Flink运行时之统一的数据交换对象
统一的数据交换对象
在Flink的执行引擎中,流动的元素主要有两种:缓冲(Buffer)和事件(Event)。Buffer主要针对用户数据交换,而Event则用于一些特殊的控制标识。但在实现时,为了在通信层统一数据交换,Flink提供了数据交换对象——BufferOrEvent。它是一个既可以表示Buffer又可以表示Event的类。上层使用者只需调用isBuffer和isEvent方法即可判断当前收到的这条数据是Buffer还是Event。
缓冲
缓冲(Buffer)是数据交换的载体,几乎所有的数据(当然事件是特殊的)交换都需要经过Buffer。Buffer底层依赖于Flink自管理内存的内存段(MemorySegment)作为数据的容器。Buffer在内存段上做了一层封装,这一层封装是为了对基于引用计数的Buffer回收机制提供支持。
引用计数是计算机编程语言中的一种内存管理技术,是指将资源(可以是对象、内存或磁盘)的被引用次数保存起来,当被引用次数变为零时就将其释放的过程。使用引用计数技术可以实现自动资源管理的目的。具体做法可简述为:当创建一个对象的实例并在堆上申请内存时,对象的引用计数就为1,在其他对象中需要持有这个对象时,就需要把该对象的引用计数加1,需要释放一个对象时,就将该对象的引用计数减1,直至对象的引用计数为0,对象的内存会被释放。
引用计数还可以指使用引用计数技术回收未使用资源的垃圾回收算法,Objective-C就是使用这种方式进行内存管理的典型语言之一。
它在内部维护着一个计数器referenceCount,初始值为1。内存回收由缓冲回收器(BufferRecycler)来完成,回收的对象就是内存段(MemorySegment)。
实现引用计数的方法有两个。第一个为retain,用于将引用计数加一:
public Buffer retain() {
synchronized (recycleLock) {
//预防性检测,先确认内存段是否已被回收
ensureNotRecycled();
referenceCount++;
return this;
}
}
第二个为回收(或将引用计数减一)的方法recycle,当引用计数减为0时,BufferRecycler会对内存段进行回收:
public void recycle() {
synchronized (recycleLock) {
if (--referenceCount == 0) {
recycler.recycle(memorySegment);
}
}
}
BufferRecycler接口有一个名为FreeingBufferRecycler的简单实现者,它的做法是直接释放内存段。当然通常为了分配和回收的效率,会对Buffer进行预先分配然后加入到Buffer池中。所以,BufferRecycler的常规实现是基于缓冲池的。除此之外,还有另一个接口BufferProvider(它约定了Buffer提供者如何以同步和异步的模式提供Buffer)共同作为缓冲池(BufferPool)的基接口。
整个的Buffer簇的类图如下:
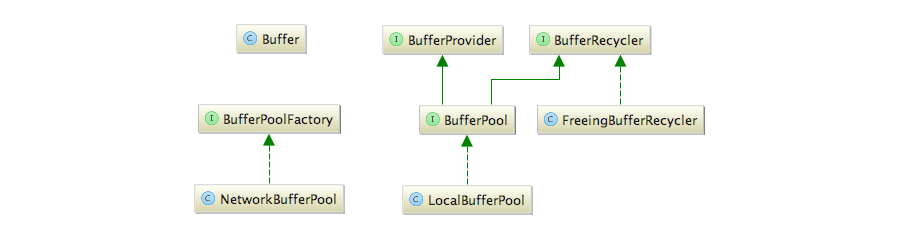
缓冲池工厂(BufferPoolFactory)用于创建和销毁缓冲池,网络缓冲池(NetworkBufferPool)是其唯一的实现者。NetworkBufferPool缓存了固定数目的内存段,主要用于网络栈通信。
NetworkBufferPool在构造器的参数中要求指定其缓存的内存段数目,然后它会初始化固定大小的一个队列作为内存段池。与此同时,构造器参数还允许指定内存段大小以及Flink自主管理的内存类型。并根据这些参数初始化队列中的内存段:
if (memoryType == MemoryType.HEAP) {
for (int i = 0; i < numberOfSegmentsToAllocate; i++) {
byte[] memory = new byte[segmentSize];
availableMemorySegments.add(MemorySegmentFactory.wrapPooledHeapMemory(memory, null));
}
} else if (memoryType == MemoryType.OFF_HEAP) {
for (int i = 0; i < numberOfSegmentsToAllocate; i++) {
ByteBuffer memory = ByteBuffer.allocateDirect(segmentSize);
availableMemorySegments.add(MemorySegmentFactory.wrapPooledOffHeapMemory(memory, null));
}
}
上面的代码段中调用了我们在分析内存管理时分析的内存段工厂(MemorySegmentFactory),注意这里wrapPooledXXX方法其实没什么特殊的,只是新建了相关的内存段实例。不要被其方法名迷惑,所谓的池化的机制都是要在外部维护,比如这里的NetworkBufferPool定义了维护内存段池(也即availableMemorySegments)的一系列方法,比如requestMemorySegment、recycle、destroy等。
因为BufferPool当前只有LocalBufferPool这一个实现,所以NetworkBufferPool在实现BufferPoolFactory的createBufferPool方法时会直接实例化LocalBufferPool。NetworkBufferPool用一个Set维护了其所创建的所有LocalBufferPool的引用。createBufferPool方法要求在创建时指定需要创建的是固定大小的BufferPool还是非固定大小的BufferPool。如果是非固定大小的,NetworkBufferPool也专门提供了一个Set来维护它们,这主要是为了在创建或销毁BufferPool时对这些非固定大小的BufferPool里的Buffer进行“重分布”。
这里对非固定大小的BufferPool里的内存段进行重分布值得我们重点关注一下。其实,所有BufferPool所申请的内存段都归属于NetworkBufferPool所维护的内存段池。只有NetworkBufferPool了解内存段池的所有信息,包括剩余可用的内存段数目。当createBufferPool方法或者destroyBufferPool方法被调用时,对应的可用的内存段数目也会相应得产生变化。这时,为了让内存段被合理地分配并加以利用,所有非固定大小的BufferPool都需要根据最新的可用内存段数来重分布其所包含的内存段数目。具体的重分布的实现如下:
private void redistributeBuffers() throws IOException {
//获得非固定大小的BufferPool个数
int numManagedBufferPools = managedBufferPools.size();
//如果没有,则直接返回,避免除零错误
if (numManagedBufferPools == 0) {
return;
}
//当前总共可用的内存段数目(未实际分配)
int numAvailableMemorySegment = totalNumberOfMemorySegments - numTotalRequiredBuffers;
//每个BufferPool可额外附“赠”的内存段数目
int numExcessBuffersPerPool = numAvailableMemorySegment / numManagedBufferPools;
//当然可用的内存段不一定正好能完全分摊给所有的非固定大小的BufferPool,所以剩下的余量以轮转的方式分摊
int numLeftoverBuffers = numAvailableMemorySegment % numManagedBufferPools;
int bufferPoolIndex = 0;
//遍历BufferPool挨个扩充
for (LocalBufferPool bufferPool : managedBufferPools) {
int leftoverBuffers = bufferPoolIndex++ < numLeftoverBuffers ? 1 : 0;
bufferPool.setNumBuffers(
bufferPool.getNumberOfRequiredMemorySegments() + numExcessBuffersPerPool + leftoverBuffers
);
}
}
该方法的调用环境必须处于同步块中。
LocalBufferPool的setNumBuffers方法并不只是设置一下数目这么简单,具体的逻辑我们暂且按下不表。我们先来看一下LocalBufferPool的实现,它用于管理从NetworkBufferPool申请到的一组Buffer实例。LocalBufferPool中维护着的一些信息:
//当前缓冲区池最少需要的内存段的数目 private final int numberOfRequiredMemorySegments; //当前可用的内存段,这些内存段已从网络缓冲池中请求到本地,但当前没有被当做缓冲区用于数据传输 private final Queue<MemorySegment> availableMemorySegments = new ArrayDeque<MemorySegment>(); //注册过的获取Buffer可用性的侦听器,当无Buffer可用时,才可注册侦听器 private final Queue<EventListener<Buffer>> registeredListeners = new ArrayDeque<EventListener<Buffer>>(); //缓冲池的当前大小 private int currentPoolSize; //从网络缓冲池请求的以及以某种形式关联着的所有的内存段数目 private int numberOfRequestedMemorySegments;
LocalBufferPool被实例化时,虽然指定了其所需要的内存段的最小数目,但是NetworkBufferPool并没有将这些内存段实例分配给它,也就是说不是预先静态分配的,而是调用方调用requestBuffer方法(来自BufferProvider接口),在内部触发对NetworkBufferPool的实例方法requestMemorySegment的调用进而获取到内存段。我们来看一下requestBuffer方法的实现:
private Buffer requestBuffer(boolean isBlocking) throws InterruptedException, IOException {
synchronized (availableMemorySegments) {
//在请求之前,可能需要先返还多余的,也就是超出currentPoolSize的内存段给NetworkBufferPool
returnExcessMemorySegments();
boolean askToRecycle = owner != null;
//当可用内存段队列为空时,说明已没有空闲的内存段,则可能需要从NetworkBufferPool获取
while (availableMemorySegments.isEmpty()) {
if (isDestroyed) {
throw new IllegalStateException("Buffer pool is destroyed.");
}
//获取的条件是:所请求的总内存段的数目小于当前池大小
if (numberOfRequestedMemorySegments < currentPoolSize) {
//请求一个内存段
final MemorySegment segment = networkBufferPool.requestMemorySegment();
if (segment != null) {
//所请求的内存段总数目加一,并将请求的内存段加入到可用内存段队列中,然后跳出本轮while循环
//注意这里是continue而不是break,这里还必须继续判断队列中是否有元素可用,
//因为当前对象可能处于分布式的场景下
numberOfRequestedMemorySegments++;
availableMemorySegments.add(segment);
continue;
}
}
//如果总内存段的数目已大于等于本地缓冲池大小,判断是否需要释放,如果需要,让缓冲区池归属者释放一个内存段
if (askToRecycle) {
owner.releaseMemory(1);
}
//如果是阻塞式的请求模式,则对当前队列阻塞等待两秒钟,接着仍然继续while循环
if (isBlocking) {
availableMemorySegments.wait(2000);
} else {
//否则,直接返回空并退出循环
return null;
}
}
//当有可用内存段时,直接从队列中获取内存段并新建一个Buffer实例
return new Buffer(availableMemorySegments.poll(), this);
}
}
在上文我们介绍过,在NetworkBufferPool中创建或者销毁BufferPool时,所有非固定大小的BufferPool会被重分布。在分析其实现是,我们看到了它会调用LocalBufferPool的实例方法setNumBuffers,该方法会调整本地缓冲池的大小,并可能会对其所申请的内存段数目产生影响:
public void setNumBuffers(int numBuffers) throws IOException {
synchronized (availableMemorySegments) {
//重分布后新的Buffer数量不得小于最小要求的内存段数量
checkArgument(numBuffers >= numberOfRequiredMemorySegments,
"Buffer pool needs at least " + numberOfRequiredMemorySegments +
" buffers, but tried to set to " + numBuffers + ".");
//修改缓冲池容量
currentPoolSize = numBuffers;
//如果当前保有的内存段数目大于新的缓冲池容量,则将超出部分归还
//注意这里归还并不是精确强制归还的,当本地缓冲池中没有多余的内存段时,归还动作将会终止
returnExcessMemorySegments();
//这是第二重保险,如果Buffer存在归属者且此时本地缓冲区池中保有的内存段仍然大于缓冲池容量
//则会对多余的内存段进行释放
if (owner != null && numberOfRequestedMemorySegments > currentPoolSize) {
owner.releaseMemory(numberOfRequestedMemorySegments - numBuffers);
}
}
}
Buffer是数据交换的载体,在所有涉及到数据交换的地方都会用到它。因此理解其相关的实现对于,理解Flink的整个数据流交换体系非常有帮助。
事件
Flink的数据流中不仅仅只有用户的数据,还包含了一些特殊的事件,这些事件都是由算子注入到数据流中的。它们在每个流分区里伴随着其他的数据元素而被有序地分发。接收到这些事件的算子会对这些事件给出响应,典型的事件类型有:
- 检查点屏障:用于隔离多个检查点之间的数据,保障快照数据的一致性;
- 迭代屏障:标识流分区已到达了一个超级步的结尾;
- 子分区数据结束标记:当消费任务获取到该事件时,表示其所消费的对应的分区中的数据已被全部消费完成;
事件假设一个流分区维持着元素顺序。鉴于此,在Flink中一元算子在消费单一流分区时,能够保证FIFO(先进先出)的元素顺序。而为了保证流处理的速率同时避免反压,算子有时会接收超过一个流分区的元素并将它们合并。综合各种场景,Flink中的数据流在任何形式的重分区或广播之后不提供顺序保证。而对无序元素的处理任务交给算子自行实现。
在Flink中所有事件的最终基类都是AbstractEvent。AbstractEvent这一抽象类又派生出另一个抽象类RuntimeEvent,几乎所有预先内置的事件都直接派生于此。除了预定义的事件外,Flink还支持自定义的扩展事件,所有自定义的事件都继承自派生于AbstractEvent的TaskEvent。总结一下,其类继承关系图如下:
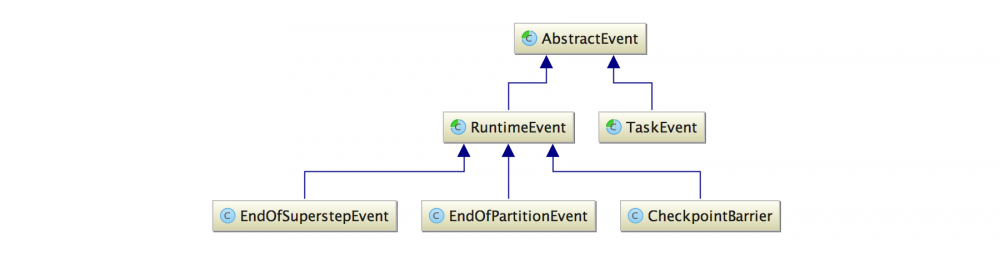
上图中继承自RuntimeEvent的三个事件类就是上文列举的典型事件。其中只有CheckpointBarrier包含检查点编号和时间戳这两个属性,其他两个事件类主要起到标识作用。
微信扫码关注公众号:Apache_Flink

QQ扫码关注QQ群:Apache Flink学习交流群(123414680)
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

