微软研究院大咖张正友:什么是人脸表情识别技术?
作者: 大牛讲堂
人脸表情识别(FER)作为 智能 化人机交互技术中的一个重要组成部分,近年来得到了广泛的关注,涌现出许多新方法。人脸表情识别(FER)系统由 人脸检测 、 表情特征提取 和 表情分类 组成。
地平线《大牛讲堂》有幸请到了世界著名计算机视觉和多媒体技术专家,微软研究院视觉技术组高级研究员张正友博士,来与大家分享“基于几何与Gabor小波的多层感知表情识别”和“基于特征的识别”两项面部表情识别技术。
一、基于特征的面部表情识别
张正友博士分享了两种人脸特征识别方法: 置信点集的几何位置 和这些点的 多尺度多方向Gabor小波系数 ,二者既可以独立使用也可以结合使用。张正友博士的研究结果表明, Gabor小波系数更为有效 。由于第一层网络的作用是非线性降维,张正友博士还研究了隐含单元(Hidden Units)的数量,也就是面部表情特征表示的维数,得出5-10维足以表达特征空间的结果。之后,分析了每个置信点对表情表示的重要性,其敏感度分析表明,脸颊和前额上的点包含的有用信息很少,舍去之后,不仅计算效率会提升,性能也略有提升。最后,张正友博士研究了图像尺度的重要性,实验表明表情主要是低频过程,空间分辨率64×64就足够了。
1.1 面部表情识别(FER)的难点
①不同的人表情变化;②同一人上下文变化。
1.2 自动FER系统需要解决
①面部检测与定位,②人脸特征提取和表情识别。
定位问题前人已经做得很好,这里不讨论。
人脸特征提取是为了找到人脸最合适的表示方式,从而便于识别。主要有两种方式:整体模版匹配系统和基于几何特征的系统。在整体系统,模板可以是像素点或是向量。在几何特征系统中,广泛采用主成份分析和多层 神经网络 来获取人脸的低维表示,并在图片中检测到主要的特征点和主要部分。通过特征点的距离和主要部分的相对尺寸得到特征向量。基于特征的方法比基于模板的方法计算量更大,但是对尺度、大小、头部方向、面部位置不敏感。
①首先定位一系列特征点:
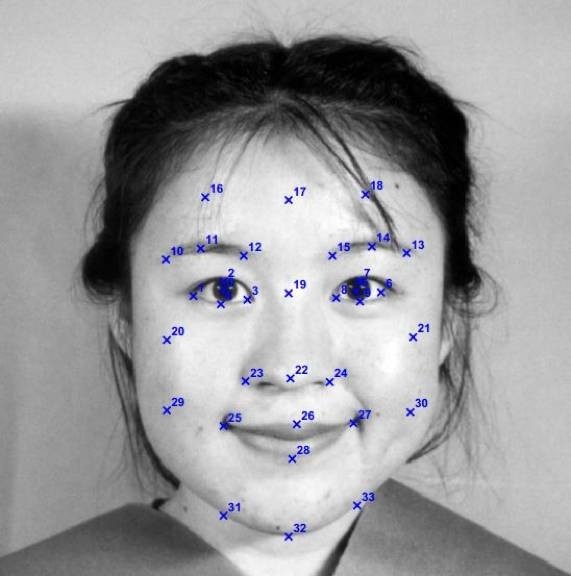
②再通过图像卷积抽取特征点的Gabor小波系数,以Gabor特征的匹配距离作为相似度的度量标准。在特征点:
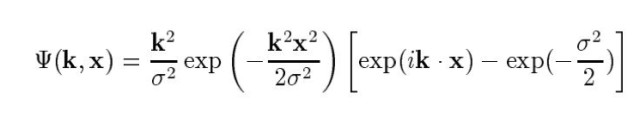
③提取特征之后,表情识别就成为了一个传统的分类问题。可以通过多层神经网络来解决:
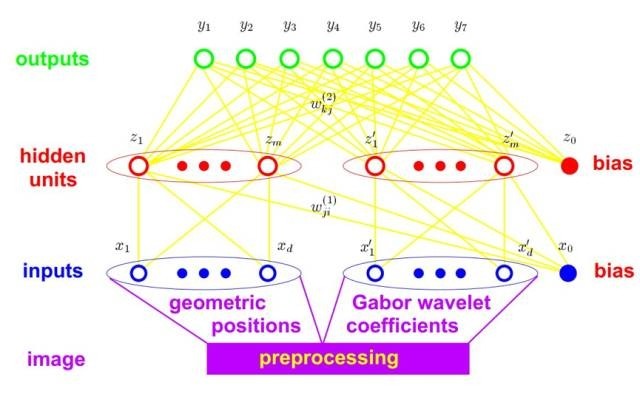
准则是最小化交叉熵(Cross-entropy):
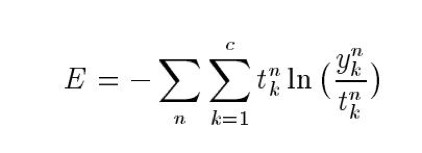
t是label,y是实际输出。
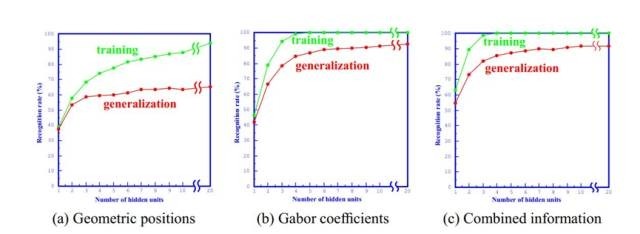
1.3 实验结果
从结果看,Gabor方法优于几何方法,二者结合效果更佳 
可以看到,隐含层单元达到5-7个时,识别率已经趋于稳定,那就是说5-7个单元已经足够了。
二、静态表情图像的多层深度网络学习
2015EmotiW的表情识别方法,基于 卷积神经网络 (convolutional neural networks (CNN))。卷积神经网络(CNN)是一种前馈神经网络,它的人工神经元可以响应一部分覆盖范围内的周围单元,对于大型图像处理有出色表现。卷积神经网络由一个或多个卷积层和顶端的全连通层(对应经典的神经网络)组成,同时也包括关联权重和池化层(pooling layer)。这一结构使得卷积神经网络能够利用输入数据的二维结构。与其他深度学习结构相比,卷积神经网络在图像和 语音识别 方面能够给出更优的结果。这一模型也可以使用反向传播算法进行训练。相比较其他深度、前馈神经网络,卷积神经网络需要估计的参数更少,使之成为一种颇具吸引力的深度学习结构。
2015EmotiW的表情识别方法,针对7种基本情感,其中包括一个 人脸检测模块 (基于三个性能很好(state-of-art)的人脸检测模块)。每个模型都是随机初始化并在Facial Expression Recognition (FER) Chal-lenge 2013 上预训练的,之后在SFEW 2.0训练集上进行细调。为了结合多个CNN模型,张正友博士提出了联众学习权重的策略:1、最小化对数似然损失(log like-lihood loss);2、最小化合页损失(hinge loss) 。
2.1人脸 检测(定位)
由三部分构成:1. 联合级联检测与校准(the joint cascade detection and alignment (JDA) detector);2.基于深度卷积神经网络(DCNN);3.混合树(Mot)。
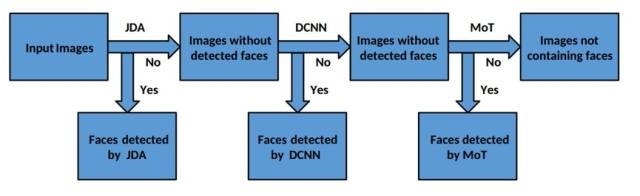
2.2 人脸图像处理
有助于去掉无关噪声,统一人脸大小,从而使识别更准确。首先转化为48×48的灰度图。然后标准直方图均衡化,接着去除不平衡光照。最后,化为0均值,单位方差的向量。
2.3 网络模型
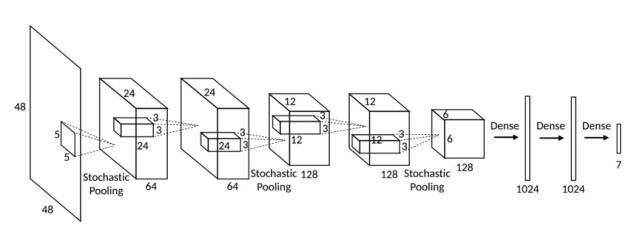
基本网络模型
包括5个卷基层,3个随机pooling层(非max pooling层)。随机pooling是根据归一化输出的分布得到的概率分布从而随机选择像素点。全连接层包含dropout,随机机制减小了过拟合(over-fitting)的风险。
输入是处理好的48×48人脸图像。第二、三曾是随机pooling层,在pooling前有两个卷基层。卷基层和全连接层的激活函数都是ReLU。最后阶段包括softmax层,之后是负对数似然损失:
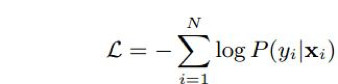
网络图如下:
加入随机扰动
加入随机扰动可以增加对脸部偏移和旋转的鲁棒性。通过如下随机仿射扭曲图像:
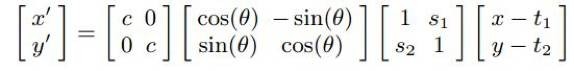
扰动下learning与voting
由于带有扰动,损失函数应当包含所有扰动的情况:
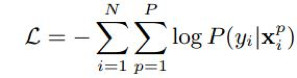
P是扰动种类个数。每个测试图像的响应是所有对应扰动图像响应的average voting。
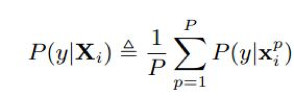
2.4 多网络学习
在CNN模型的顶端,放置一个 多网络(Multiple Network)增强性能 。典型的就是对输出求均值。观察表明,随机初始化不仅导致网络参数变化,同时使得不同网络对不同数据的分类能力产生差别。因此,平均权重可能是次最优的因为voting没有变化。更好的方法是对每个网络适应地分配权重,使得整体网络互补。
为了学习权重w,先独立地训练不同初始化的CNN。在权重上轻易损失函数。考虑如下两种优化框架:
最优整体对数似然损失
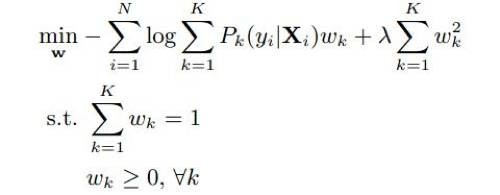
最优整体合页损失
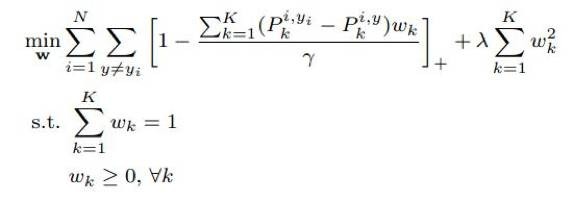
雷锋网注:本文由大牛讲堂授权发布雷锋网(公众号:雷锋网),如需转载请联系原作者,并注明作者和出处,不得删减内容。有兴趣可以关注公号【地平线机器人技术】,了解最新消息。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

