TiDB 增加 MySQL 内建函数
本文档用于描述如何为 TiDB 新增 builtin 函数。首先介绍一些必需的背景知识,然后介绍增加builtin 函数的流程,最后会以一个函数作为示例。
背景知识
SQL 语句在 TiDB 中是如何执行的。 SQL 语句首先会经过 parser,从文本 parse 成为 AST(抽象语法树),通过 optimizer 生成执行计划,得到一个可以执行的 plan,通过执行这个 plan 即可得到结果,这期间会涉及到如何获取 table 中的数据,如何对数据进行过滤、计算、排序、聚合、滤重等操作。对于一个 builtin 函数,比较重要的是 parse 和如何求值。这里着重说这两部分。
Parse:
TiDB 语法解析的代码在 parser 目录下,主要涉及 misc.go 和 parser.y 两个文件。在 TiDB 项目中运行 make parser 会通过 goyacc 将 parser.y 其转换为 parser.go 代码文件。转换后的 go 代码,可以被其他的 go 代码调用,执行 parse 操作。
将 sql 语句从文本 parse 成结构化的过程中,首先是通过 Scanner,将文本切分为 tokens,每个 tokens 会有 name 和 value,其中 name 在 parser 中用于匹配预定义的规则(parser.y),匹配规则时,不断的从 Scanner 中获取 token,当能完整匹配上一条规则时,会将匹配上的 tokens 替换为一个新的变量。同时,在每条规则匹配成功后,可以用 tokens 的 value,构造 ast 中的节点或者是 subtree。对于 builtin 函数来说,一般的形式为 name(args),scanner 中要识别 function 的 name,括号,参数等元素,parser 中匹配预定义的规则,构造出一个 ast 的 node,这个 node 中包含函数参数、函数求值的方法,用于后续的求值。
求值:
求值过程是根据输入的参数,以及运行时环境,求出函数或者表达式的值。求值的控制逻辑 evaluator/evaluator.go 中。对于大部分 builtin 函数,在 parse 过程中被解析为 FuncCallExpr,求值时首先将 ast.FuncCallExpr 转换成 expression.ScalarFunction,这时会调用 NewFunction() 方法 (expression/scalar_function.go),通过 FnName 在 builtin.Funcs 表(evaluator/builtin.go)中找到对应的函数实现,最后在对 ScalarFunction 求值时会调用求值函数。
整体流程
-
修改 parser/misc.go 以及 parser/parser.y
-
在 misc.go 的 tokenMap 中添加规则,将函数名解析为 token
-
在 parser.y 中增加规则,将 token 序列转换成 ast 的 node
-
在 parser_test.go 中,增加 parser 的单元测试
-
make
-
在 evaluator 包中的求值函数
-
在 evaluator/builtin_xx.go 中实现该函数的功能,注意这里的函数是按照类别分了几个文件,比如时间相关的函数在。函数的接口为 type BuiltinFunc func([]types.Datum, context.Context) (types.Datum, error)
-
并将其 name 和实现注册到 builtin.Funcs 中
-
写单元测试
-
在 evaluator 目录下,为函数的实现增加单元测试
示例
这里新增 timdiff() 支持的 PR 为例,进行详细说明
首先看 parser/misc.go:
在 tokenMap 中添加一个 entry
这里是定义了一个规则,当发现文本是 timediff 时,转换成一个 token,token 的名称为 timediff。SQL 对大小不敏感,tokenMap 里面统一用大写。
对于 tokenMap 这张表里面的文本,不要被当作 identifier,而是作为一个特别的 token。接下来在 parser 规则中,需要对这个 token 进行特殊处理,看 parser/parser.y:
这行的意思是从 lexer 中拿到 timediff 这个 token 后,我们给他起个名字叫 "TIMEDIFF",下面的规则匹配时,我们都使用这个名字。
这里 timediff 必须跟 tokenMap 里面 value 的 timediff 对应上,当 parser.y 生成 parser.go 的时候 timediff 会被赋予一个 int 类型的 token 编号。
由于 timediff 不是 MySQL 的关键字,我们把规则放在 FunctionCallNonKeyword 下,

这里的意思是,当 scanner 输出的 token 序列满足这种 pattern 时,我们将这些 tokens 规约为一个新的变量,叫 FunctionCallNonKeyword (通过给$$变量赋值,即可给 FunctionCallNonKeyword 赋值),也就是一个 AST 中的 node,类型为 *ast.FuncCallExpr。其成员变量 FnName 的值为 $1 的内容,也就是规则中第一个 token 的 value。
至此我们已经成功的将文本 "timediff()"转换成为一个 AST node,其成员 FnName 记录了函数名 "timediff",用于后面的求值。
如果想引用这个规则中某个 token 的值,可以用 $x 这种方式,其中 x 为 token 在规则中的位置,如上面的规则中,$1 为 "TIMEDIFF",$2 为 ’(’ , $3 为 ’)’ 。$1.(string) 的意思是引用第一个位置上的 token 的值,并断言其值为 string 类型。
函数注册在 builtin.go 中的 Funcs 表中:
参数说明如下: builtinTimediff :timediff 函数的具体实现在 builtinTimediff 这个函数中 2:这个函数最少的参数个数 2:这个函数最多的参数个数,语法 parse 过程中,会检查参数的个数是否合法
函数实现在 builtin_time.go 中,一些细节可以看下面的代码以及注释
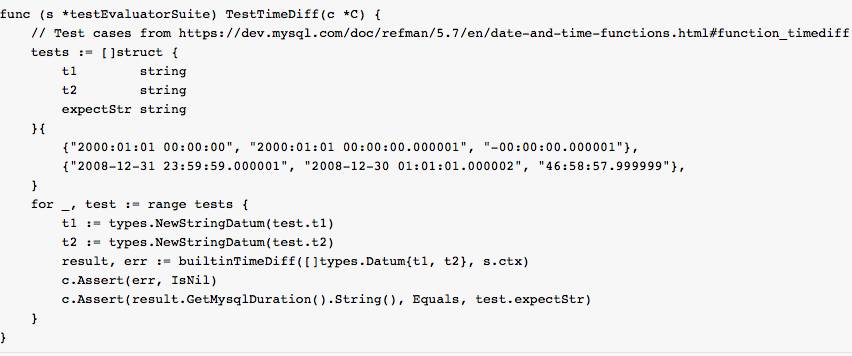
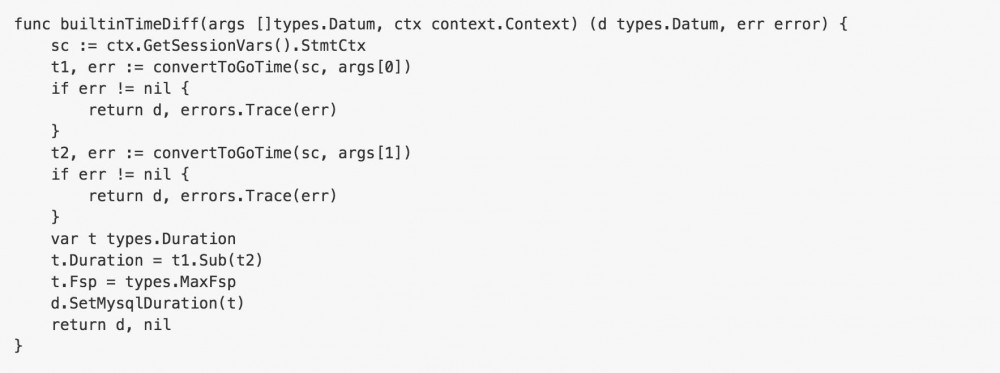 最后需要增加单元测试:
最后需要增加单元测试:

分布式 NewSQL 数据库
www.pingcap.com
 微信ID:pingcap2015
微信ID:pingcap2015
 长按左侧二维码关注
长按左侧二维码关注
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

