我如何用深度学习改造母亲的助听器?
雷锋网按:目前的人造听力系统存在一个关键问题:无法过滤背景噪音。尽管用户对倾听的需求十分强烈,然而硬件只是单纯地将声音放大——自然也包括噪音。英国认知科学家Colin Cherry于1953年首次将这一问题称为"cocktail party problem"(鸡尾酒会难题)。
作者 DeLiang Wang 是一名俄亥俄州立大学的教授,他主要关注计算机科学及工程领域,此外,他也在学校的认知及大脑科学研究中心工作。本文是他基于自己亲人的切身体会,利用深度学习改造助听器的自述,雷锋网编译,未经许可不得转载。

我上大学的时候,母亲的听力逐渐下降。不过一直以来,我很愿意回家将我所学的东西与她分享,她也很乐意倾听。但渐渐地我发现,如果多个人同时说话,那么母亲很难分清到底是哪个人在和她讲话。尽管她使用了助听器,但对她来说区分这些声音仍旧很难。在我们家庭聚餐的时候,我母亲不希望我们同时和他说话,希望每次只有一个人和她说话。
我母亲的痛苦遭遇反应了目前助听设备面临的一个主要问题,即助听器滤音效果不好。尽管信号处理专家、人工智能专家、听力专家已经努力了几十年,但现在的人造听力系统仍不能很好滤掉背景噪音。
据估计,六十年后将会有约25%的人需要佩戴助听设备,如果这些设备去除杂音的效果不好,那么我们可以想象这样一个场景:
当一个人和佩戴助听设备的人谈话时,此时一辆汽车呼啸而过,但这些助听设备只是简单的将杂音与话音放大,却无法很好去除汽车杂音,此时对于用户的听力将会造成多么大的伤害,他们将听不清对方的讲话。
是时候该解决这个问题了,我在俄亥俄州立大学的实验室目前尝试使用深度学习模型实现杂音与声音分离,此外我们还尝试了多种用于去除杂音的数字滤波器。
我们相信基于深度学习模型的听力修复可以使听力受损人的听力理解能力达到甚至超过正常人。实际上,我们的早期模型效果一直在提升。由原来听清 10% 提高到 90%。在现实生活中,即使人们没有听清一句话中的每一词,他们也可以理解这句话的意思。所以这实际上已经意味着,人们已经从“一句都听不懂”变成了“能听懂一句话”的状态。
对于有听觉问题的人,没有好的助听设备,人的听力只会越来越糟。世界卫生组织估计约 15%(776百万人)患有听觉问题,随着老年人口的增多,这一数字将会逐渐变大,并且高级听力设备的潜在市场不仅局限于听觉受损用户。开发商可以将这一技术用于智能手机,以提升智能手机的通话质量。一些人的工作环境背景噪音复杂,这个设备可以解决这问题。处于战争环境中的士兵也可以佩戴这个设备使得他们之间的通话更加顺畅。
语音清洗与过滤
助听设备的市场广阔,据印度MarketsandMarkets研究发现,目前助听行业规模大约为60亿美金,市场规模在2020年以前预计以每年6%的速度递增。为了满足新用户需求,我们需要解决‘鸡尾酒会难题’,那么如何解决呢?深度学习给我们提供了一个很好的解决思路。
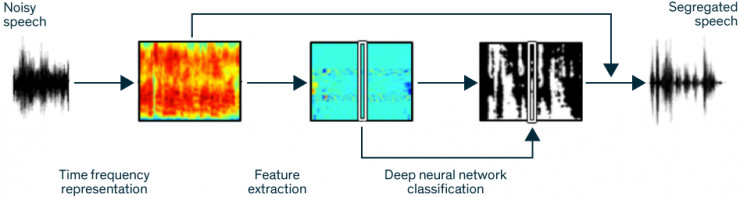
-
语音清洗流程如下:
-
信号转换:机器学习程序首先将语音信号转换为时域信号。
-
特征表示:在时域范围内用85个特征表示语音信号,
-
语音分类:将这些用特征表示的语音信号传入深度学习模型中,找出语音信号与杂音 信号,
-
杂音过滤:使用滤波器去除杂音信号,保留语音信号。
数十年来,电子与计算机专家尝试从信号处理的角度实现语音与杂音的分离,但均以失败告终。目前最有效的方法就是语音活动检测器,用于识别不同人之间的说话。在这种方法下,系统检测出不同的语音信号,然后滤去这些声音信号,留下理想的、无杂音信号。 不幸的是,这种方法效果很不好,它通常会滤去很多语音或只滤去少量杂音。即便经过了几十年的发展,这项技术的实际效果仍然不太理想。
我觉得我们得使用新的方法解决这个问题,我们首先研究了 Albert Bregman( McGill University)的关于人类听力系统的理论,他认为人类的听觉系统将不同的声音分成不同的声音流,一个声音流对应一个音源,每一个声音流据有不同的音高、音量、方向。
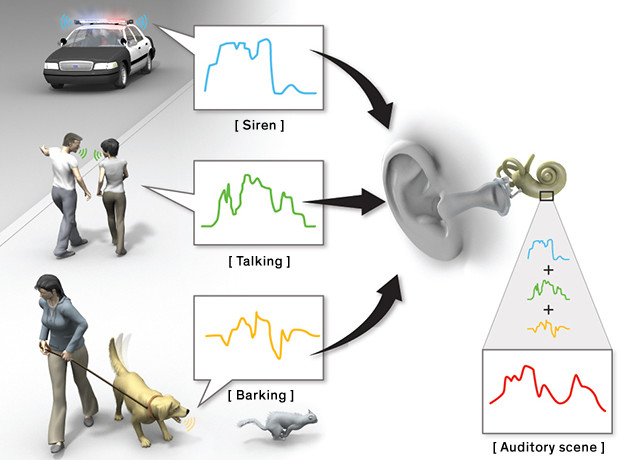
上图展示了声音场景是如何形成的
总之,许多音流(像曲棍球比赛中朋友们的呐喊)组成 Bregman 所谓的听觉场景。如果不同音波的音频一样,那么音量最大那个将会盖过其它声音,这一现象被称作听觉掩蔽效应。例如,下雨的的时候没人会听到钟表的滴答声。这原理也用在了MP3的文件中,它通过压缩被掩蔽的声音,使得文件大小变为了原来的十分之一,文件虽然缩小了,但用户却没有任何感觉。
回顾了Bregman的工作,我们设想我们是否可以构建一个滤波器,在特定时刻对于特定音频,这个滤波器可以找到主声波。听觉感知专家Psychoacousticians将人类的听觉频率(20Hz到20000Hz)分成24份,那么问题就变成了我们需要一个滤波器,在某一时刻这个滤波器可以告诉我们是否存在一个包含比其它语音或杂音都大的声音,然后江这个大的声音进行分离出来。
我的实验室在2001年就开始了这项工作,并给音流打标签,以表明他们的主音流是语音流还是杂音流。有了这些标记数据,然后我们基于机器学习的方法,训练一个能区分主音流是声音还是杂音的分类器,这些特征包括音量、音调等。
原始过滤器是一个二元过滤器,用于对特定时刻特定频率的声音进行标识,这个过滤器在时域范围对声音信号进行0、1标识,如果主音为声音,标1;主音为杂音,标0。最后生成一个主音为声音与主音为杂音的样本集合,滤波器除去标识为0的声音,保留标识为1的声音。为了保证句子能够被理解,必须保证标识为1的语音占有一定的比例。
2006年,在美国空军实验室我们对声音滤波器进行测试,与此同时,另外一家机构也队我们的产品进行独立的第三方评估,在这些试验中,我们的产品性能优异。不仅有助于提高听觉受损者的听力水平,还有助于提高正常人的听力水平。
我们创造了一款在实验室中表现优良的听力设备,在设计过程中,我们训练的时候是将语音信号与杂音信号分开的。测试的时候将这两者混合在一起,然后测试。由于这些信息均为为标记信息,所以过滤器知道什么情况下语音信号要大于杂音信号,所以我们称之为理想滤波器。但实际情况是滤波器应该能靠自己进行判断,而不是靠我们提前告诉它。
不过,理想滤波器确实能提高听觉受损者与正常者的听力理解水平。这表明我们可以将分类方法用于区分语音与噪音。分类方法实际上是一种机器学习的方法,通过训练、反馈、惩罚等一些列类似于人的学习过程,来实现对声音信号的正确分类。
在接下来的几年中,我们实验室开始尝试使用分类方法来模仿我们滤波器,同时,我们基于机器学习设计新的分类器,提高自动语音识别的质量。后来一组来自University of Texas的研究人员使用一种不同的方法首次实现语音可懂性的实质意义上的进步,这种方法仅使用了单声道特征。
但是对于助听设备来说,这些分类方法的效果与精度还不够,这些方法还不能处理现实世界中复杂环境下的声音信息。因此,我们需要更好的方法。
如何进一步改善系统?
我们决定进一步改善系统效果,使我们的系统可以应用在现实环境中且不需训练。为了解决这个问题,我们构建了一个以前从未构建过的机器学习系统,经过复杂的训练,这个神经网络系统,可以用于声音与杂音的分离。在24个测试样本中,这套系统提高听力受损人员的听力理解力约50%。效果良好。
神经网络是由一些简单的神经元组成,这些简单那神经元组合在一起就可以处理复杂的问题。当一个新的神经网络模型构建好以后,这个模型需要利用数据不断的调整神经元与神经元之间的权重(类似于人脑学习),以达到实现语音信号分类的目的。
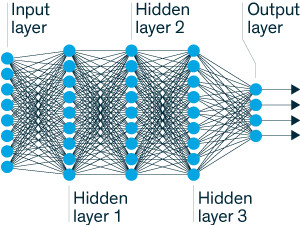
如上图所示:左侧为为输入层,右侧为输出层,通过调节层与层之间的神经元之间的链接权重提高系统性能。
神经网络有不同的形状、大小、深度。隐层多余两层的就可以称为深度神经网络,上一层的输出是下一层的输入,就好比给下一个隐层增加一些先验知识。
例如,我们通过数据训练一个签名识别网络,如果此时有一个新的签名,这个签名与数据集中的签名是一个人写的,却与数据集中的签名不完全一样,但我们的网络仍可以识别出来,因为我们的网络层是可以识别出同一人签名的不同特征的,只要特征相同,就可以认为是同一个人写的,这些特征包括文字的倾斜角度,字母i的点是否点上等。
为了构建我们自己的深度学习网络,我们开始编写基于音频、振幅的特征抽取器,我们定义了数十个特征用以区别声音与杂音。最终我们确定了85个特征。 其中最重要的特征是音频与音强。 抽完特征以后,我们用这85个特征对神经网络进行训练。我们的训练包含两个阶段:
-
一、通过无监督方法训练系统参数。
-
二、用杂音数据对模型进行训练,这一步是有监督训练。我们用标记好的正例与负例对我们的系统进行测试与改善。
具体流程如下:输入一个新数据,系统首先对数据进行特征提取,特征表示,对数据进行分类(是声音还是杂音),与正确结果进行比较。如果结果有误,对神经网络进行调参,使得我们的输出在下一次的训练中尽可能与正确结果相接近。
为了实现神经元与神经元之间的权重调整(调参),我们首先计算神经网络的输出误差,我们有一个误差函数,这个函数用来计算神经网络的输出结果误差。根据这个结果误差,我们对神经元之间的连接权重进行调整,以降低误差,这个训练过程需要重复上千次。最终实现一个较好的训练模型。
为了使得结果更好,我们在前面深度学习的基础上在构建一个深度学习模型,将第一个的输出做为第二模型的输入,对结果进行细粒度的调优,第一层的关注的是声音单元本身的特征,第二层检验的是声音单元‘邻居’的特征。那么为什么对周围声音进行检测也有用呢?道理很简单,第一层好比是一个正在销售的房屋,我们对它的各个房间进行查看,第二层就好比这个屋子的‘邻居’,我们对它的‘邻居’进行检验。换句话说,第二层为第一层提供了声音信号的上下文信息,有助于提高分类的准确率。例如,一个音节可能包含几个时域,背景噪音可能只在突然出现音节的起始阶段,后面就没有了。在这个例子中,上下文信息就可以使我们更好的从杂音中提取出声音。
在完成训练后,我们的深度学习分类器要比我们原先的分类器好很多,事实上,这是我们首次在算法上取得突破,使得我们的助听设备可以提高听觉受损人员的听力水平。为了测试我们的设备性能,我们对12名听障人员、12名听力正常人员进行测试,测试用例是成对出现的,第一次声音与杂音混在一起,第二次是经过我们神经网络处理过的声音。例如包含“It’s getting cold in here”和“They ate the lemon pie,”的句子有两种杂音,一种是嗡嗡声,另一种背景杂音是很多人在一起说话。这个嗡嗡声很像冰箱压缩机工作的声音,而另一种杂音是是我们生成的,是四男四女的说话声,以此来模仿鸡尾酒会的这一类背景噪音。
在对背景噪音进行处理后,无论是听觉受损人员还是听觉正常人员其听力理解能力均有大幅提升,在未经处理的声音中,听觉受损人员只可以听清29%的单词,但在处理过的声音中,他们可以理解84%的内容。在一些例子中,一开始只能听清10%,经 过处理后就 可以理解90%的内容了。在有嗡嗡杂音环境下,听觉受损人员的理解力从未经处理时的36%提升到82%。
对于听力正常的人,我们的系统同样有效,它可以使正常人在有杂音的环境下听到的更多,这就意味着将来的某一天,我们的系统可以帮助更多的人。在嗡嗡杂音下,未经处理,正常人只能听懂37%,处理后可以听懂80%,在鸡尾酒会的这一类背景噪音下,其听力理解力由42%提升到78%。
我们 实验中最有意思的结果是,如果一个听力受损的人使用我们的助听设备,那么他的听力能否超过正常人?答案是肯定的。在嗡嗡环境下,听力受损的人(使用我们的助听设备)可以比正常人多听懂15%内容,在聚会噪音背景下可以多听懂20%。以这个结果来看,可以说我们的系统是最接近解决‘鸡尾酒会问题’的系统。
局限自然有,展望依然在
尽管如此,我们的算法仍有局限,在测试样例中,我们的背景噪声与我们训练用的背景噪声很相似。但实际情况却不是这样的,所以在实际应用中,系统需要快速学习周围环境中的各种背景噪声,并将其滤掉。例如通风系统的声音、房间内回音等。
我们购买了一个包含10000种杂音的数据集(这个数据集起初是为电影制造商准备的),用其来训练我们模型。今年,我们发现经过训练的程序可以处理以前从未遇到过的杂音了,并且去杂音效果得到了及具现实意义的提高(无论对听觉受损者还是听觉正常者),现在,由于得到了全国失聪及其他沟通障碍研究所( National Institute on Deafness and Other Communication Disorders )的支持,我们决定在更多环境下,使用更多的听障人员来测试我们的系统。
最后,我相信我们系统可以在性能更加强大的计算机上进行训练,并且移植到人听障人士身上,或者与智能手机进行配对使用。商家会周期性的对新数据进行训练,并发布新的版本以便让用户升级他们的助听设备,从而使其能够滤去新的杂音。我们已经申请了数个专利并且与多个合作伙伴进行了商业化应用。
使用这个方法,鸡尾酒会难题看起来不在是那么难以解决。我们坚信,只要有更多杂音数据、更加广泛的训练,我们终究可以解决这个难题。事实上,我认为我们现在处理声音的流程与小孩早期区分杂音与声音的过成是很类似的。都是在不断的重复中提升性能的。总之,经验越多,方法就变得越好。
雷锋网小编也设想到,如果一个有着听力障碍的热心读者参加了明年雷锋网 (公众号:雷锋网) 举办的GAIR大会,在人头攒动的会场,他可能一直会被会展播放的背景音乐所打扰,无法专心与新结识的大牛们聊天。如果有了硬件相关的技术提升,那么想必会让活动的效果更好,而这也是科技尤其是人工智能所带给我们的福祉:让智能与未来伴随我们的生活,并使之变得更加美好。
via Deep Learning Reinvents the Hearing Aid
【招聘】雷锋网坚持在人工智能、无人驾驶、VR/AR、Fintech、未来医疗等领域第一时间提供海外科技动态与资讯。我们需要若干关注国际新闻、具有一定的科技新闻选题能力,翻译及写作能力优良的外翻编辑加入。
简历投递至 guoyixin@leiphone.com,工作地 深圳;
或投递至 wudexin@leiphone.com,工作地 北京。
雷锋网原创文章,未经授权禁止转载。详情见 转载须知 。

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

