在线支付公司Stripe的服务发现架构设计过程分享
本文翻译自: Service discovery at Stripe ,原作者为 Julia Evans ,翻译已获得原网站授权。
每一年,各种新技术都会如雨后春笋般不断地冒出来,就像 Kubernetes 和 Habitat 那样,所以在兴奋之余我们常常会在内心中感到不安,因为我们一直默不作声地用各种技术来支撑着我们的生产系统,却没有向它们表示敬意。在我们Stripe有一个这样的用了好几年的工具就是 Consul 。Consul帮我们实现了服务发现功能(也就是说,在我们的几千台服务器上运行了各种各样的服务,它帮我们路由,并且告诉我们哪些服务在运行着,并且可用)。这种实用有效的架构选择并非一时的心血来潮或赶时髦,它非常忠实地完成了我们的使命,帮我们为遍布世界各地的用户提供了可靠的服务。
接下来我们会谈到:
- 服务发现和Consul是什么;
- 我们是怎样管理部署关键软件的风险的;
- 我们常常遇到的挑战,以及我们是怎样应对的;
你并不会只是把新的软件搭起来,然后就希望它可以像变魔术一样开始工作,并且解决掉你的所有问题——使用新软件是一个过程。下面的例子就表明了在生产环境中,使用新软件的过程对我们来说像怎么一回事。
(点击放大图像)
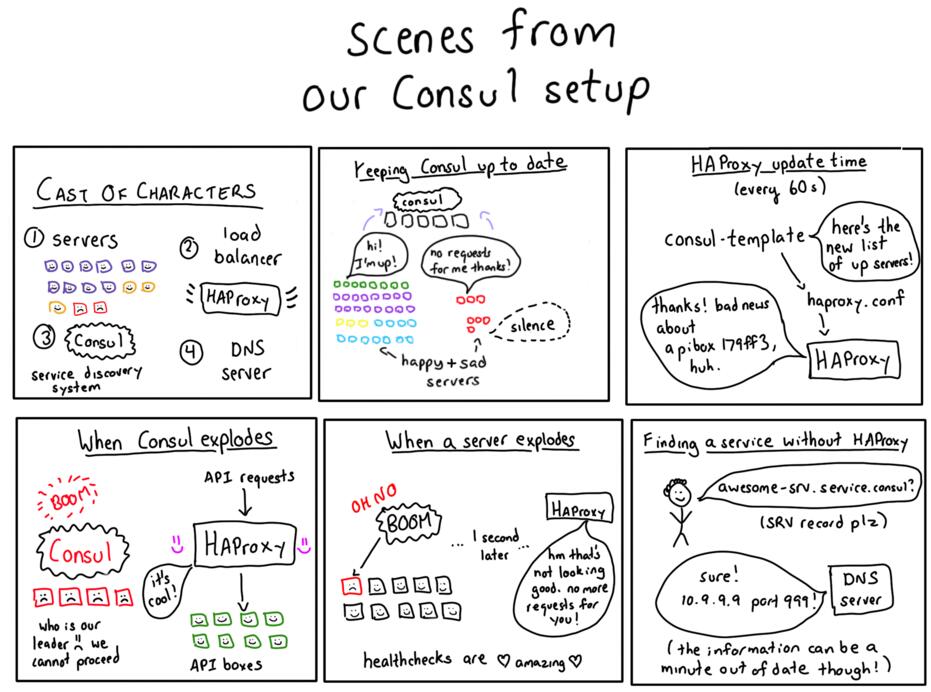
什么是服务发现?
好问题!假设你是Stripe的一个负载均衡器,现在来了一个请求要创建一个帐单记录。你想把它发往一台API服务器,任何一台API服务器都有可能!
我们运行了几千台服务器,在其之上运行了各种各样的服务。哪些是API服务器呢?那些API运行在哪些端口上呢?使用AWS的一个非常令人吃惊的特点就是,我们的实例可能在任何时候宕机,所以我们必须要准备好应对下面这些情况:
- API服务器任何时候都可能会丢失不见了;
- 在需要更大的容量时,就添加更多的服务器;
这种不断检查地各台服务器的可用状态变化的过程就叫服务发现。我们用了 HashCorp 的一个名为Consul的工具来做服务发现。
我们的实例可能在任何时候宕机这件事,事实上是非常有用的——从实际运行情况来看,我们的基础设施中经常会有实例宕机,而我们也能自动处理,所以当发生这样的事时,对我们来说不过是非常正常的例行公事。如果经常发生故障,那就更容易非常优雅地处理故障。
介绍Consul
Consul是一个服务发现工具:它让服务自己过来注册,并且可以发现其它的服务。它把那些可用的服务保存在数据库中,并且有客户端软件可以将这样的信息保存在那个数据库中,这样其它的客户端软件就可以从数据库中读取信息了。在这里还有很多细节需要仔细考虑。
对Consul来说最重要的模块就是数据库。数据库里的记录是像这样的:“API服务运行在IP 10.99.99.99的12345端口上。它现在正在运行。”
每台服务器都会向Consul发布信息,内容类似这样:“嗨!我这里的12345端口运行着API服务!现在的状态是运行中!”
然后如果你需要和API服务进行交互,你就可以直接问Consul:“哪里有API服务可用?”它就会给你返回一系列的IP地址和端口,然后你就可以访问了。
Consul本身是一套分布式系统(记住:我们有可能在任意时刻宕掉某台服务器,这就意味着我们的Consul服务器自身也可能会宕掉),所以它用了名为Raft的一致性算法来保证数据库中的数据是同步的。
如果你对Consul内部的一致性问题感兴趣,可以在 这里 读到更进一步的内容。
在Stripe刚开始用Consul的时候
我们最初只向Consul写数据——让各台服务器自己向Consul服务器报告它们是不是在正常运行,但并没有用那些信息去做服务发现。我们写了一些 Puppet 配置来把它搭起来,这事并不困难。
这样我们就可以通过运行Consul客户端来发现潜在的问题,并且得到在几千台服务器上运行它的经验了。一开始,用Consul压根发现不了服务。
是哪里出问题了呢?
解决内存泄露问题
如果你往你的基础设施中的每一台服务器上都增加一个新软件,那么那个软件肯定会出问题!最早的时候我们就发现了Consul的统计库里的内存泄露问题:我们发现有一台服务器用了超过100MB的内存,并且数字还在不断变大。那是Consul的一个漏洞,后来被 修复 了。
100MB的内存泄露得并不算多,但是泄露的量却增长得很快。内存泄露问题通常都是令人担忧的,因为这是让一个进程把一台服务器的运行环境完全破坏掉的最容易的办法,这样别的进程就都无法运行了。
好在最开始的时候我们没有用Consul来做服务发现。我们只把它部署在了一部分生产服务器上,并且在监控着内存使用量,所以我们可以很快地发现潜在的严重问题,没有产生什么负面影响。
开始用Consul发现服务
当我们很有信心Consul运行在我们的基础设施中可以工作得很好的时候,我们就开始让一些客户端与Consul交互了!为了降低风险,我们做了这两方面的努力:
- 开始时只把Consul用在少数几个地方;
- 时刻保留着一套后备系统,这样万一出现故障我们还可以继续提供服务;
我们碰到了下面的几个问题。我们把它们列在这里并不是在抱怨Consul做得不够好,而是在强调当你使用一项新技术时,最重要的事就是要慢慢地扩大规模,一定要非常小心。
非常多的Raft故障切换:还记得Consul使用了一致性协议吗?它用一致性协议来把Consul集群中一台服务器上的所有数据复制到其它服务器上去。主服务器的磁盘IO能力非常有问题,磁盘不够快,没办法像Consul希望的那样把数据读出来,这样整台主服务器都会失去响应。然后Raft就会认为:“啊,主服务器宕机了!”然后再去选举出一个新主,这样的事就一遍一遍地发生。当Consul忙于选举新主时,它会拒绝掉所有对数据库的读或写请求(因为一致性读是默认要求)。
0.3版的SSL功能是有问题的:为了让Consul节点之间可以安全地通信,我们启用了Consul的SSL功能(技术上叫TLS)。有一个Consul的发行版这个功能是有问题的。我们打了 补丁 。这个例子说明有一类问题是很容易发现,并且不用害怕的(我们在QA测试中发现SSL出了问题,于是没有部署这个版本),但这样的事情对于早期阶段的软件也是很寻常的。
Goroutine泄露:我们开始时用了Consul的 主选举 功能,可是有个Goroutine泄露问题,使得Consul会快速消耗掉服务器上的所有内存。Consul团队在处理这个问题时帮了很大的忙,我们解决了许多内存泄露问题(和以前的内存泄露不同)。
当所有这些问题都解决掉之后,我们就处于非常有利的位置了。从“第一次使用Consul客户端”到“我们已经解决了生产环境里的所有这些问题”,这大概花了我们不到一年的时间。
将Consul大规模部署,用于发现哪些服务是可用的
现在我们已经了解了Consul的一些漏洞,并且修复了,那所有东西就都可以运作得更好了。还记得我们在最开始时说到的步骤吗?你问Consul:“喂,有哪些服务器是提供API服务的?”当时我们总是断断续续地碰上一些问题,Consul服务器有时候会响应慢,有时候压根没响应。
在出现Raft故障切换或者不稳定时,这种情况就非常常见,因为Consul用的是一个强一致性的数据库,所以相比于一致性弱一些的数据库,它的可用性就相对差一些。在早期,这个问题非常突出。
我们还有后备方案,但Consul停止服务总会给我们造成很大麻烦。当Consul服务出故障后,我们就不得不回退,使用一些固定的DNS名字。在最初推广Consul时这种方案还可以,但随着规模地扩大和Consul的使用日益广泛,这种方案就变得越来越不灵活。
用Consul Template来救急
通过Consul的HTTP API来向Consul询问哪些服务是可用的,这样做并不可靠。但不管怎样,有它我们还是很高兴。
我们希望可以不用API就从Consul之中查出服务的可用信息,该怎么做呢?
Consul主要就是输入一个名字(比如叫monkey-srv),然后把它翻译成一个或多个IP地址(“这里有monkey-srv”)。还记得有什么别的东西也是输入名字,然后输出IP地址的吗?DNS服务器!于是我们就用一台DNS服务器来替换了Consul。具体是这么做的:用Consul Template,这是一个Go程序,可以根据你的Consul数据库里的内容来生成静态配置文件。
于是我们就开始用 Consul Template 来为Consul服务生成DNS记录。比如如果moneky-srv运行在IP 10.99.99.99上,我们就会生成这样一条DNS记录:
monkey-srv.service.consul IN A 10.99.99.99
代码中看起来像是这样。你也可以看看我们的 真正的 Consul Template配置,那个会更复杂一些。
{{range service $service.Name}}
{{$service.Name}}.service.consul. IN A {{.Address}}
{{end}}
可能你在想:“等等!DNS记录中只有IP地址,你还需要知道这个服务在侦听着这台服务器的哪个端口。”是的,你说对了。DNS A记录是大家最常见到的一种,里面只有IP地址。但是,DNS SRV记录中就包含了端口信息,我们正是用Consul Template来生成SRV记录的。
我们为Consul Template配置了定时任务,每60秒钟运行一次。Consul Template的默认模式是“观察”模式,每当数据库中的内容有更新时,它就会不断地更新配置文件。可是当我们试用观察模式时,它的运行效果就像是对我们的Consul服务器发起了DOS攻击,于是我们就不再用它了。
所以如果我们的Consul服务器宕机了,那我们的内部DNS服务器仍然是有着全部记录的。可能数据会有些旧,但关系不大。更棒的是我们的DNS服务器并不是什么精巧的分布式系统,也就是说它只是一个简单的程序,所以不大可能会自己出故障。那么,我就可以简单地直接查询monkey-srv.service.consul来获得一个IP,然后再用它去直接与我的服务交互了。
因为DNS是一种无共享最终一致性系统,所以我们可以复制,并一批一起做缓存。我们有五台主要的DNS服务器,每台服务器都有一个本地的DNS缓存,并且缓存知道该如何与这五台DNS服务器中的任意一台交互。所以它的确会比Consul更有弹性。
为了更快的健康检测而增加一个负载均衡器
我们刚提到了每60秒钟会用Consul的数据更新一次DNS记录。那么,万一某台API服务器宕机了怎么办?我们会不断地向那个IP发送请求,直到45秒或更长的时间之后,DNS服务器中的数据更新了才停止吗?不会的!这里就涉及到了另一项技术: HAProxy 。
HAProxy是一个负载均衡器。如果你对请求发向的服务做健康检测,那就可以确保你的后端是可以提供服务的!事实上我们所有的API请求都会经过HAProxy。它具体是这么工作的:
- 每60秒钟,Consul Template写一个HAProxy配置文件。
- 这意味着HAProxy对后端的状态数据总是大概正确的。
- 如果某台服务器宕机了,那HAProxy马上会就发现有些东西出问题了(因为它每2秒做一次健康检测)。
这意味着我们每60秒钟会重启HAProxy一次。那我们重启HAProxy时会把所有现有连接都断掉吗?不会的。为了避免因重启而断掉连接,我们使用了 HAProxy的优雅重启功能 。当然重启的过程中处理量会有所下降( 在这里有所描述 ),但我们不觉得这是个大问题。
我们的每个服务都有标准的健康检测节点——差不多每个服务都有个/healthcheck节点,正常情况下会返回200,否则就表示出错。标准化很重要,因为这样我们就可以轻松地配置HAProxy来检测服务的健康状态了。
假如Consul不能提供服务了,HAProxy就会一直使用一份过期的配置文件,这样也能继续提供服务。
牺牲一致性,换取可用性
如果你观察得足够仔细,你会发现我们最初用的系统(一个强一致的数据库,可以保证里面存储着最新的状态)与我们最终的系统(一台DNS服务器,数据可能会有一分钟的延迟)相比,两者有很大的不同。我们放弃了对一致性的追求,因此获得了一套可用性更高的系统:Consul的故障基本上不会对我们的服务发现功能造成任何影响。
从这里可以学到的很重要的一点就是,一致性不是那么容易达到的!你将不得不付出可用性的代价,而且如果你决定使用一套强一致性的系统,那请一定保证那的确是你需要的东西。
当你发出一个请求时会发生什么
我们在这篇博客中包含了许多内容,所以现在让我们跟踪一遍请求的处理流程,看看我们刚才了解的东西都是怎么工作的。
当你请求 https://stripe.com/ 的时候,会发生什么?它最终会不会被正确的服务器处理?下面是一点简单的解释。
- 请求到达一台对外开放的公共负载均衡器,上面运行着HAProxy;
- Consul Template已经将所有可以处理stripe.com的服务器生成了一个列表,保存在配置文件/etc/haproxy.conf中;
- HAProxy每60秒钟重新读一次配置文件的内容;
- HAProxy把你的请求发送到一台stripe.com服务器上!它知道这台服务器是在提供服务的。
事实上的流程是比上面描述的更复杂一些的,因为本来还会多一层中间层,而且Stripe的API请求也更复杂,因为我们还有系统要处理PCI合规性问题。但所有的核心内容都在上面了。
这意味着当我们启动或关闭服务器时,Consul会自动处理好相应的记录,完全不需要手工介入。
一年多的平静
在我们服务发现功能的实现中,还有很多地方是我们想要改进的。这是一片开发活动非常活跃的天地,我们已经看到在不久的将来,我们可以非常优雅地将调度和请求路由系统整合起来。
不过,我们得到的最大收获之一,就是简单的方法往往是最有效的。这套系统已经非常可靠地为我们服务了超过一年了,没有出过任何差错。Stripe的请求处理量远不及Twitter或Facebook,但我们还是对可靠性有着非常极致的追求。有时候最大的成功就是部署了一套稳定的、优秀的解决方案,而不是什么新奇的东西。
对Stripe公司有兴趣的朋友可以在这里了解技术团队的 需求 。
感谢郭蕾对本文的审校。
给InfoQ中文站投稿或者参与内容翻译工作,请邮件至editors@cn.infoq.com。也欢迎大家通过新浪微博(@InfoQ,@丁晓昀),微信(微信号: InfoQChina )关注我们。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

