吸引了众多人员的参与。NIPS一个很重要的特色就是workshop甚至比大会更受欢迎,实际上,workshop的注册人数也要多于大会的注册人数。无论你是做机器学习的哪一个方面,相信你都会找到你感兴趣的研讨会。另外,很多研讨会都有视频录像,应该会在近期放在网上,感兴趣的读者可以自行搜索观看。
微软在NIPS
本次微软在NIPS的表现非常亮眼,参与组织了9个研讨会,并在大会发表了超过20篇论文。其中,我们微软亚洲研究院的机器学习组共有3篇不同方向的论文入选。其中一篇工作提出了一种新的学习范式:对偶学习,并将其成功应用于机器翻译的任务上;另一篇工作关于如何通过分布式投票减少直方图的传输,从而实现高效的并行GBDT训练,是LightGBM开源工具的一部分;还有一篇就是我在微软亚洲研究院秦涛导师的指导下完成的关于轻量级递归神经网络LightRNN,通过引入行列共享表示(row-column shared embedding)同时做到大大缩小模型的计算和存储复杂度而又保证其性能。下面我们就依次介绍一下这三篇工作:
Dual Learning for Machine Translation:
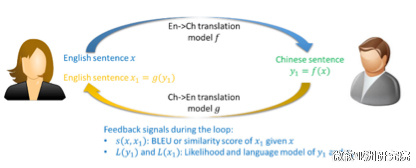
对偶学习(dual learning)是一种新的学习范式,它和已有的学习范式监督学习(supervised learning)、半监督学习(semi-supervised learning)、多任务学习(multi-task learning)、迁移学习(transfer learning)有很大的不同。它有两个核心要点:1. 对偶学习作用在一个闭环的平行的学习任务之上,我们同时学习AàB和BàA的映射并且两个任务相辅相成;2. 通过对偶学习,能够将大量的未标注的数据利用起来,使我们得以从未标注的数据上获得反馈信息,进而利用该反馈信息提高对偶任务中的两个机器学习模型。
具体到翻译模型的问题上来,考虑一个对偶翻译游戏,里面有两个玩家小明和爱丽丝,如下图所示。小明只能讲中文,爱丽丝只会讲英文,他们两个人一起希望能够提高英文到中文的翻译模型f和中文到英文的翻译模型g。给定一个英文的句子x,爱丽丝首先通过f把这个句子翻译成中文句子y1,然后把这个中文的句子发给小明。因为没有标注,所以小明不知道正确的翻译是什么,但是小明可以知道,这个中文的句子是不是语法正确、符不符合中文的语言模型,这些信息都能帮助小明大概判断翻译模型f是不是做的好。然后小明再把这个中文的句子y1通过翻译模型g翻译成一个新的英文句子x1,并发给爱丽丝。通过比较x和x1是不是相似,爱丽丝就能够知道翻译模型f和g是不是做得好,尽管x只是一个没有标注的句子。因此,通过这样一个对偶游戏的过程,我们能够从没有标注的数据上获得反馈,从而知道如何提高机器学习模型。
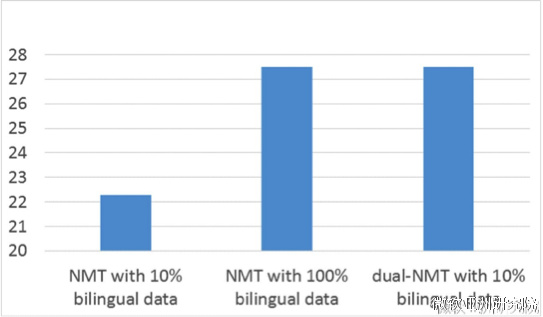
在论文中,我们通过对偶学习仅使用了原训练语料10%的数据,然后利用大量未标注的数据,就达到甚至超过了原来的神经网络翻译模型(NMT)使用100%训练语料的最好结果。(详情请戳: 研究|对偶学习:一种新的机器学习范式。 )
A Communication-Efficient Parallel Algorithm for Decision Tree:
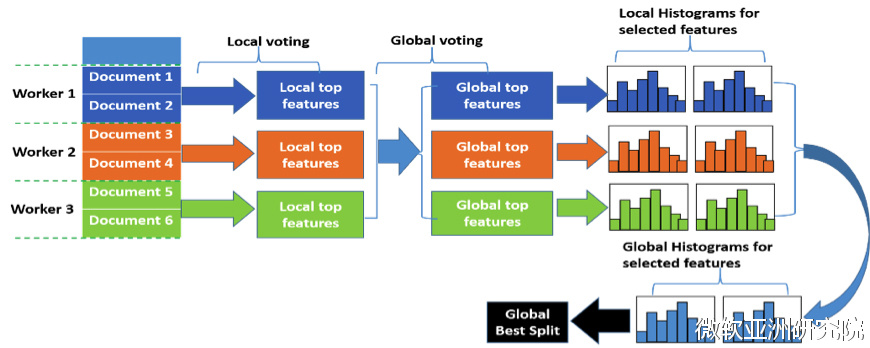
决策树是一种被广泛应用的机器学习算法。由于数据量的增大,为了提高训练效率,并行决策树算法的研究是十分有必要的。现有的并行决策树算法通讯代价通常较大。我们提出了一种基于投票的并行决策树算法pv-tree 算法(parallel voting tree),能够在保证准确率的前提下,有效降低通讯代价。
pv-tree 算法采用数据并行,每台机器存储一部分数据本地训练,用直方图来记录不同特征的信息量以及最佳分裂点。然后选出k个信息量最大的特征。然后在所有local的k个特征中根据majority vote选出2k个特征。对这2k个特征合并直方图,计算准确的信息量,而后选出最优的分裂特征以及其分裂点。所有机器用最优分裂特征继续训练。
投票的方法与无损的并行方法相比大大减少通讯,我们对投票方法的准确率进行了理论刻画,证明了以高概率pv-tree可以选到最优的特征。实验效果也很好的验证了pv-tree算法是准确、高效的算法。我们团队还开源了世界上最为快速、准确的分布式决策树算法lightGBM,大家可以从github上使用和开发。我们会在新版的lightGBM上加入pv-tree的特性,让算法变得更加高效。
LightRNN: Memory and Computation-Efficient Recurrent Neural Networks
我们的研究主要解决递归神经网络(RNN)应用于自然语言处理任务中面对的一个巨大挑战:当应用于大词汇的文本语料库时,模型的体量将变得非常大。比如说,当使用 RNN 进行语言建模时,词首先需要通过输入矩阵(input-embedding matrix)从 one-hot 向量(其维度与词汇表大小相同)映射到词向量。然后为了预测下一词的概率,通过输出矩阵(output-embedding matrix)将隐藏层投射到词汇表中所有词的概率分布。当该词汇表包含数千万个不同的词时(这在 Web 语料库中很常见),这两个矩阵就会包含数百亿个不同的元素,这会使得 RNN 模型变得过大,从而无法装载进 GPU 设备的显存进行训练。

解决这一问题最核心的思想就是参数共享(parameter sharing)。我们所研究的这一解决方案是通过引入一个二维词表来处理的。我们将词汇表中的每一个词都分配到一个格子中,其中每一行都关联了一个行向量,每一列则关联了一个列向量。根据一个词在表中的位置,该词可由行向量和列向量联合表示。因为该表中同一行具有相同的行向量,同一列具有相同的列向量,所以我们仅仅需要2√|V|个向量来表示带有|V|个词的词汇表,这远远少于现有的方法所需要的向量数|V|。如下图左边,根据二维词表我们实现了一种新的LightRNN结构,它区别于传统的RNN结构(见右边)。
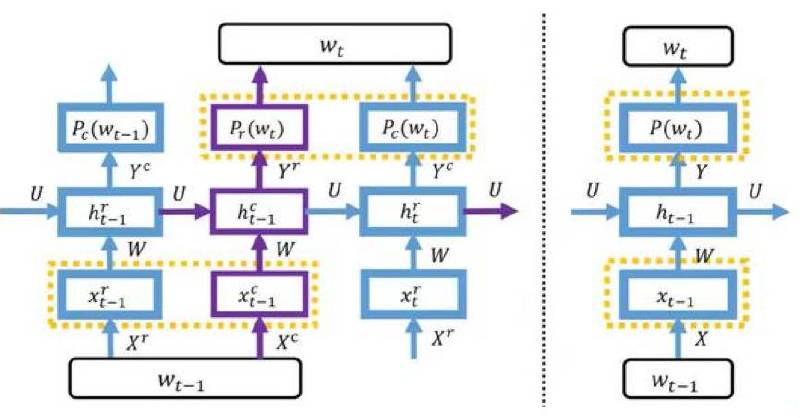
同时我们的算法也是迭代优化的。(1)首先随机初始化词在二维词表中的分配(word allocation),并训练 LightRNN 模型。(2)固定训练后的向量,然后细化分配来最小化训练损失,这一步可以被转化为一个图论(graph theory)最小权重完美匹配问题,能够被有效地解决。(3)重复第二步,直到满足一定的终止标准。
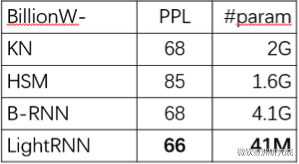
最终我们在非常多语料的标准的数据集上对语言模型做了评估。我们发现,LightRNN相比于以前的模型减少了参数大小高达百倍,同时得到了无损甚至更好的精度。

下图是我们在参与poster讲解的现场。

曲折的探索
回忆当初开展这项研究的几个月,那真是一段曲折而难忘的过程。刚开始我们就确定了利用二维词汇表做参数共享的思路,但是最开始设计的网络一直无法达到正常的测试结果,性能表现异常的差。根据最初的构想,有一个非常直观的方式就是利用行共享向量和列共享向量直接连接作用于输入和输出,然后实验发现网络根本没法训动。在导师的指导之下,尝试使用递归神经网络RNN中的信息流链接,增加行与行、列与列之间的关系,可是效果也一直不太满意。围绕这些想法开展了将近一个月的实验,始终没有起色。于是开始进入大脑风暴状态,将导师和我的讨论不断汇总、打磨、不分昼夜的思索,终于从序列性原理的角度取得了突破。最终,我们采用行列交替的方式,不打破序列的连续性而同时能够得到更好的训练和测试性能。
作者简介

我叫李翔,曾是微软亚洲研究院的一名实习生,就读于南京理工大学,攻读人工智能博士学位。我的研究兴趣是数据挖掘和基于深度学习的自然语言处理与计算机视觉。
在微软亚洲研究院接近一年的实习经历让我收获颇丰。在这里,不仅有认真负责的导师,和导师们的一次次细节的探讨和摸索中不断总结出问题的本质,还有充满天赋和干劲的实习生们,我们一起组织饭团,一起畅想学术方向,一起研究和讨论新的方案。在导师和同学们身上,我学到了很多,关于如何寻找具有影响力的学术方向、如何把握问题的关键点、如何将研究上升到方法论的高度以及如何进行团队合作、论文撰写等等、等等。另外,MSRA丰富的paper reading和高水平学术报告也极大地拓展了我的学术视野,让我们思考问题的角度更加多元化。感谢导师们,感谢同学们,感谢MSRA,期待在未来充满新冒险的探索之旅继续一起披荆斩棘、迈向世界级研究的新高峰!
正文到此结束
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

