学会用Spark实现朴素贝叶斯算法
编者按:本文作者汪榕曾写过一篇文章:《 以什么姿势进入数据挖掘会少走弯路 》,是对想入行大数据的读者的肺腑之言,其中也表达了作者的一些想法,希望大家不要随便去上没有结合业务的收费培训班课程;而后,他有了结合他本人的工作经验,写一系列帮助大家进行实践学习课程文章的想法,InfoQ也觉得这是件非常有意义的事情,特别是对于大数据行业1-3年工作经验的人士,或者是没有相关工作经验但是想入行大数据行业的人。课程的名称是“数据挖掘与数据产品的那些事”,目的是:1. 引导目标人群正确学习大数据挖掘与数据产品;2. 协助代码能力薄弱的学习者逐渐掌握大数据核心编码技巧;3. 帮助目标人群理解大数据挖掘生态圈的数据流程体系;4. 分享大数据领域实践数据产品与数据挖掘开发案例;5.交流大数据挖掘从业者职业规划和发展方向。这系列文章会在InfoQ上形成一个专栏,本文是专栏的第二篇。
第一部分:回顾以前的一篇文章
简单之极,搭建属于自己的Data Mining环境(Spark版本) 很多朋友也亲自动手搭建了一遍,当然也遇到不少困难,我都基本一对一给予了回复,具体可以查看原文。
下面的实践也主要是基于上述部署的环境来进行开发。
第二部分:初步学习Spark与数据挖掘相关的核心知识点
对于这部分的介绍,不扩展到Spark框架深处,仅仅介绍与大数据挖掘相关的一些核心知识,主要分了以下几个点:
初步了解spark
- 适用性强:它是一种灵活的框架,可同时进行批处理、 流式计算、 交互式计算。
- 支持语言:目前spark只支持四种语言,分别为java、python、r和scala。但是个人推荐尽量使用原生态语言scala。毕竟数据分析圈和做数据科学研究的人群蛮多,为了吸引更多人使用spark,所以兼容了常用的R和python。
与MapReduce的差异性
- 高效性:主要体现在这四个方面,提供Cache机制减少数据读取的IO消耗、DAG引擎减少中间结果到磁盘的开销、使用多线程池模型来减少task启动开销、减少不必要的Sort排序和磁盘IO操作。
- 代码简洁:解决同一个场景模型,代码总量能够减少2~5倍。从以前使用MapReduce来写模型转换成spark,这点我是切身体会。
理解spark离不开读懂RDD
- spark2.0虽然已经发测试版本和稳定版本,但是迁移有一定成本和风险,目前很多公司还处于观望阶段。
- RDD(Resilient Distributed Datasets), 又称弹性分布式数据集。
- 它是分布在集群中的只读对象集合(由多个Partition构成)。
- 它可以存储在磁盘或内存中(多种存储级别),也可以从这些渠道来创建。
- spark运行模式都是通过并行“转换” 操作构造RDD来实现转换和启动。同时RDD失效后会自动重构。
从这几个方面理解RDD的操作
- Transformation ,可通过程序集合、Hadoop数据集、已有的RDD,三种方式创造新的RDD。这些操作都属于Transformation(map, filter, groupBy, reduceBy等)。
- Action ,通过RDD计算得到一个或者一组值。这些操作都属于Action(count, reduce, saveAsTextFile等)。
- 惰性执行 :Transformation只会记录RDD转化关系,并不会触发计算。Action是触发程序执行(分布式) 的算子。
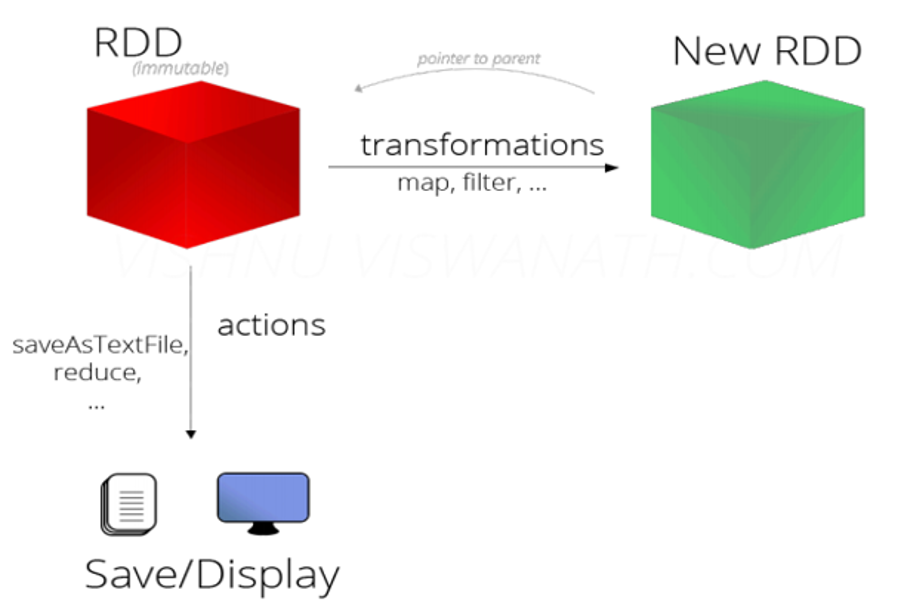
一张图概括RDD
知晓Spark On Yarn的运作模式
除了本地模式的spark程序测试,大部分工作都是基于Yarn去提交spark任务去执行。因此对于提交执行一个spark程序,主要有以下流程的运作模式。(提交任务:bin/spark-submit --master yarn-cluster --class …)

一张图知晓运作模式
懂得spark本地模式和yarn模式的提交方式(不讨论Standalone独立模式)
如果说上述的概念、执行流程和运作方式目的在于给做大数据挖掘的朋友一个印象,让大家不至于盲目、错误的使用spark,从而导致线上操作掉坑。那最后的本地模式测试和集群任务提交是必须要掌握的知识点。
- 本地模式(local):单机运行,将Spark应用以多线程方式直接运行在本地,通常只用于测试。我一般都会在windows环境下做充足的测试,无误以后才会打包提交到集群去执行。慎重!
- YARN/mesos模式:运行在资源管理系统上,对于Yarn存在两种细的模式,yarn-client和yarn-cluster,它们是有区别的。
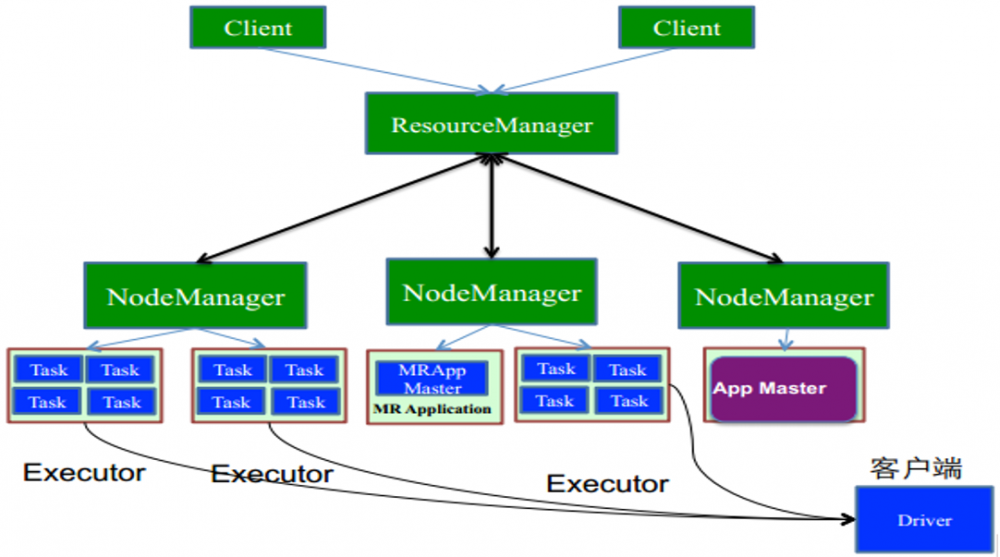
一张图知晓yarn-client模式
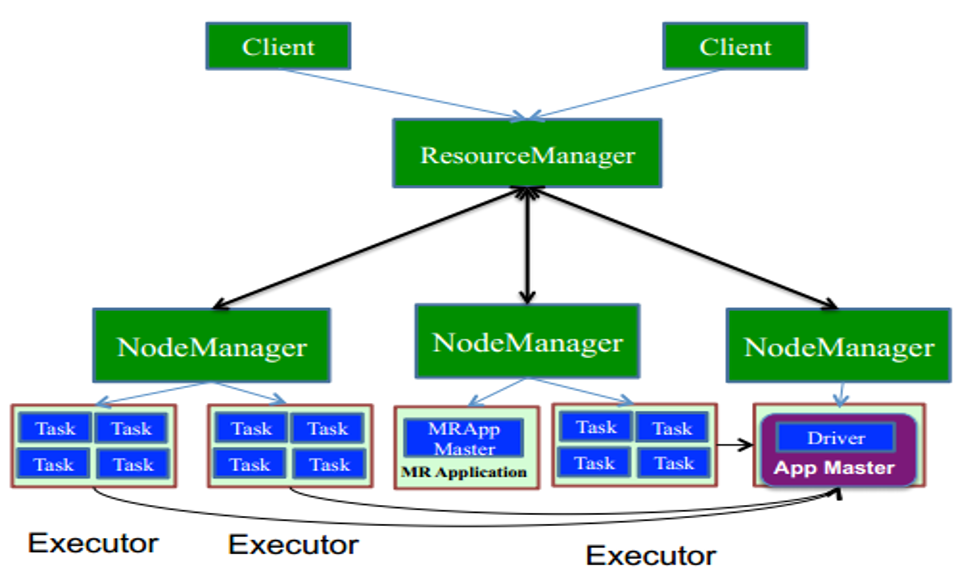
一张图知晓yarn-cluster模式
为了安全起见,如果模型结果文件最终都是存于HDFS上的话,都支持使用yarn-cluster模式,即使某一个节点出问题,不影响整个任务的提交和执行。
总结:很多做大数据挖掘的朋友,代码能力和大数据生态圈的技术会是一个软弱,其实这点是很不好的,关键时候容易吃大亏。而我上面所提的,都是围绕着写好一个场景模型,从code实现到上线发布都需要留心的知识点。多一份了解,少一分无知。况且一天谈什么算法模型,落地都成困难,更别提上线以后对模型的参数修改和特征筛选。
第三部分:创作第一个数据挖掘算法(朴素贝叶斯)
看过以前文章的小伙伴都应该知道,在业务层面上,使用场景最多的模型大体归纳为以下四类:
- 分类模型,去解决有监督性样本学习的分类场景。
- 聚类模型,去自主判别用户群体之间的相似度。
- 综合得分模型,去结合特征向量和权重大小计算出评估值。
- 预测响应模型,去以历为鉴,预测未来。
所以我这里首先以一个简单的分类算法来引导大家去code出算法背后的计算逻辑,让大家知晓这样一个流程。
朴素贝叶斯的实现流程
- 理解先验概率和后验概率的区别?
a. 先验概率 :是指根据以往经验和分析得到的概率。简单来说,就是经验之谈,打趣来说——不听老人言,吃亏在眼前。
b. 后验概率 :是指通过调查或其它方式获取新的附加信息,去修正发生的概率。也就是参考的信息量更多、更全。
- 它们之间的转换,推导出贝叶斯公式
条件概率:
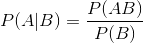
注:公式中P(AB)为事件AB的联合概率,P(A|B)为条件概率,表示在B条件下A的概率,P(B)为事件B的概率。
推导过程:
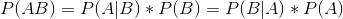
将P(AB)带入表达式
贝叶斯公式:
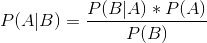
简单来说,后验概率 = ( 先验概率 * 似然度)/标准化常量。
扩展:
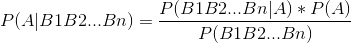
三、如何去理解朴素二字?
朴素贝叶斯基于一个简单的假定:给定特征向量之间相互条件独立。
朴素体现:
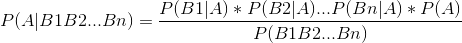
考虑到P(B1B2...Bn)对于所有类别都是一样的。而对于朴素贝叶斯的分类场景并需要准确得到某种类别的可能性,更多重点在于比较分类结果偏向那种类别的可能性更大。因此从简化度上,还可以对上述表达式进行优化。
简化公式:
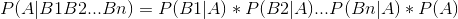
这也是朴素贝叶斯得以推广使用一个原因,一方面降低了计算的复杂度,一方面却没有很大程度上影响分类的准确率。
但客观来说,朴素的假设也是这个算法存在缺陷的一个方面,有利有弊。
四、如何动手实现朴素贝叶斯算法
这里面有很多细节,但是为了迎合文章的主题,不考虑业务,只考虑实现。我们假设已经存在了下面几个东西:
- 场景就假设为做性别二分类。
- 假设所有特征向量都考虑完毕,主要有F1、F2、F3和F4四个特征影响判断用户性别。
- 假设已经拥有训练样本,大约10000个,男性和女性样本各占50%。
- 假设不考虑交叉验证,不考虑模型准确率,只为了实现分类模型。
- 这里优先使用80%作为训练样本,20%作为测试样本。
- 这里不考虑特征的离散化处理
有了上面的前提,接下来的工作就简单多了,大体分为两步,处理训练样本集和计算测试样本数据结果。
第零步:样本数据格式
#ID F1 F2 F3 F4 CF 1 1 0 5 1 男 2 0 1 4 0 女 3 1 1 3 1 男
第一步:处理训练样本集
代码逻辑
def NBmodelformat(rdd:RDD[String],path:String)={
//定义接口:输入为读取训练样本的RDD,训练样本处理后的输出路径
val allCompute = rdd.map(_.split("/u0009")).map(record =>
//SEPARATOR0定义为分隔符,这里为"/u0009"
{
var str = ""
val lengthParm = record.length
for(i <- 1 until lengthParm) {
if(i<lengthParm-1){
//SEPARATOR2定义为分隔符,这里为"_"
val standKey = "CF"+i+"_"+record(i)+"_"+record(lengthParm-1)
//对特征与类别的关联值进行计数
str=str.concat(standKey).concat("/u0009")
}else{
//对分类(男/女)进行计数
val standKey = "CA"+"_"+record(lengthParm-1)
str=str.concat(standKey).concat("/u0009")
}
}
//对样本总数进行计数
str.concat("SUM").trim()
}
).flatMap(_.split("/u0009")).map((_,1)).reduceByKey(_+_)
//本地输出一个文件,保存到本地目录
allCompute.repartition(1).saveAsTextFile(path)
}
最终得到训练样本结果如下所示:
[lepingwanger@hadoopslave1 model1]$ cat cidmap20161121 |more -3 (CF1_1_男,1212)(CF1_0_女,205)(CF2_0_男,427)
第二步:朴素贝叶斯计算逻辑
模型demo
def NBmodels(line:String,cidMap:Map[String,Int]):String={
val record = line.split("/u0009")
val manNum = cidMap.get("CA_男").getOrElse(0).toDouble
val womanNum = cidMap.get("CA_女").getOrElse(0).toDouble
val sum = cidMap.get("SUM").getOrElse(0).toDouble
//计算先验概率,这里采取了拉普拉斯平滑处理,解决冷启动问题
val manRate = (manNum+1)/(sum+2)
val womanRate = (womanNum+1)/(sum+2)
var manProbability = 1.0
var womanProbability = 1.0
for(i <- 1 until record.length){
//组合key键
val womanKey = "CF"+i+"_"+record(i)+"_"+"女"
val manKey = "CF"+i+"_"+record(i)+"_"+"男"
val catWoman = "CA"+"_"+"女"
val catMan = "CA"+"_"+"男"
//确定特征向量空间的种类,解决冷启动问题
val num = 3
//获取训练模型得到的结果值
val womanValue = (cidMap.get(womanKey).getOrElse(0)+1)/(cidMap.get(catWoman).getOrElse(0)+num)
val manValue = (cidMap.get(manKey).getOrElse(0)+1)/(cidMap.get(catMan).getOrElse(0)+num)
manProbability*=manValue
womanProbability*=womanValue
}
val woman=womanProbability*womanRate
val man=manProbability*manRate
if(woman>man) "女" else "男"
}
第三步:用测试数据集得到分类结果
驱动模块
def main(args:Array[String]):Unit={
val SAMPLEDATA = "file:///E...本地目录1"
val SAMPLEMODEL = "file:///E...本地目录2"
val INPUTDATA = "file:///E...本地目录3"
val RESULTPATH = "file:///E...本地目录4"
val sc = new SparkContext("local","TestNBModel")
//删除目录文件
DealWays(sc,SAMPLEMODEL)
//读取训练数据SAMPLEDATA,featureNum为特征向量个数
//首先过滤长度不标准的行
val NaiveBayesData = sc.textFile(SAMPLEDATA, 1).map(_.trim).filter(line =>Filter(line,6))
//调用上一步模型
NBmodelformat(NaiveBayesData,SAMPLEDATA)
//读取测试模型结果,转换为Map数据结构
val cidMap = deal(sc,SAMPLEMODEL)
DealWays(sc,RESULTPATH)
sc.textFile(INPUTDATA).map(_.trim).filter(line =>Filter(line,7))
.map(NBmodels(_,cidMap)).saveAsTextFile(RESULTPATH)
sc.stop()
}
总结:上面主要介绍了三个步骤去编写一个简单的朴素贝叶斯算法demo,还有一些值得优化的点,写法也比较偏命令式编程(告诉计算机你想要做什么事?)。但是目的在于给一些童鞋一个印象,理解上也方便些,清楚如何去落地一个简单的算法,这很重要。
后续系列文章主要有这几个方面:
- 实现一些常用的算法模型,一切洞察背后的来龙去脉。
- 结合线上业务场景模型,介绍实际的大数据挖掘流程。
- 介绍大数据挖掘与数据产品的融合对接。
作者介绍
汪榕,3年场景建模经验,曾累计获得8次数学建模一等奖,包括全国大学生国家一等奖,在国内期刊发表过相关学术研究。两年电商数据挖掘实践,负责开发精准营销产品中的用户标签体系。发表过数据挖掘相关的多篇文章。目前在互联网金融行业从事数据挖掘工作,参与开发反欺诈实时监控系统。
感谢杜小芳对本文的审校。
给InfoQ中文站投稿或者参与内容翻译工作,请邮件至editors@cn.infoq.com。也欢迎大家通过新浪微博(@InfoQ,@丁晓昀),微信(微信号: InfoQChina )关注我们。
正文到此结束
- 本文标签: 管理 希望 总结 学生 python map 业务层 ebay 测试 src cat 线程池 大数据 MQ 开发 删除 安全 Action 空间 id 翻译 dist 产品 1212 数据 IO 参数 windows http apr 数据科学 代码 Slave1 java client 互联网 文章 UI cache value IBM ask HDFS scala 多线程 Master 目录 微博 线程 数据挖掘 金融 ORM key Hadoop 推广 集群 营销
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

