PHP读取doc,docx,xls,pdf,txt内容
我的一个客户有这样的需求:上传文件,可以是doc,docx,xls,pdf,txt格式,现需要用php读取这些文件的内容,然后计算文件里面字数.
1.PHP读取DOC格式的文件
PHP没有自带读取word文件的类,或者是库,这里我们使用 antiword ( http://www.winfield.demon.nl/ )这个包来读取doc文件.
首先介绍一下如何在windows下使用:
1.打开 http://www.winfield.demon.nl/ (antiword下载页面),找到对应的windows版本( http://www.winfield.demon.nl/#Windows ),下载 antiword windows版本 ( antiword-0_37-windows.zip );
2.将下载下来的文件解压到C盘根目录下;
这里还有一点需要注意的: http://www.informatik.uni-frankfurt.de/~markus/antiword/00README.WIN 这个连接里有windows下安装的说明文件.
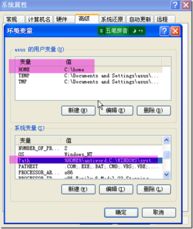
需要设置环境变量,我的电脑(右键)->高级->环境变量->在上面的用户变量里新建一个
变量名:HOME
变量值:c:/home这个目录应该是存在的,如果不存在就在C盘下创建一个home文件夹.
然后在系统变量,修改Path,在Path变量的值最前面加上%HOME%/antiword.
3.开始->运行->CMD 进入到antiword目录;
输入 antiword -h 看看效果.
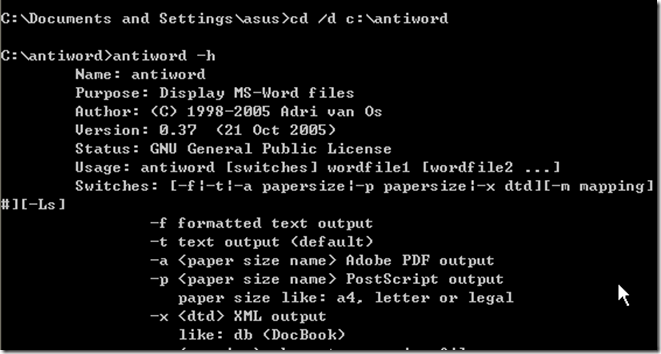
4.然后我们使用antiword –t 命令读取一下doc文件内容;首先复制一个doc文件到c:/antiword目录,然后执行
>antiword –t 文件名.doc
就可以看到屏幕上输出word文件的内容了.
可能你会问了,这和PHP读取word有什么关系呢?呵呵,别急,我们来看看如何在PHP里使用这个命令.
<?php
$file = “D:/xampp/htdocs/word_count/uploads/doc-english.doc”;
$content = shell_exec(“c:/antiword/antiword –f $file”);
?>
这样就把word里面的内容读取content里面了.
至于如何在Linux下读取doc文件内容,就是下载linux版本的压缩包,里面有readme.txt文件,按照那种方式安装就可以了.
$content = shell_exec ( "/usr/local/bin/antiword -f $file" );
2.PHP读取PDF文件内容
php也没有专门用来读取pdf内容的类库.这样我们采用第三方包( xpdf ).还是先做windows下的操作,下载,将其解压到C盘根目录下.
开始->运行->cmd->cd /d c:/xpdf
<?php
$file = “D:/xampp/htdocs/word_count/uploads/pdf-english.pdf”;
$content = shell_exec ( "c://xpdf//pdftotext $file -" );
?>
这样就可以把pdf文件的内容读取到php变量里了.
Linux下的安装方法也很简单这里就不在一一列出
<?php
$content = shell_exec ( "/usr/bin/pdftotext $file -" );
?>
3.PHP读取ZIP文件内容
首先使用PHP zip解压zip文件,然后读取解压包里的文件,如果是word就采用antiword读取,如果是pdf就使用xpdf读取.
<?php
/**
* Read ZIP valid file
*
* @param string $file file path
* @return string total valid content
*/
function ReadZIPFile($file = '') {
$content = "";
$inValidFileName = array ();
$zip = new ZipArchive ( );
if ($zip->open ( $file ) === TR ) {
for($i = 0; $i < $zip->numFiles; $i ++) {
$entry = $zip->getNameIndex ( $i );
if (preg_match ( '#/.(txt)|/.(doc)|/.(docx)|/.(pdf)$#i', $entry )) {
$zip->extractTo ( pathinfo ( $file, PATHINFO_DIRNAME ) . "/" . pathinfo ( $file, PATHINFO_FILENAME ), array (
$entry
) );
$content .= CheckSystemOS ( pathinfo ( $file, PATHINFO_DIRNAME ) . "/" . pathinfo ( $file, PATHINFO_FILENAME ) . "/" . $entry );
} else {
$inValidFileName [$i] = $entry;
}
}
$zip->close ();
rrmdir ( pathinfo ( $file, PATHINFO_DIRNAME ) . "/" . pathinfo ( $file, PATHINFO_FILENAME ) );
/*if (file_exists ( $file )) {
unlink ( $file );
}*/
return $content;
} else {
return "";
}
}
?>
4.PHP读取DOCX文件内容
docx文件其实是由很多XML文件组成,其中内容就存在于word/document.xml里面.
我们找到一个docx文件,使用zip文件打开(或者把docx后缀名改为zip,然后解压)
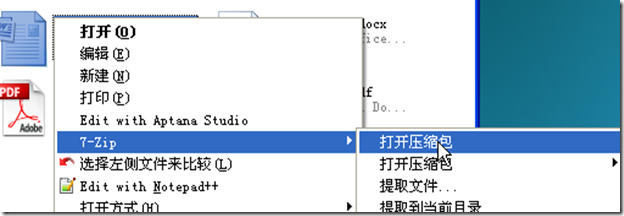
在word目录下有document.xml

docx文件的内容就存在于document.xml里面,我们读取这个文件就可以了.
<?php
/**
* Read Docx File
*
* @param string $file filepath
* @return string file content
*/
function parseWord($file) {
$content = "";
$zip = new ZipArchive ( );
if ($zip->open ( $file ) === tr ) {
for($i = 0; $i < $zip->numFiles; $i ++) {
$entry = $zip->getNameIndex ( $i );
if (pathinfo ( $entry, PATHINFO_BASENAME ) == "document.xml") {
$zip->extractTo ( pathinfo ( $file, PATHINFO_DIRNAME ) . "/" . pathinfo ( $file, PATHINFO_FILENAME ), array (
$entry
) );
$filepath = pathinfo ( $file, PATHINFO_DIRNAME ) . "/" . pathinfo ( $file, PATHINFO_FILENAME ) . "/" . $entry;
$content = strip_tags ( file_get_contents ( $filepath ) );
break;
}
}
$zip->close ();
rrmdir ( pathinfo ( $file, PATHINFO_DIRNAME ) . "/" . pathinfo ( $file, PATHINFO_FILENAME ) );
return $content;
} else {
return "";
}
}
?>
如果想要通过PHP创建docx文件,或者是把docx文件转为xhtml,pdf可以使用phpdocx,( http://www.phpdocx.com/ )

5.PHP读TXT
直接使用PHP file_get_content函数就可以了.
<?php
$file = “D:/xampp/htdocs/word_count/uploads/eng.txt”;
$content = file_get_content($file);
?>
6.PHP读EXCEL
http://phpexcel.codeplex.com/
现在只是读取文件内容了,怎么计算单词的个数呢?
PHP有一个自带的函数,str_word_count,这个函数可以计算出单词的个数,但是如果要计算antiword读取出来的doc文件的单词个数就会很大的误差.
这里我们使用以下这个函数专门用来读取单词个数
<?php
/**
* statistic word count
*
* @param string $content word content of the file
* @return int word count of the content
*/
function StatisticWordsCount($text = '') {
// $text = trim ( preg_replace ( '//d+/', ' ', $text ) ); // remove extra spaces
$text = str_replace ( str_split ( '|' ), '', $text ); // remove these chars (you can specify more)
// $text = str_replace ( str_split ( '-' ), '', $text ); // remove these chars (you can specify more)
$text = trim ( preg_replace ( '//s+/', ' ', $text ) ); // remove extra spaces
$text = preg_replace ( '/-{2,}/', '', $text ); // remove 2 or more dashes in a row
$len = strlen ( $text );
if (0 === $len) {
return 0;
}
$words = 1;
while ( $len -- ) {
if (' ' === $text [$len]) {
++ $words;
}
}
return $words;
}
?>
详细的代码如下:
<?php
/**
* check system operation win or linux
*
* @param string $file contain file path and file name
* @return file content
*/
function CheckSystemOS($file = '') {
$content = "";
// $type = s str ( $file, strrpos ( $file, '.' ) + 1 );
$type = pathinfo ( $file, PATHINFO_EXTENSION );
// global $UNIX_ANTIWORD_PATH, $UNIX_XPDF_PATH;
if (strtoupper ( s str ( PHP_OS, 0, 3 ) ) === 'WIN') { //this is a server using windows
switch (strtolower ( $type )) {
case 'doc' :
$content = shell_exec ( "c://antiword//antiword -f $file" );
break;
case 'docx' :
$content = parseWord ( $file );
break;
case 'pdf' :
$content = shell_exec ( "c://xpdf//pdftotext $file -" );
break;
case 'zip' :
$content = ReadZIPFile ( $file );
break;
case 'txt' :
$content = file_get_contents ( $file );
break;
}
} else { //this is a server not using windows
switch (strtolower ( $type )) {
case 'doc' :
$content = shell_exec ( "/usr/local/bin/antiword -f $file" );
break;
case 'docx' :
$content = parseWord ( $file );
break;
case 'pdf' :
$content = shell_exec ( "/usr/bin/pdftotext $file -" );
break;
case 'zip' :
$content = ReadZIPFile ( $file );
break;
case 'txt' :
$content = file_get_contents ( $file );
break;
}
}
/*if (file_exists ( $file )) {
@unlink ( $file );
}*/
return $content;
}
/**
* statistic word count
*
* @param string $content word content of the file
* @return int word count of the content
*/
function StatisticWordsCount($text = '') {
// $text = trim ( preg_replace ( '//d+/', ' ', $text ) ); // remove extra spaces
$text = str_replace ( str_split ( '|' ), '', $text ); // remove these chars (you can specify more)
// $text = str_replace ( str_split ( '-' ), '', $text ); // remove these chars (you can specify more)
$text = trim ( preg_replace ( '//s+/', ' ', $text ) ); // remove extra spaces
$text = preg_replace ( '/-{2,}/', '', $text ); // remove 2 or more dashes in a row
$len = strlen ( $text );
if (0 === $len) {
return 0;
}
$words = 1;
while ( $len -- ) {
if (' ' === $text [$len]) {
++ $words;
}
}
return $words;
}
/**
* Read Docx File
*
* @param string $file filepath
* @return string file content
*/
function parseWord($file) {
$content = "";
$zip = new ZipArchive ( );
if ($zip->open ( $file ) === tr ) {
for($i = 0; $i < $zip->numFiles; $i ++) {
$entry = $zip->getNameIndex ( $i );
if (pathinfo ( $entry, PATHINFO_BASENAME ) == "document.xml") {
$zip->extractTo ( pathinfo ( $file, PATHINFO_DIRNAME ) . "/" . pathinfo ( $file, PATHINFO_FILENAME ), array (
$entry
) );
$filepath = pathinfo ( $file, PATHINFO_DIRNAME ) . "/" . pathinfo ( $file, PATHINFO_FILENAME ) . "/" . $entry;
$content = strip_tags ( file_get_contents ( $filepath ) );
break;
}
}
$zip->close ();
rrmdir ( pathinfo ( $file, PATHINFO_DIRNAME ) . "/" . pathinfo ( $file, PATHINFO_FILENAME ) );
return $content;
} else {
return "";
}
}
/**
* Read ZIP valid file
*
* @param string $file file path
* @return string total valid content
*/
function ReadZIPFile($file = '') {
$content = "";
$inValidFileName = array ();
$zip = new ZipArchive ( );
if ($zip->open ( $file ) === TR ) {
for($i = 0; $i < $zip->numFiles; $i ++) {
$entry = $zip->getNameIndex ( $i );
if (preg_match ( '#/.(txt)|/.(doc)|/.(docx)|/.(pdf)$#i', $entry )) {
$zip->extractTo ( pathinfo ( $file, PATHINFO_DIRNAME ) . "/" . pathinfo ( $file, PATHINFO_FILENAME ), array (
$entry
) );
$content .= CheckSystemOS ( pathinfo ( $file, PATHINFO_DIRNAME ) . "/" . pathinfo ( $file, PATHINFO_FILENAME ) . "/" . $entry );
} else {
$inValidFileName [$i] = $entry;
}
}
$zip->close ();
rrmdir ( pathinfo ( $file, PATHINFO_DIRNAME ) . "/" . pathinfo ( $file, PATHINFO_FILENAME ) );
/*if (file_exists ( $file )) {
unlink ( $file );
}*/
return $content;
} else {
return "";
}
}
/**
* remove directory
*
* @param string $dir path dir
*/
function rrmdir($dir) {
if (is_dir ( $dir )) {
$objects = scandir ( $dir );
foreach ( $objects as $object ) {
if ($object != "." && $object != "..") {
if (filetype ( $dir . "/" . $object ) == "dir") {
rrmdir ( $dir . "/" . $object );
} else {
unlink ( $dir . "/" . $object );
}
}
}
reset ( $objects );
rmdir ( $dir );
}
}
//调用方法
$file = “D:/xampp/htdocs/word_count/uploads/pdf-german.zip”;
$word_number = StatisticWordsCount ( CheckSystemOS ( $file) );
?>
http://www.it300.com/article-15290.html
正文到此结束
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

